java pipeline并发模式
1、pipeline简介
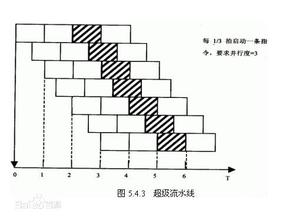
pipeline又称为管道,是一种在计算机普遍使用的技术。举个最普遍的例子,如下图所示cpu流水线,一个流水线分为4部分,每个部分可以独立工作,于是可以处理多个数据流。linux 管道也是一个常用的管道技术,其字符处理功能十分强大,在面试过程中常会被问到。在分布式处理领域,由于管道模式是数据驱动,而目前流行的Spark分布式处理平台也是数据驱动的,两者非常合拍,于是在spark的新的api里面pipeline模式得到了广泛的应用。还有java web中的struct的filter、netty的pipeline,无处不见pipeline模式。因此,本小结的目标是使用java编写一个简易的pipeline小程序,并进行相应的功能,性能 测试。
2、设计思路
我以字符串处理为例,通常对字符串的处理不会一步就完成,需要分成几部来完成,而并行的处理方式不适合于大量数据流的场景。于是本节的目的是实现一个并行字符串处理程序。设计思路如下图所示,参考了netty的管道模型。

一个管道中包含多个channelhandler、每个handler实现了具体的处理方法,每个handler都唯一对应了一个context,在pipeline中,所有的context是构成一个链式结构的,链式结构是有序的,于是context的先后顺序决定了处理的先后顺序,pipeline可以通过context来调用handler。每个handler实际上只是一个接口,需要用户去自己实现。
3、Handler接口
该接口只需要实现字符串处理,然后把结果传给下一个handler就可以了。代码入下,接口参数HandlerContext为下一个handler的context,而Object为从上一个handler处理之后传入的结果。
public interface Handler {
void channelRead(HandlerContext ctx, Object msg);
} 4、HandlerContext
HandlerContext的作用比较大,首先它是链表的一部分,因此需要有指向下一个context的指针;然后它负责调用handler,而我们要实现一个并发的处理程序,那么HandlerContext就需要维护一个线程池来供handler处理。具体代码如下
public class HandlerContext {
private ExecutorService executor= Executors.newCachedThreadPool();//线程池
private Handler handler;
private HandlerContext next;//下一个context的引用
public HandlerContext(Handler handler){
this.handler=handler;
}
public void setNext(HandlerContext ctx){
this.next=ctx;
}
public void doWork(Object msg){//执行任务的时候向线程池提交一个runnable的任务,任务中调用handler
if(next==null){
return;
}else {
executor.submit(new Runnable() {
@Override
public void run() {
handler.channelRead(next, msg);//把下一个handler的context穿个handler来实现回调
}
});
}
//handler.channelRead(next,msg);
}
public void write(Object msg){//这里的write操作是给handler调用的,实际上是一个回调方法,当handler处理完数据之后,调用一下nextcontext.write,此时就把任务传递给下一个handler了。
doWork(msg);
}
} 5、pipeline
pipeline维护了handlercontext链表,对该链表进行增删改操作,同时他对外提供了整个pipeline的调用接口。其代码如下:
public class MyPipeline {
private HandlerContext head;//链表头
private HandlerContext tail;//链表尾,如果是一个双向链表,这个成员将会被用到,netty就使用的双向链表,因为是全双工的。
public void addFirst(Handler handler){//这里仅仅实现了一个简单的插入操作,即在链表的头部出入一个handler。
HandlerContext ctx=new HandlerContext(handler);
HandlerContext tmp=head;
head=ctx;
head.setNext(tmp);
}
public MyPipeline(){
head=tail=new HeadContext(new HeadHandler());
}
public void Request(Object msg){//封装了外部调用接口
head.doWork(msg);
}
final class HeadContext extends HandlerContext{//这是一个内部类,为默认handler的context
public HeadContext(Handler handler) {
super(handler);
}
}
final class HeadHandler implements Handler{//这是一个内部类,是pipeline的默认处理handler。
@Override
public void channelRead(HandlerContext ctx, Object msg) {
String result=(String)msg+"end";
System.out.println(result);
}
}
} 6、自定义handler
下面为了测试,将自定义两个handler,分别为TestHandler1、TestHandler2,连个handler的作用为在字符串后面加上特定的后缀。其实现如下:
6.1 TestHandler1
public class TestHandler1 implements Handler{
@Override
public void channelRead(HandlerContext ctx, Object msg) {
//// TODO: 2016/11/22
try {
Thread.sleep(1000);//模拟阻塞
} catch (InterruptedException e) {
e.printStackTrace();
}
String result=(String)msg+"-handler1";//在字符串后面加特定字符串
System.out.println(result);
ctx.write(result);//写入操作,这个操作是必须的,相当于将结果传递给下一个handler
}
} 6.2 TestHandler2
public class TestHandler2 implements Handler{
@Override
public void channelRead(HandlerContext ctx, Object msg) {
//// TODO: 2016/11/22
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String result=(String)msg+"-handler2";
System.out.println(result);
ctx.write(result);
}
} 7、测试
如下所示的代码中,先定义一个pipeline,然后在pipeline中添加两个handler,然后为了测试并发性能,分别请求多次。
public class Main {
public static void main(String[] args){
MyPipeline pipeline=new MyPipeline();
pipeline.addFirst(new TestHandler2());//添加handler1
pipeline.addFirst(new TestHandler1());//添加handler2
for(int i=0;i<10;i++){//提交多个任务
pipeline.Request("hello"+i);
}
}
} 8、测试结果
测试结果可以看到,10个任务都正确执行了(在字符串后面加了两个特定字符串),由于并发执行,其输出结果并不是按照任务提交的时候的顺序输出的。经过统计,程序运行时间大约2秒,正好为模拟两个handler阻塞的时间。如果是单线程程序的话,每个请求都会阻塞2秒,10个任务就是20秒,会比我写的并行程序慢很多。
hello0-handler1
hello5-handler1
hello4-handler1
hello3-handler1
hello2-handler1
hello1-handler1
hello7-handler1
hello6-handler1
hello8-handler1
hello9-handler1
hello0-handler1-handler2
hello4-handler1-handler2
hello2-handler1-handler2
hello5-handler1-handler2
hello1-handler1-handler2
hello6-handler1-handler2
hello8-handler1-handler2
hello7-handler1-handler2
hello3-handler1-handler2
hello9-handler1-handler2 参考链接