如何自己构建一个小型的Zoomeye----从技术细节探讨到实现
转载请注明出处:http://blog.csdn.net/u011721501?viewmode=list
0、概述
Zoomeye是个网络空间的搜索引擎,它不同于传统意义上的搜索引擎,而是一种可以搜索网络组件和网络设备的搜索引擎。
这种以各大组件指纹作为识别基础的数据平台,更多的是为了使得安全研究人员更好地评估漏洞的影响范围与其中隐含的数据模式。
1、架构分析
这是从网上搜索到的一张Zoomeye的后端架构图,主要分为调度框架、ES存储、UI呈现等模块。对于一次漏洞的评估,启动调度框架分配域名或者IP列表给扫描节点,节点完成任务后执行回调,做出自动化的效果其实也不是很难,从网上找个开源消息队列框架就可以完成了。

其实我认为zoomeye背后必定有一个攻击框架的,原因很简单,这个自动攻击的存在会带来很多利润。
2、搜索项细节分析

如上图是一个discuz组件的搜索项。从这个item中我们可以看得到,主要包括以下数据元:
(1)域名 or IP or title
(2)组件信息(Win32)OpenSSL
(3)国家、城市信息
(4)信息更新时间
(5)Http Response header
以上信息的采集都不是很困难。首先这个域名和IP自然是不困难的,至于这个title,只需要一个正则就抓出来了。
组件信息其实就是Http Response中的server字段信息。
国家、城市可能很多人很疑惑是怎么获取的,这个就是使用了GeoIP数据库,效果很不错。
剩下的就不再说了,一次扫描后(由request得到response)都可以获取到。
2、关于指纹识别
关于Web指纹识别,目前没有什么好的文章,FB中有一篇《浅谈Web指纹识别》写得非常好。我自己也写过一篇,同样是借鉴了FB上的那篇文章的思路,具体文章链接:http://blog.csdn.net/u011721501/article/details/39136797,上面讲了如何实现一个DedeCMS的指纹识别程序。
这里我再抛砖下讲解下如何识别discuz。
| 方法 |
说明 |
| Meta数据元识别 |
使用爬虫技术抓取html页面信息 |
| Intext识别 |
使用模板自身的特征 |
| Robots.txt识别 |
使用robots协议文件robots.txt识别 |
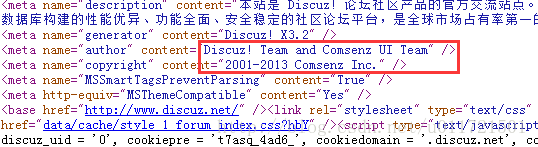
(1)Meta数据元识别
Meta是指网站html中包含的名为“meta”的标签,其中包含一些版权的信息,但是由于位于head标签中,所以不会影响页面布局,在二次开发中如果没有被去除掉,就可以作为识别指纹之一。
(2)intext识别
类似于Meta识别,在网页html文本中,可能存在一些关于版权信息的字符串,如“Powered by xxxx”,通过这些字符串就可以识别相应的组件。

(3)robots文件识别
Robots协议也称为爬虫协议,是“网络爬虫排除标准”的简称。它告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
如下图是Discuz的robots文件,可以看到,通过识别里面的“discuz”字样就可以判断是否是discuz,并且还可以进行粗略版本识别。

上面就是一种识别方法,使用Python,结合正则,实现这个非常简单的。
每个你在Zoomeye进行搜索的keyword,比如搜索discuz,就会噼里啪啦一大堆数据,这些数据的本质就是他们内部积累数据的同时,使用Web指纹识别程序跑出来的。不过这一块需要人力物力才能做得很好。毕竟一个识别程序只能对应一个组件,目前这一块Zoomeye还有待提升。
2、关于数据的来源
Zoomeye背后应该有很强大的硬件资源(带宽、集群)供其扫描拉数据,屌丝们实现一个小型的zoomeye只能用现有的搜索引擎或者自己写爬虫抓来域名跑。我们这学校的条件,达不到说你从1.1.1.1到255.255.255.255都跑着反查一遍,基本不现实。所以,只为了研究为目的,我们主要的来源就是搜索引擎、小规模的反查和扫描IP,我只能说非常得屌丝。
就是这种方法来拉数据,ecshop也还是逮住不少:
2、关于攻击框架
攻击框架是Zoomeye后面必定有的东西,这个结合创宇中安全团队积累的exp,真的会很强大,我们做这个小型Zoomeye自然也配上一个。具体怎么实现的思路我已经写过一篇文章来阐述了:http://blog.csdn.net/u011721501/article/details/41908003
这里无非就是攻击模式规定的规则了,我是做了如下的定义:

2、成果展示
说了乱七八糟一大堆,基本上都是说明我们实现这款小型zoomeye的大体思路,下面就是我们的小小的成果,由于前段童鞋不给力,所以请勿吐槽UI。
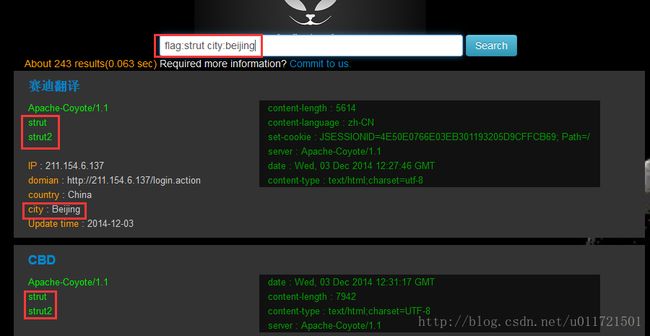
(1)多端口搜索
后端我们同样选择elasticsearch来构建,使用DSL语法与简单的语法解析轻松可以构建出多端口搜索功能:
(1)攻击框架的演示
想必最最神秘的就是这个攻击框架了,因为至今zoomeye上也没有相关信息。倒是Fofa上有一个,不过是基于命令行的,我们这里更进一步,做成了基于WebUI的,测试如下:
1)指定exp名称攻击:
全域名扫描(针对现有的域名全部进行攻击):
python safecatcli.py -m exp_name -n [exploit_file_name] -o all
-m exp_name -n goods_attr_exploit -o all

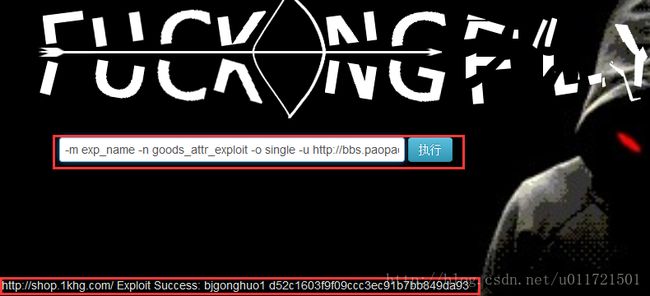
单个目标扫描(对输入的url或者ip地址载入攻击脚本进行攻击): python safecatcli.py -m exp_name -n [exploit_file_name] -o single -u [url or IP addr]
-m exp_name -n goods_attr_exploit -o single -u http://bbs.paopaoyu.cn/
IP段扫描(对一个IP段的主机进行攻击): python safecatcli.py -m exp_name -n [exploit_file_name] -o range -start [your-start-ip-addr] -end [your-end-ip-addr]
-m exp_name -n goods_attr_exploit -o range -s 182.18.17.82 -e 182.18.17.82
2)指定关键词进行扫描:
you_class_name填你要攻击的flag,比如项目中整合了discuz,ftp,ecshop等,这里要填信息
* 指定查询语句攻击(对提交的查询语句进行解析,从es中找出符合条件的域名列表,然后载入一个模块的全部攻击脚本进行攻击)
python safecatcli.py -m flag -c [your class name] -q "[your query string]"
比如:攻击台湾的discuz主机
python safecatcli.py -c discuz -q "discuz country:Taiwan"
-m flag -c ecshop -q "ecshop"
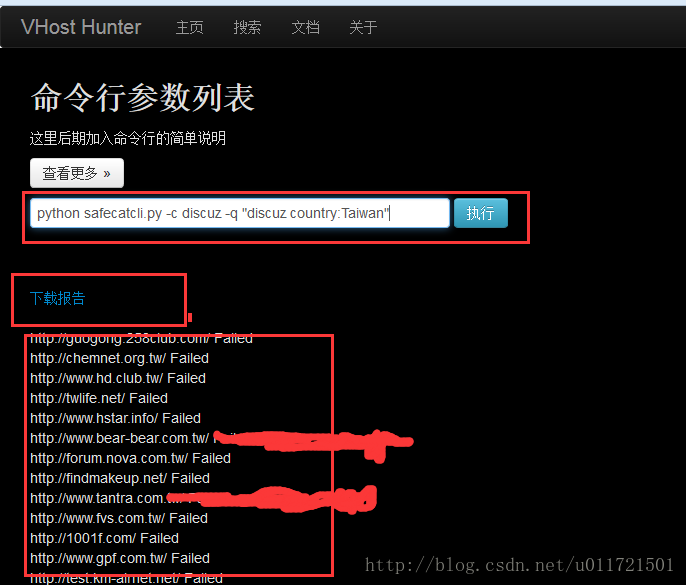
* 指定一个域名攻击(对提交的一个domain进行攻击,从模块中载入全部脚本进行攻击):
python safecatcli.py -c discuz -u [domain]
-m flag -c ecshop -u http://www.1688gys.com
7、总结
Zoomeye这种产品尽管很多人在做,比如Fofa,但是能做到Zoomeye这种产品级别的真的不算多。因为这里面的技术细节有多么坑真的很难想象。做了一学期,我们这东西也只能说可以看得下去了,离得真正的Zoomeye还是不少差距。不管怎么说,我们也仅是觉得Zoomeye这种东西做起来非常有意思,也只是做个这类技术的研究,欢迎讨论。
转载请注明出处:http://blog.csdn.net/u011721501?viewmode=list
由于源代码比较散乱,整理过后会share,大牛勿喷。
设计部分文档share:链接:http://pan.baidu.com/s/1i3tbohf 密码:8sko