Self-supervised Multi-view Person Association and Its Applications
参考文章:http://203.187.160.133:9011/www.cs.cmu.edu/c3pr90ntc0td/~ILIM/projects/IM/Association4Tracking/files/Self_supervised_Multiview_Person_Association_and_Its_Applications.pdf
【Abstract】
由于频繁的遮挡、剧烈的视角和外观变化,外表的变化以及异步视频流的影响,从多个移动相机中对复杂群体活动中的多个人进行可靠的无标记跟踪很具有挑战性。为了解决这一个问题,一种跨越遥远的视点和时间实例的关联十分必要。我们提出了一个简单但强大的自监督框架,通过利用运动跟踪、互斥约束和多视图几何,将一个通用的人的外观描述符应用到未标记的视频中。我们的描述符从WILDTRACK中学习而来,我们验证了它的有效性。我们在关联精确度上有着明显的改进(达到18%),对3D人体骨架跟踪的稳定性和连贯性的达到了相较于baseline5到10倍的改善。利用重建的三维骨架,我们将输入视频切割成多角度视频,其中特定的人的图像显示最佳可见的前置摄像头。我们的算法通过检测人之间的遮挡来确定摄像机的切换时刻,同时还能很好地保持动作的流畅性。
【1. Introduction】
追踪和重建这些事件的挑战包括:(a)大比例变化(特写和远距离拍摄);(b)人进出相机视野;(c)剧烈的观点变化,频繁的遮挡和复杂的动作;(d)衣服几乎没有特征或衣服,看起来都是一样的(校服);(e)缺乏标定和摄像机之间的同步。
提出了一种新的自监督人关联框架,该框架将连续跟踪和关联跟踪相结合,克服了二者的局限性。我们证明,即使是一个预先训练的最先进的人员外貌描述符也不足以在长时间内和跨多个视图区分不同的人。
贡献:(1)提出了一种简单而有效的基于单目运动跟踪、互斥约束和无需人工标注的多视图几何的自监督人像描述框架。(2)我们证明了通过简单的聚类,判别性外观描述符可以实现可靠的关联。这一优势使得首次能够对参与复杂群体活动的多人进行精确和一致的无标记运动跟踪,这些贡献与单视图跟踪(tracklet)或聚类算法是正交的。(3)我们介绍了三个具有标记人关联的具有挑战性的数据集,用于无标记运动捕捉。
【2. Related Work】
我们的任务与行人重识别和多视角运动跟踪有关。行人重识别专注于学习描述子,用于跨视野和时间进行匹配。近年来,该领域的发展主要由于大规模和高质量的数据集,以及强大的end-to-end训练方式。行人跟踪是一个全局图优化问题。
【3. 人的特征描述子】
我们的目标是学习一个鲁棒的外观描述符提取器ux=f(x),该提取器对于同一个人的图像提取的特征是相同的,而对于不同的人提取的特征则是不同的。提取的特征和视角的方向、姿势变形和其他因素(如照明)无关。我们的特征提取器首先在一个大规模有标签的公开行人重识别数据集上训练,然后使用孪生三元loss进行微调。微调阶段可以改善描述子对相似人群的判别性,但是这也会对很少出现在视频中的人引入较强的语义偏置。我们使用多任务学习目标来解决这个问题,并联合优化标注语料库的人类ReID数据集和未标注域视频的描述符可分辨性。我们迭代挖掘三元组,并为几个(三元组挖掘)迭代重新定义描述符。
3.1 行人外表描述子
我们首先使用CPM模型提供的关键点热图及其部分关联场来增强RGB图像。这种表示法在矫正身体部位[14]时避免了观察方向量化,并将检测置信度考虑在内,以降低可能出现的位姿检测故障的权重。
3.2 描述子适应
由于我们所用的训练集和我们在视频应用上的差异性,我们在每一个我们采集的测试视频序列中使用对比loss和triplet loss微调了f(x)。我们训练的元组中包含3张图像,包含2张来自同一个人的图像和1张另外一个人的图像。我们对CNN进行了优化,使得查询与锚之间的距离较小,查询与反例之间的距离较大。我们的损失函数定义为:

3.2.1 自动元组生成
单一视图元组
对于每一个视频,我们首相应用CPM算法检测所有的人以及他们对应的关键点。考虑到这些,我们通过探究互斥约束(一个人不能在同一个图像中出现两次)能够很容易地生成负的样本对。另外,我们可以通过短时间的跟踪生成正的样本对。我们通过组合三个跟踪器来创建运动轨迹:双向Lucas-Kanade跟踪关键点,双向Lucas-Kanade跟踪检测到的人边界框内高斯特征的差异,以及连续帧之间的人描述符匹配。当任何一个跟踪器不同意时,tracklet就会被拆分。我们还监视关键点2D轨迹的平滑度,并在瞬时2D速度大于当前平均值3倍时分割轨迹。对应于相同运动轨迹的图像构成了用于我们微调的正对。
多视图元组
我们也通过使用不同视野中的正样本对来丰富训练元组,采用多视几何方法,一个人在3D空间中必须满足极线约束。
多视图相机拍摄的时间不一样。因此,我们必须首先估计摄像机之间的时间对齐,以使用多视图几何约束。假设已经知道相机的帧率和开始时间,我们可以线性搜索临时的位移满足基础矩阵得分最高的。根据对其过程中产生的轨迹,可以产生正的样本对。
后面介绍的是如何在两个相机之间找到同一个人的跟踪轨迹。
对所有的轨迹对计算描述子的余弦距离的中值,将大于0.5的加入到候选池。使用RANSAC方法,采用极线距离评判。
基础矩阵是由背景信息或者直接由身体关键点来计算的。
3.3 多任务行人描述子学习
微调可能会提高对长相相似的人的辨别能力,但单独使用它可能会导致语义偏置,使习得的描述符对经常观察的人有强烈的偏见。
在一个相机中,很少同时出现的人的描述子不能被学习成不一样的,这是由于缺少互斥约束导致的。前面数据集中的负样本都是来自于一个相机中的轨迹。
我们通过大规模标记的行人识别训练集和特殊的场景视频联合优化行人描述子。由于该模型必须从标记的数据集中预测此人的身份,因此有望为域视频中很少见的人输出判别描述符。另一方面,由于我们在域视频上对模型进行了微调,因此与仅对其他数据集进行训练相比,它也应更好地区分那些序列中的人。联合优化的loss为:

alpha是这两个学习任务的平衡因子。

4 行人描述子学习分析
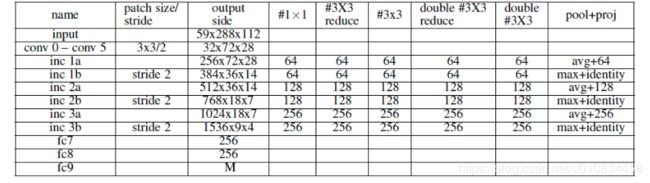
采用的用来提取特征的f(x)的CNN model具体形式如表2所示。该模型由6个卷积层,6个inception modules 和三个全连接层。
5 应用
作者使用行人描述子做了如下的应用:
1. 使用自己训练获得的行人描述子对 每幅图像中进行聚类,得到每个人在不同视频中对应的图像。
2. 通过优化一个能量函数。对每个人的骨骼关键点和肢体长度进行优化,来使不同图中的骨骼与时间能一致起来。
3. 针对某一个人,动态地从不同的视频流中选取一个具有良好成像的视频,将这些视频剪辑成一个视频。
5.1 通过聚类进行跟踪
其实直接使用行人描述子对所有的行人进行聚类,但这样计算量太大,作者没有采用这种方法。
作者采用了这么一种方法,先结合检测算法和跟踪算法生成一个个的tracklet,然后从tracklet中进行采样,从中获得一个个tracklet中的行人描述子u。
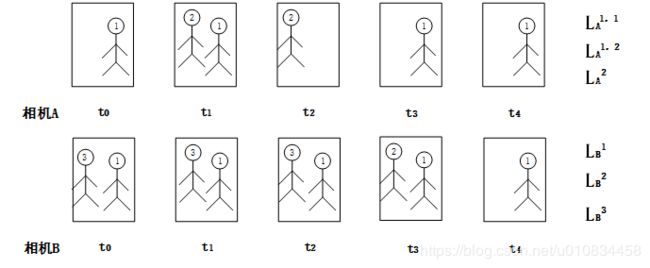
然后根据根据这些轨迹L中的行人描述子u使用m-KNN算法对轨迹进行聚类,生成连接图。

相似度:两个轨迹中,根据所有成对的人体描述子的相似性得分的中值,来确定相似度。
每个轨迹最近邻的个数:不同轨迹的距离大于相同轨迹的自相似度中值的两倍。
使用上面经过m-KNN方法产生的连接图作为初始值,将轨迹中行人描述子作为一个个节点,同一个轨迹中行人描述子会与该轨迹k近邻的轨迹中的行人描述子,相互连接,生成新的连接图。
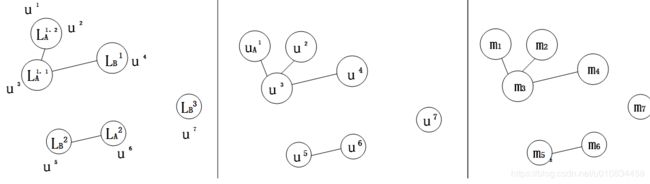
然后使用RCC进行聚类,生成新的连接图,根据生成的新的连接图进行聚类。根据聚类图可以得到不同视频流中的同一个人的tracklet,从而完成跟踪。
5.2 3D骨骼提取
从多个视频流中获得一个人的多角度视频后,可以进行三维重建,提取3D骨架。首先使用ransac和三角测量等三维重建的方式获取人体关键点的3D坐标以及肢体的长度作为初始值。然后通过优化一个能量函数


EI(K)是重投影约束,3D点投影到2D平面上的误差,优化该项可以使获取的3D坐标更加精确鲁棒。EL(K,L)用来约束肢体长度变化,尽量使肢体长度接近与平均长度。E是(K)使人的肢体尽量左右对称,EM(K)防止求解出来相邻帧的肢体尽量不要运动太快。
作者使用LM算法进行优化。
5.3 镜头剪辑
镜头剪辑的目的是从多个视频流中选中被选中的人合成一个视频流,并使被选中的人尽量在镜头的正面。作者采用一种图优化的方式。将每个相机中每一帧中的每一个人作为一个个节点,组成的图如下所示:

节点的损失计算方式如下:
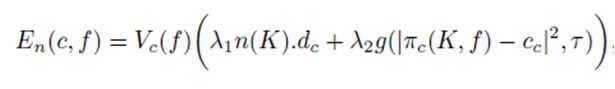
节点的损失和身体向量与相机朝向的夹角有关,与人体3D关节点投影到2D平面上距离屏幕中心的距离有关。
边的损失如下:
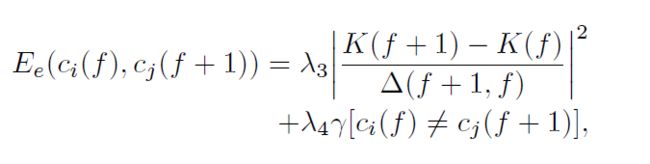
边的损失有一个固定的切换相机的损失,还有一个在运动中切换相机的损失。
使用Dijkstra最短路径算法,可以得到相机的切换。