Social GAN全文翻译
社交GAN:生成性对抗网络的社会可接受轨迹
如果自主移动平台(如自动驾驶汽车和社交机器人)要在以人为中心的环境中导航,那么理解人类运动行为是至关重要的。这是具有挑战性的,因为人体运动本质上是多模态的:考虑到人类运动路径的历史,有许多社会上可行的方式,人们可以在未来移动。我们通过结合来自序列预测和生成性对抗网络的工具来解决这个问题:循环的序列到序列模型观察运动历史并预测未来的行为,使用一种新颖的池机制来跨人聚合信息。我们通过对反复出现的鉴别器进行敌意训练来预测社会上可能的未来,并鼓励采用新颖的品种损失进行多样化的预测。通过在几个数据集上的实验,我们证明了我们的方法在准确性、多样性、冲突避免和计算复杂性方面优于先前的工作。
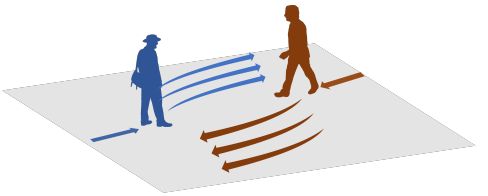
图1:两个行人想要避开对方的场景的图解。有许多可能的方法可以避免潜在的冲突。我们提出了一种方法,在给定相同的观察历史的情况下,在拥挤的场景中预测多个社会可接受的输出。
- Introduction
预测行人的运动行为对于自动驾驶汽车或社交机器人等将与人类共享同一生态系统的自动移动平台至关重要。人类可以有效地协商复杂的社会互动,而这些机器也应该能够做到这一点。为此,一项具体而重要的任务如下:给定观察到的行人运动轨迹(过去3.2秒的坐标),预测所有可能的未来轨迹(图1)。
由于拥挤场景中人体运动的固有特性,预测人类的行为具有挑战性:
- 人际关系。每个人的运动取决于他们周围的人。当在人群中导航时,人类具有天生的阅读他人行为的能力。对这些依赖关系进行联合建模是一项挑战。
- 社会接受。有些轨迹在物理上是可能的,但在社会上是不可接受的。行人受社会规范的支配,如让路或尊重个人空间。将它们形式化并不是无关紧要的。
- 多模态。考虑到部分历史,没有一个正确的未来预测。多重轨迹是合理的,也是社会接受的。
在轨迹预测方面的开创性工作已经解决了上述一些挑战。基于手工特征的传统方法已经穷尽地解决了人际关系方面的问题[2,17,41,46]。最近,基于递归神经网络(RNNs)的数据驱动技术重新审视了社会可接受性[1,28,12,4]。最后,在给定静态场景(例如,在交叉口走哪条街[28,24])的路线选择的背景下,研究了问题的多模态方面。Robicquet等人。[38]已经表明行人在给定温和或侵略性导航风格的拥挤场景中具有多种导航风格。因此,预测任务需要输出不同的可能结果。
虽然现有方法在应对具体挑战方面取得了很大进展,但它们存在两个限制。首先,在做出预测时,他们会在每个人周围建立一个本地邻里关系模型。因此,他们不具有以计算高效的方式对场景中所有人之间的交互进行建模的能力。其次,他们倾向于学习“平均行为”,因为常用的损失函数最小化了地面真相和预测输出之间的欧几里德距离。相反,我们的目标是学习多种“良好行为”,即多种社会可接受的轨迹
为了解决以前工作的局限性,我们建议利用生成模型的最近进展。生成性对抗网络(GANS)最近已经被开发出来,以克服在近似难以处理的概率计算和行为推理中的困难[14]。虽然它们已被用于产生照片级真实感信号,如图像[34],但我们建议使用它们在给定观察到的过去的情况下生成多个社会可接受的轨迹。一个网络(生成器)生成候选,另一个(鉴别器)评估它们。对抗性损失使我们的预测模型能够超越L2损失的限制,并潜在地学习可以欺骗鉴别器的“良好行为”的分布。在我们的工作中,这些行为被称为拥挤场景中社会接受的运动轨迹。
我们提出的GaN是一个RNN编解码器生成器和一个基于RNN的编码器鉴别器,具有以下两个新颖之处:
- 我们引入了一种多样性损耗,它鼓励我们的GaN的生成网络扩展其分布并覆盖可能路径的空间,同时与观察到的输入保持一致。
- 我们提出了一种新的池机制,该机制学习“全局”池向量,该矢量对场景中涉及的所有人的微妙线索进行编码。
我们将我们的模式称为“社交GAN”。通过在几个公开的真实世界人群数据集上的实验,我们展示了最先进的精确度和速度,并证明了我们的模型具有生成各种社会可接受的轨迹的能力。
- Related Work
预测人类行为的研究可以归类为学习预测人与空间的相互作用或人与人的相互作用。前者学习场景特定的运动模式[3,9,18,21,24,33,49]。后者对场景的动态内容进行建模,即行人如何彼此交互。我们工作的重点是后者:学习预测人与人的互动。我们讨论了这个主题上的现有工作以及RNN中用于序列预测和生成模型的相关工作。
人与人的互动。宏观模型中的人群视角或微观模型中的个体视角(我们工作的重点)已经对人类行为进行了研究。微观模型的一个例子是Helbing和Molnar的“社会力”[17],它用吸引力引导行人朝目标前进,而斥力则鼓励避免碰撞。在过去的几十年中,这种方法经常被重新审视[5,6,25,26,30,31,36,46]。经济学中流行的工具也被使用,例如Antonini等人的Discrete Choice框架。艾尔。[2]。Treuille et.。艾尔。[42]使用连续介质动力学和Wang等。艾尔。[44]、Tay et.。艾尔。[41]使用高斯过程。这样的函数也被用于研究固定基团[35,47]。然而,所有这些方法都使用基于相对距离和特定规则的手工制作的能量势。相反,在过去的两年中,基于RNN的数据驱动方法被用来超越上述传统方法。
用于序列预测的RNNs。递归神经网络是一类丰富的动态模型,它扩展了前馈网络在不同领域中的序列生成,如语音识别[7,8,15],机器翻译[8]和图像字幕[20,43,45,39]。然而,它们缺乏高层次和时空结构[29]。已经进行了几次尝试来使用多个网络来捕获复杂的相互作用[1,10,40]。Alahi等人。[1]使用模拟附近行人的社交池图层。在本文的其余部分中,我们表明使用多层感知器(MLP),然后使用最大池在计算上更有效,与[1]中的社会池方法一样或更好。Lee等人。[28]介绍一种使用变分自动编码器(VAE)进行轨迹预测的RNN编解码器框架。然而,他们并没有在拥挤的场景中模拟人与人的互动。
生成建模。像变分自动编码器[23]这样的生成模型是通过最大化训练数据可能性的下界来训练的。古德费罗等人。[14]提出一种替代方法,生成对抗网络(GANS),其中训练过程是生成模型和判别模型之间的极小极大博弈;这克服了近似难以处理的概率计算的困难。生成模型在诸如超分辨率[27],图像到图像转换[19]和图像合成[16,34,48]的任务中显示了有希望的结果,这些任务对于给定的输入具有多个可能的输出。然而,它们在序列生成问题(如自然语言处理)中的应用已经滞后,因为从这些生成的输出中采样以馈送到鉴别器是不可微分的操作。
- Method
人类拥有一种直观的能力,能够在考虑到周围的人的情况下,在人群中导航。我们在规划我们的路径时要记住我们的目标,同时也要考虑周围人的运动,比如他们的运动方向,速度等。然而,在这种情况下,通常存在多种可能的选择。我们需要的模型不仅能够理解这些复杂的人与人之间的相互作用,而且还能捕捉到各种选择。当前的方法集中在预测平均未来轨迹,其最小化与地面真实未来轨迹的L2距离,而我们希望预测多个“好”轨迹。在本节中,我们首先介绍了我们基于GaN的编码器-解码器架构来解决这个问题,然后我们描述了我们新颖的池层,它模拟了人与人的交互,最后我们介绍了我们的多样性损失,它鼓励网络为相同的观察序列产生多个不同的未来轨迹。
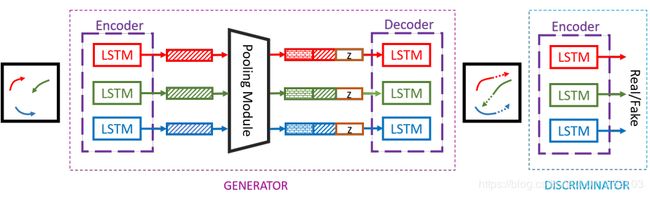
图2:系统概述。我们的模型由三个关键组件组成:生成器(G)、池模块和鉴别器(D)。G将过去的轨迹Xi作为输入,并将人i的历史编码为![]() 。池模块将所有
。池模块将所有![]() 作为输入,并输出每个人的池向量Pi。解码器生成以
作为输入,并输出每个人的池向量Pi。解码器生成以![]() 和Pi为条件的未来轨迹。D接受Treal或Tfake作为输入,并将它们分类为社会可接受或不可接受(见图3的PM)。
和Pi为条件的未来轨迹。D接受Treal或Tfake作为输入,并将它们分类为社会可接受或不可接受(见图3的PM)。
-
- Problem Definition
我们的目标是共同推理和预测场景中涉及的所有代理的未来轨迹。我们假设我们接收场景中人的所有轨迹作为输入![]() ,并预测所有人的未来轨迹
,并预测所有人的未来轨迹![]() 。人i的输入轨迹被定义为来自时间点
。人i的输入轨迹被定义为来自时间点![]() 的
的![]() 和未来的轨迹(地面真相)可以类似地定义为来自时间点
和未来的轨迹(地面真相)可以类似地定义为来自时间点![]() 的
的![]() 。我们将预测表示为
。我们将预测表示为![]() 。
。
3.2.。生成性对抗网络
生成性对抗网络(GAN)由相互对立训练的两个神经网络组成[14]。两个敌意训练的模型是:捕获数据分布的生成模型G和估计样本来自训练数据而不是G的概率的判别模型D。生成器G将潜变量z作为输入,并输出样本G(z)。鉴别器D将样本x作为输入并输出D(x),D(x)表示其为真的概率。训练过程类似于两人最小-最大博弈,具有以下目标函数:
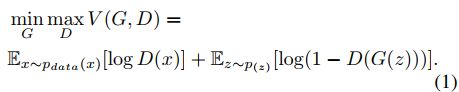
GANS可以通过向生成器和鉴别器提供额外的输入c来用于条件模型,产生G(z,c)和D(x,c)[13,32]。
3.3.。社交感知GAN
正如第1节所讨论的,轨迹预测是一个多模态问题。生成模型可以与时间序列数据一起使用,以模拟可能的未来。我们在设计sgan时利用了这种洞察力,sgan使用gans解决了问题的多模态(参见图2)。我们的模型由三个关键组件组成:生成器(G),池模块(PM)和鉴别器(D)。G基于编解码器框架,通过PM连接编码器和解码器的隐藏状态。G以输入Xi为输入,并输出预测轨迹Y^i。D输入包括输入轨迹Xi和未来预测Y^i(或yi)的整个序列,并将它们分类为“真/假”。
Generator. 我们首先使用单层MLP(多层感知器)嵌入每个人的位置,以获得固定长度的向量![]() 。这些嵌入在时间t用作编码器的LSTM单元的输入,引入以下递归:
。这些嵌入在时间t用作编码器的LSTM单元的输入,引入以下递归:
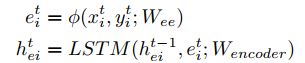
其中φ(·)是具有ReLU非线性的嵌入函数,Wee是嵌入权。LSTM权重(温编码器)在场景中的所有人之间共享。
![]() 每个人使用一个LSTM无法捕获人与人之间的交互。编码器学习一个人的状态,并存储他们的运动历史。然而,正如Alahi等人所示。[1]我们需要一种紧凑的表示,它将来自不同编码器的信息组合在一起,以有效地推理社会交互。在我们的方法中,我们通过池模块(PM)对人-人交互进行建模。在TOB之后,我们将场景中存在的所有人的隐藏状态集合起来,以获得每个人的集合张量Pi。传统上,GANS将作为输入噪声并生成样本。
每个人使用一个LSTM无法捕获人与人之间的交互。编码器学习一个人的状态,并存储他们的运动历史。然而,正如Alahi等人所示。[1]我们需要一种紧凑的表示,它将来自不同编码器的信息组合在一起,以有效地推理社会交互。在我们的方法中,我们通过池模块(PM)对人-人交互进行建模。在TOB之后,我们将场景中存在的所有人的隐藏状态集合起来,以获得每个人的集合张量Pi。传统上,GANS将作为输入噪声并生成样本。
我们的目标是产生与过去一致的未来情景。为了实现这一点,我们通过将解码器的隐藏状态初始化为:
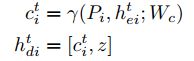
其中γ(·)是具有ReLU非线性的多层感知器(MlP),而Wc是嵌入权重。关于轨迹预测,我们在两个重要方面偏离了先前的工作:
·先前的工作[1]使用隐藏状态来预测二元高斯分布的参数。然而,这在训练过程中引入了困难,因为通过不可微的采样过程进行反向传播。我们通过直接预测坐标(^xt i;y^it)来避免这种情况。
·“社交”上下文通常作为输入提供给LSTM单元[1,28]。相反,我们只提供一次池化上下文作为解码器的输入。这也为我们提供了在特定时间点选择池的能力,与S-LSTM[1]相比,速度提高了16倍(参见表2)。
在如上所述初始化解码器状态之后,我们可以获得如下预测:

其中φ(·)是具有ReLU非线性且Wed为嵌入权的嵌入函数。LSTM权重由解码器表示,并且γ是MLP。
Discriminator. 鉴别器由单独的编码器组成。具体地说,它接受Treal=[xi,yi]或Tfake=[xi,y^i]作为输入,并将它们分类为real/fake。我们对编码器的最后一个隐藏状态应用MLP以获得分类分数。鉴别者在理想情况下将学习微妙的社会互动规则,并将社会上不能接受的轨迹归类为“假”。
Losses. 除了对抗性损失外,我们还对预测轨迹应用L2损失,以测量生成的样本与实际地面事实的距离
-
- Pooling Module
为了跨多个人联合推理,我们需要一种跨LSTM共享信息的机制。然而,有几个挑战是一个方法应该解决的:
·场景中可变的和(潜在的)大量的人。我们需要一个紧凑的表示,它结合了来自所有人的信息。
·分散的人-人交互。本地信息并不总是足够的。远方的行人可能会相互影响。因此,网络需要对全局配置进行建模。
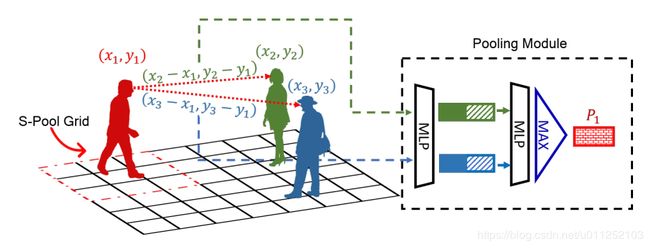
图3:红色人物的池化机制(红色虚线箭头)和社交池化[1](红色虚线网格)之间的比较。我们的方法计算红人和所有其他人之间的相对位置;这些位置与每个人的隐藏状态连接,由MLP独立处理,然后按元素汇聚计算红人的汇聚向量P1。社交池只考虑网格内的人,不能对所有对人之间的交互进行建模。
社交池[1]通过提出基于网格的池方案解决了第一个问题。然而,这个手工构建的解决方案速度很慢,并且无法捕获全局上下文。qi等人。[37]显示了上述特性可以通过将学习对称函数应用于输入点集的变换元素来实现。如图2所示,这可以通过MLP传递输入坐标,然后是对称函数(我们使用Max-pooling)来实现。集合向量Pi需要总结一个人做出决定所需的所有信息。因为我们使用相对坐标来实现平移不变性,所以我们用每个人相对于人i的相对位置来增加池模块的输入。
3.5.。鼓励多样化的样本生成
轨迹预测是具有挑战性的,因为给定有限的过去历史,模型必须对多种可能的结果进行推理。到目前为止所描述的方法产生了很好的预测,但是这些预测试图在可能有多个输出的情况下产生“平均”预测。此外,我们发现输出对噪声的变化不是很敏感,并且产生非常相似的预测。
我们提出了一个多样性损失函数,鼓励网络产生多样化的样本。对于每个场景,我们通过从N(0;1)中随机采样z并选择L2意义上的“最佳”预测作为我们的预测来生成k个可能的输出预测。
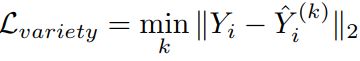
其中k是超参数
通过只考虑最佳轨迹,这种损失鼓励网络对冲其赌注,并覆盖符合过去轨迹的输出空间。这种损失在结构上类似于N(MON)损失最小[11],但据我们所知,这还没有用于GANS的上下文中,以鼓励生成样品的多样性。
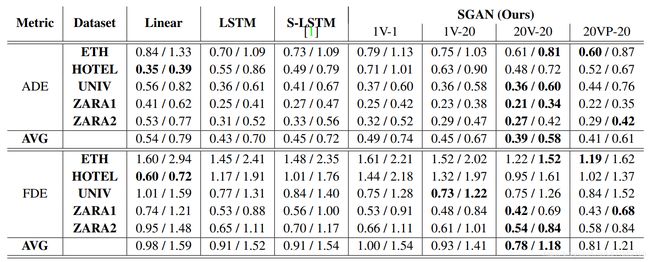
表1:数据集上所有方法的定量结果。我们报告了tpred=8和tpred=12(8/12)的两个误差度量:平均位移误差(ADE)和最终位移误差(FDE)(以米为单位)。我们的方法始终优于最先进的S-LSTM方法,尤其适用于长期预测(越低越好)。
-
- Implementation Details
在我们的解码器和编码器的模型中,我们使用LSTM作为RNN。编码器的隐藏状态的维数为16,解码器的隐藏状态的维数为32。我们将输入坐标嵌入为16维向量。我们使用初始学习率为0.001的ADAM[22]迭代训练批次大小为64的生成器和判别器,历时200个纪元。
- Experiments
在本节中,我们在两个公开可用的数据集:ETH[36]和UCY[25]上评估我们的方法。这些数据集由现实世界的人的轨迹组成,具有丰富的人与人的交互场景。我们将所有数据转换为真实世界坐标,并每隔0:4秒进行插值以获得值。总共有5组数据(ETH-2,UCY-3),具有4个不同场景,由拥挤环境中的1536名行人组成,这些场景具有挑战性的场景,如群体行为、人相互交叉、碰撞避免以及群体形成和分散
评估指标。类似于先前的工作[1,28],我们使用两个错误度量:
- 平均位移误差(ADE):在所有预测的时间步长上,地面事实和我们的预测之间的平均L2距离。
- 最终位移误差(FDE):预测周期Tpred结束时预测的最终目的地和真正的最终目的地之间的距离。
基线:我们对照以下基线进行比较:
- 线性:通过最小化最小二乘误差来估计线性参数的线性回归。
- LSTM:没有池机制的简单LSTM。
3.S-LSTM:Alahi等人提出的方法。[1]。通过LSTM对每个人进行建模,其中隐藏状态在每个时间步骤使用社交池层进行池化。
我们还在不同的控制设置下对我们的模型进行了消融研究。我们在一节中将我们的完整方法称为sgan-kvp-N,其中kV表示模型是否使用品种损失进行训练(k=1基本上意味着没有品种损失),P表示我们建议的池模块的使用。在测试时,我们从模型中多次取样,并选择L2意义上的最佳预测进行定量评估。n是指在测试时间内我们从模型中取样的次数。
评估方法。我们采用与[1]类似的评估方法。我们使用留一的方法,在4组上训练,在剩余的组上测试。我们观察8次步长(3:2秒)的轨迹,并显示8(3.2秒)和12(4.8秒)时间步长的预测结果。
4.1.。定量评估
我们对表1中不同基线的两个指标ADE和FDE的方法进行了比较。正如预期的那样,线性模型只能对直线路径进行建模,并且在较长预测的情况下尤其糟糕(tpred=12)。LSTM和S-LSTM都比线性基线表现得更好,因为它们可以建模更复杂的轨迹。然而,在我们的实验中,S-LSTM并不优于LSTM。我们尽最大努力复制论文的结果。[1]在合成数据集上训练模型,然后在真实数据集上进行微调。我们不使用合成数据来训练我们的任何模型,这可能会导致更差的性能
SGAN-1V-1的表现比LSTM差,因为每个预测的样本可能是多个可能的未来轨迹中的任何一个。该模型产生的条件输出代表了许多可能与地面真相预测不同的似是而非的未来预测之一。当我们考虑多个样本时,我们的模型优于基线方法,证实了问题的多模态性质。Gans面临模式崩溃问题,其中生成器诉诸于生成少量样本,这些样本由鉴别器分配高概率。我们发现sgan-1v-1生成的样本没有捕捉到所有可能的场景。然而,sgan-20V-20的性能明显优于所有其他型号,因为品种损失鼓励网络生产多样化的样品。尽管我们建议的池层的完整模型的性能稍差一些,但我们在下一节中显示,池层有助于模型预测更“社会”合理的路径。
速度。速度对于在现实世界中使用的方法是至关重要的,比如在自动驾驶车辆中,您需要对行人行为进行准确的预测。我们将我们的方法与两个基线LSTM和S-LSTM进行了比较。简单的LSTM执行速度最快,但不能避免冲突或做出准确的多模式预测。我们的方法比S-LSTM快16倍(参见表2)。速度的提高是因为我们不会在每个时间步长上进行合并。此外,与需要为每个行人计算占用网格的S-LSTM不同,我们的池机制是一个简单的MLP,然后是最大池。在实际应用中,我们的模型可以快速生成20个样本,同时需要S-LSTM进行1次预测。
4.2. Qualitative Evaluation
在多代理(人员)场景中,必须对一个人的行为如何影响其他人的行为进行建模。传统的活动预测和人体轨迹预测方法集中在手工制作的能量势建模、吸引力和排斥力建模,以模拟这些复杂的相互作用。我们使用纯数据驱动的方法,通过一种新颖的池机制对人与人的交互进行建模。人类在其他人面前行走时会考虑到自己的个人空间、感知到的碰撞潜力、最终目的地和自己过去的运动来规划自己的路径。在本节中,我们首先评估池层的效果,然后分析我们的网络在三种常见社交交互场景中所做的预测。尽管我们的模型为场景中的所有人做出联合预测,但为了简单起见,我们显示了子集的预测。我们通过图中颜色的第一个字母来指代场景中的每个人(例如,人物B(黑色),人物R(红色)等)。同样为简单起见,我们将sgan-20VP-20称为sgan-P,将sgan-20V-20称为sgan
4.2.1 Pooling Vs No-Pooling

图5:在四种避免碰撞的情况下,我们的模型在没有池(sgan,顶部)和具有池(sgan-P,底部)的情况下的比较:两个人会面(1),一个人会见一个组(2),一个人在另一个人后面(3),以及两个人以一定角度会面(4)。对于每个示例,我们从模型中抽取300个样本,并可视化它们的密度和平均值。由于集合,sgan-P预测社会可接受的轨迹,避免碰撞。
在定量指标上,两种方法的表现相似,sgan略优于sgan-P(参见表1。然而,从定性上看,我们发现共享强制执行了全球一致性和对社会规范的符合性。我们比较了sgan和sgan-P在四种常见的社交场景中的表现(参见图5)。我们想强调的是,即使这些场景是综合创建的,我们也使用了基于真实世界数据训练的模型。此外,这些场景是为了评估模型而创建的,我们的设计中没有任何东西使这些场景特别容易或特别困难。对于每个设置,我们绘制300个样本并绘制轨迹的近似分布以及平均轨迹预测。
场景1和2通过改变方向描述了我们模型的避碰能力。在两个人朝同一个方向前进的情况下,集合使模型能够预测社会接受的向右让路的方式。然而,sgan预测会导致碰撞。同样,与sgan不同,sgan-P能够模拟群体行为并预测回避,同时保留夫妻一起行走的概念(场景2)。
人类也倾向于改变速度以避免碰撞。场景3描述了一个人G走在人B后面,尽管速度更快。如果它们继续保持各自的速度和方向,就会发生碰撞。我们的模型预测人G从右边超车。sgan无法预测一条社会可接受的道路。在场景4中,我们注意到模型预测人B减速,并为人G让步。
4.2.2 Pooling in Action
人们在融合。(第1排)在走廊或道路上,来自不同方向的人合并并走向一个共同的目的地是很常见的。人们使用各种方法来避免碰撞,同时继续朝着目的地前进。例如,一个人可能会放慢速度,稍微改变他们的路线,或者结合使用这两种方法,这取决于周围其他人的环境和行为。我们的模型能够预测一个人的速度和方向的变化,从而有效地驾驭一种情况。
例如,模型预测要么人B减速(Col2),要么人B和R都改变方向以避免碰撞。最后一个预测(COL4)特别有趣,因为该模型预测了人员R的突然转向,但也预测了人员B的响应速度明显减慢;因此做出了全局一致的预测
群体回避。(第2行)人们在相反方向移动时相互回避是另一种常见的情况。这可以通过各种形式表现出来,比如一个人避开一对夫妇,一对夫妇避开一对夫妇等。在这种情况下,要做出正确的预测,一个人需要提前计划,并将目光投向其邻近地区以外的地方。我们的模型能够识别人们在群体中移动,并建立群体行为模型。该模型预测任一组的方向变化,作为避免碰撞的一种方式(第3,4列)。与图5形成对比的是,即使公约可能在这种特殊情况下让路给右翼,也会导致冲突。因此,我们的模型可以预测夫妻向左让路的位置。
跟着的人。(第3排)另一个常见的场景是当一个人走在某人后面。一个人可能想要保持速度或者可能超过前面的人。我们希望提请注意这种情况与其现实生活中的对应情况之间的细微差别。在现实中,一个人的决策能力受其视野的制约。相反,我们的模型在集合时可以获得所有参与场景的人的地面真相位置。这在一些有趣的情况下表现出来(见第3卷)。模型了解到人R在人B之后,并且移动得更快。因此,它预测人B通过改变他们的方向让路,而人R保持他们的方向和速度。该模型还能够预测超车(匹配地面事实)。
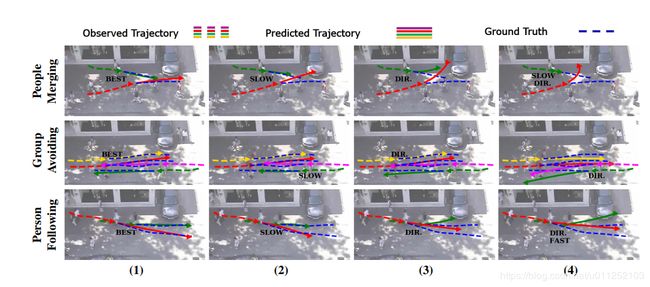
图6:我们模型中不同预测的示例。每一行显示一组不同的观察到的轨迹;列显示每个场景的模型中的四个不同的样本,这些样本展示了不同类型的社会可接受行为。最好的是最接近地面的样本-真相;在慢和快样本中,人们改变速度以避免碰撞;在DIR样本中,人们改变方向以避免彼此。我们的模型以数据驱动的方式学习这些不同的回避策略,并联合预测场景中所有人的全球一致和社会可接受的轨迹。我们还展示了补充材料中的一些失败案例。
4.3.。潜在空间中的结构
在这个实验中,我们试图理解潜在空间z的景观。在所学的流形上行走可以给我们关于模型如何能够产生不同样本的见解。理想情况下,人们可以期望网络在潜在空间中施加某种结构。我们发现潜在空间中的某些方向与方向和速度相关(图7)。
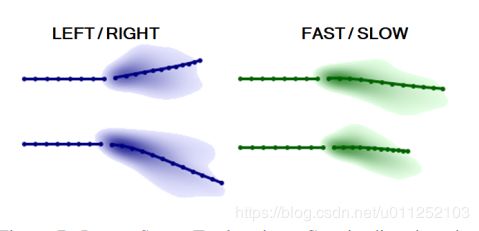
图7:潜在空间探索。潜在流形中的某些方向与方向(左)和速度(右)相关联。观察相同的过去,但沿不同的方向改变输入z会导致模型预测平均方向为右/左或快/慢的轨迹。
- Conclusion
在这项工作中,我们解决了建模人与人之间的交互以及联合预测场景中所有人的轨迹的问题。我们提出了一种新的基于GaN的编解码器框架,用于轨迹预测捕获未来预测问题的多模态。我们还提出了一种新颖的池机制,使网络能够以纯数据驱动的方式学习社会规范。为了鼓励预测样本之间的多样性,我们提出了一种简单的多样性损失,再加上池层鼓励网络产生全球一致的,符合社会标准的多样化样本。我们展示了我们的方法在几个复杂的现实生活场景中的有效性,在这些场景中必须遵循社会规范。