Kylin&Druid浅析
一、kylin
- 核心思想
Apache Kylin的核心思想是利用空间换时间,它主要是通过预计算的方式将用户设定的多维立方体缓存到HBase中(目前还仅支持hbase),
同时由于Apache Kylin在查询方面制定了多种灵活的策略,进一步提高空间的利用率,使得这样的平衡策略在应用中值得采用。
kylin主要是对hive中的数据进行预计算,利用hadoop的mapreduce框架实现。
kylin的出现就是为了解决大数据系统中TB级别数据的数据分析需求,而对于关系数据库中的数据分析进行预计算可能有点不合适了。关键技术:大规模并行处理 列式存储 预计算
- 使用场景
(1) 假如你的数据存在于Hadoop的HDFS分布式文件系统中,并且你使用Hive来基于HDFS构建数据仓库系统,
并进行数据分析,但是数据量巨大,比如TB级别。
(2) 同时你的Hadoop平台也使用HBase来进行数据存储和利用HBase的行键实现数据的快速查询等应用
(3) 你的Hadoop平台的数据量逐日累增
(4) 对于数据分析的维度大概10个左右 - 相关概念
OLAP:
事实表:事实表包含业务过程中的度量值、指标或者事实,例如:销售表,它包含卖家ID,买家ID,商品ID,价格,交易时间;
查询表:查询表用于将索引关联到一系列信息,例如卖家表就是查询表,包含卖家ID到卖家名称、卖家所在城市、国家等的映射;
维度:维度用于描述事实的一个侧面,以回答用户的业务问题,例如位置,时间,产品类别等;
度量:度量是可以用来进行计算(COUNT,SUM,AVERAGE)的一种属性,例如价格就是一种度量;
Cuboid: 对于每一种维度进行度量的聚合运算,将运算结果保存为一个物化视图,称之为:Cuboid。
Cube:所有维度组合的Cuboid作为一个整体,我们称之为:Cube。所以一个Cube就是多种维度聚合度量的物化视图集。
Cube Segment:Cube数据的真正载体,映射到一个HTable表,一个构建任务构建Cube在时间范围内的实例,即一个Cube分段。
如果特定时间区间内的数据更新,可以仅刷新包含该时间分区的分段,避免更新整个Cube。
- kylin 架构
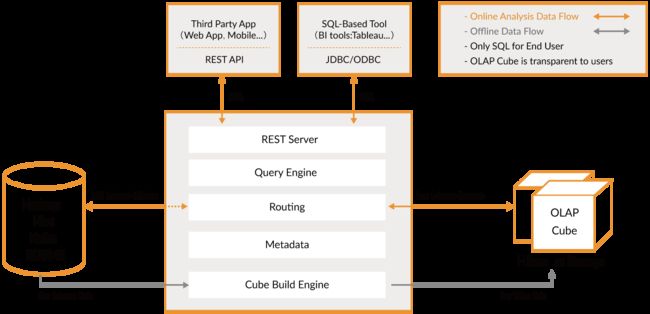
官网地址:http://kylin.apache.org/cn/
- 增量构建 & 全量构建区别
1.全量构建每次更新时都需要更新整个数据集,增量构建只对需要更新的时间范围进行更新,所以计算量会较小。 2.全量构建查询时不需要合并不同Segment,增量构建查询时需要合并不同Segment的结果,查询性能会受影响。 3.全量构建不需要对后续的Segment合并,增量构建累计一定量的Segment后需要进行合并。 4.全量构建适合小数据量或全表更新的Cube,增量构建适合大数据量的Cube。 - kylin内连接测试
0)准备数据
测试环境准备两张表:tzq.prob ,tzq.catebcreate table tzq.prob( id bigint, name string, price int, num int, pay int, cid bigint, date_time string) row format delimited fields terminated by '\t' stored as textfile; create table tzq.cateb( caid bigint, caname string) row format delimited fields terminated by '\t' stored as textfile;
分别生成测试数据,10000,1000条,以下图已丢失
1)新建model
2)新建cube
3) build cube
4) 内连接查询测试
---- Hive中查询 SQL:select * from prob a inner join cateb b on a.cid=b.caid limit 1000; Time taken: 18.21 seconds, Fetched: 1000 row(s) ---- kylin中查询 SQL:select * from tzq.prob inner join tzq.cateb on prob.cid=cateb.caid limit 1000; Start Time: 2018-04-28 16:24:47 GMT+8 Duration: 0.52s Start Time: 2018-04-28 16:31:55 GMT+8 Duration: 0.05s Start Time: 2018-04-28 16:32:45 GMT+8 Duration: 0.04s -
JDBC RESTFUL API TESTING
package com.tan.test; /** * Created by tanzhengqiang on 2018/5/2. */ import java.io.IOException; import java.io.UnsupportedEncodingException; import net.sf.json.JSONObject; import org.apache.axis.encoding.Base64; import org.apache.http.HttpEntity; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpPost; import org.apache.http.entity.StringEntity; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; public class kylinPost { private String encoding = "UTF-8"; static String ACCOUNT = "ADMIN"; static String PWD = "KYLIN"; /** * 使用httpcline 进行post访问 * @throws IOException */ public void requestByPostMethod() throws IOException{ CloseableHttpClient httpClient = this.getHttpClient(); try { //创建post方式请求对象 String url ="http://10.104.111.36:7070/kylin/api/query"; HttpPost httpPost = new HttpPost(url); //,max(a.price) as max_price,count(*) as cnt String sql = "select a.part_dt ,sum(a.price) as sum_price,count(distinct a.seller_id) as sellerid,count(*) as cnt from kylin_sales a " + " inner join kylin_cal_dt b on a.part_dt = b.cal_dt " + " inner join kylin_category_groupings c on a.lstg_site_id = c.site_id and a.leaf_categ_id = c.leaf_categ_id " + " group by a.part_dt ;"; // 接收参数json列表 (kylin 只接受json格式数据) JSONObject jsonParam = new JSONObject(); jsonParam.put("sql", sql); jsonParam.put("limit", "20"); jsonParam.put("project","learn_kylin"); StringEntity sentity = new StringEntity(jsonParam.toString(),encoding);//解决中文乱码问题 sentity.setContentEncoding(encoding); sentity.setContentType("application/json"); httpPost.setEntity(sentity); //设置header信息 //指定报文头【Content-type】、【User-Agent】 httpPost.setHeader("Content-type", "application/json;charset=utf-8"); httpPost.setHeader("Authorization", this.authCode());// System.out.println("POST 请求...." + httpPost.getURI()); //执行请求 CloseableHttpResponse httpResponse = httpClient.execute(httpPost); try{ HttpEntity entity = httpResponse.getEntity(); if (null != entity){ //按指定编码转换结果实体为String类型 String body = EntityUtils.toString(entity, encoding); JSONObject obj = JSONObject.fromObject(body); System.out.println(body); System.out.println(obj.get("results")); } } finally{ httpResponse.close(); } } catch( UnsupportedEncodingException e){ e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally{ this.closeHttpClient(httpClient); } } /** * kylin 是base64加密的,访问时候需要加上加密码 * @return */ private String authCode(){ String auth = ACCOUNT + ":" + PWD; String code = "Basic "+new String(new Base64().encode(auth.getBytes())); return code; } /** * 创建httpclient对象 * @return */ private CloseableHttpClient getHttpClient(){ return HttpClients.createDefault(); } /** * 关闭链接 * @param client * @throws IOException */ private void closeHttpClient(CloseableHttpClient client) throws IOException{ if (client != null){ client.close(); } } public static void main(String[] args) throws IOException{ kylinPost ky = new kylinPost(); ky.requestByPostMethod(); } }}
二、Apache Druid
1. Druid是什么?
Druid 是一个开源的,分布式的,列存储的,适用于实时数据分析的高容错、高性能开源分布式系统,能够快速聚合、灵活过滤、毫秒级查询、和低延迟数据导入。
2. 主要特性
Druid是一个为大型冷数据集上实时探索查询而设计的开源数据分析和存储系统,提供极具成本效益并且永远在线的实时数据摄取和任意数据处理。
- 为分析而设计——Druid是为OLAP工作流的探索性分析而构建。它支持各种filter、aggregator和查询类型,并为添加新功能提供了一个框架。用户已经利用Druid的基础设施开发了高级K查询和直方图功能。
- 交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为Druid的查询延时通过只读取和扫描有必要的元素被优化。Aggregate和 filter没有坐等结果。
- 高可用性——Druid是用来支持需要一直在线的SaaS的实现。你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
- 可伸缩——现有的Druid部署每天处理数十亿事件和TB级数据。Druid被设计成PB级别。
3. Druid使用场景,优缺点
应用场景:Druid应用最多的如广告分析、互联网广告系统监控以及网络监控等。当业务中出现以下情况时,Druid是一个很好的技术方案选择。
什么时候需要使用Druid ?
- 需要交互式聚合和快速探究大量数据时;
- 需要实时查询分析时;
- 具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加;
- 对数据尤其是大数据进行实时分析时;
- 需要一个高可用、高容错、高性能数据库时。
4. 架构图及组件介绍
查询操作中数据流和各个节点的关系如下图所示:
// 图已丢失
如下图是Druid集群的管理层架构,该图展示了相关节点和集群管理所依赖的其他组件(如负责服务发现的ZooKeeper集群)的关系
| 相关组件 |
说明 |
|---|---|
Overlord Node (Indexing Service) |
Overlord会形成一个加载批处理和实时数据到系统中的集群,同时会对存储在系统中的数据变更(也称为索引服务)做出响应。另外,还包含了Middle Manager和Peons,一个Peon负责执行单个task,而Middle Manager负责管理这些Peons。 |
Coordinator Node |
监控Historical节点组,以确保数据可用、可复制,并且在一般的“最佳”配置。它们通过从MySQL读取数据段的元数据信息,来决定哪些数据段应该在集群中被加载,使用Zookeeper来确定哪个Historical节点存在,并且创建Zookeeper条目告诉Historical节点加载和删除新数据段。 |
Historical Node |
是对“historical”数据(非实时)进行处理存储和查询的地方。Historical节点响应从Broker节点发来的查询,并将结果返回给broker节点。它们在Zookeeper的管理下提供服务,并使用Zookeeper监视信号加载或删除新数据段。 |
Broker Node |
接收来自外部客户端的查询,并将这些查询转发到Realtime和Historical节点。当Broker节点收到结果,它们将合并这些结果并将它们返回给调用者。由于了解拓扑,Broker节点使用Zookeeper来确定哪些Realtime和Historical节点的存在。 |
Real-time Node |
实时摄取数据,它们负责监听输入数据流并让其在内部的Druid系统立即获取,Realtime节点同样只响应broker节点的查询请求,返回查询结果到broker节点。旧数据会被从Realtime节点转存至Historical节点。 |
Deep Storage |
保存“冷数据”,可以使用HDFS。 |
ZooKeeper |
为集群服务发现和维持当前的数据拓扑而服务 |
MySQL |
用来维持系统服务所需的数据段的元数据 |
3. 数据存储
Druid有着自己的数据存储的逻辑和格式(主要是DataSource和Segment)
DataSource包含以下内容:
-
时间列(TimeStamp): 表明每行数据的时间值,默认使用 UTC 时间格式且精确到毫秒级别。这个列是数据聚合与范围查询的重要维度。
-
维度列(Dimension): 维度来自于OLAP的概念,用来标识数据行的各个类别信息。
-
指标列(Metric): 指标对应于OLAP概念中的Fact,是用于聚合和计算的列这些指标列通常是一些数字,计算操作通常包括 Count、Sum 和 Mean 等。
无论是实时数据消费还是批量数据处理,Druid 在基于 DataSource 结构存储数据时即可选择对任意的指标列进行聚合(Roll Up)操作。
相对于其他时序数据库,Druid 在数据存储时便可对数据进行聚合操作是其一大特点, 并且该特点使得 Druid 不仅能够节省存储空间, 而且能够提高聚合查询的效率。
DataSource 是一个逻辑概念,Segment 却是数据的实际物理存储格式,Druid 正是通过 Segment 实现了对数据的横纵向切割(Slice and Dice)操作。
从数据按时间分布的角度来看, 通过参数 segmentGranularity 的设置,Druid 将不同时间范围内的数据存储在不同的 Segment 数据块中,这便是所谓的数据横向切割。
这种设计为 Druid 带来一个显而易见的优点:
按时间范围查询数据时,仅需要访问对应时间段内的这些 Segment 数据块,而不需要进行全表数据范围查询,这使效率得到了极大的提高。
同时,在 Segment 中也面向列进行数据压缩存储,这便是所谓的数据纵向切割。而且对Segment 中的维度列使用了 Bitmap 技术对其数据的访问进行了优化。
其中,Druid会为每一维度列存储所有列值、创建字典(用来存储所有列值对应的ID)以及为每一个列值创建其bitmap索引以帮助快速定位哪些行拥有该列值。
4. Druid 单机快速构建
http://localhost:8081/#/
图已经被CSDN升级弄丢....无法补充
上传数据测试:
tandemac:druid-0.10.1 tanzhengqiang$ curl -X 'POST' -H 'Content-Type:application/json' -d @quickstart/wikiticker-index.json localhost:8090/druid/indexer/v1/task§
{"task":"index_hadoop_wikiticker_2018-04-19T12:42:19.312Z"}
查看任务上传情况:
http://localhost:8090/console.html
查询数据:
curl -L -H'Content-Type: application/json' -XPOST --data-binary @quickstart/wikiticker-top-pages.json http://localhost:8082/druid/v2/?pretty
测试提交json数据,执行结果如下:
curl -X 'POST' -H 'Content-Type:application/json' -d @quickstart/pass-index.json localhost:8090/druid/indexer/v1/task
集群部署参考:Druid:一个用于大数据实时处理的开源分布式系统
三、各不同技术选型的对比总结
大数据量下的实时多维OLAP分析场景比较:
| 技术类别 |
特点 |
|---|---|
| 技术类别 |
特点 |
| RDBMS | RDBMS能保证数据的立即一致性, 但RDBMS在可扩展性方面却表现欠佳,很难轻易和低成本的进行线性扩展以处理更大的数据量。即使可以采用分库分表等策略来容纳更多的数据,但是这种方式也存在着管理复杂和成本高昂等明显短板。 |
| MPP DataBase | 代表是Teradata、Greenplum、Vertica和Impala等。它们的优点是适合将RDBMS的应用扩展到集群范围,以处理更大的数据量,同时继承了RDBMS的很多优点。然而,它依然没法从根本上满足处理海量数据的需求,因为它的系统性能很难随集群的扩展一直线性增长,所以其集群扩展性有限;而且它的集群容错性也有限,比如当其Raid磁盘出错后可能会导致其节点响应速度变慢。 |
| ElasticSearch | ElasticSearch几乎已经是当下实时上的搜索服务器标准,而它与Logstash和Kibana的搭配(简称ELK)也是应用很广的套件组合。ElasticSearch有很强的文档索引和全文检索的能力,也支持丰富的查询功能(包括聚合查询),并且扩展性好,因此很多用户也常常在拿Elasticsearch和Druid做比较。然而,在我们的既定场景下,Elasticsearch有着其明显的短板:不支持预聚合;组合查询性能欠佳。 |
| OpenTSDB | OpenTSDB是一款优秀的时序数据库,且基于用户广泛的HBase数据库,因此有着较多的客户群。它的优势在于查询速度快、扩展性好,且schemaless。然而,它也有一些缺点:查询的维度组合数量需要提前确定好,即通过存储中的tag组合来确定,因此缺乏了灵活性;数据冗余度大;基于HBase,对于运维人员能力要求较高。 |
| Kylin | 它的优势在于项目来自于丰富的实践、发展前景光明、直接利用了成熟的Hadoop体系(HBase和Hive等)、cube模型支持较好、查询速度快速等。但它也在一些方面有着自己的局限,比如:查询的维度组合数量需要提前确定好,不适合即席查询分析;预计算量大,资源消耗多;集群依赖较多,如HBase和Hive等,属于重量级方案,因此运维成本也较高。 |
| Druid | Druid目前已经有很多公司用于实时计算和实时OLAP,而且效果很好。 缺点:配置和查询都比较复杂和繁琐,不支持SQL或类SQL接口。 解决痛点:在高并发环境下,保证海量数据查询分析性能,同时又提供海量实时数据的查询、分析与可视化功能。 |
四、参考链接
http://www.infoq.com/cn/articles/kylin-apache-in-meituan-olap-scenarios-practice
https://www.cnblogs.com/xd502djj/p/6408979.html
https://zh.hortonworks.com/open-source/druid/