本文意在理解java.util.concurrent.locks.AbstractQueuedSynchronizer中关于线程互斥的算法实现。分为两部分
- 逐步实现高效的CLH自旋锁(aqs参考了CLH的算法)
- 再将CLH自旋锁改造为阻塞锁,并优化
主要参考了,《多处理器编程的艺术》(The art of multiprocessor programming)书中关于自旋锁的几章,及Doug lea的 aqs paper http://gee.cs.oswego.edu/dl/papers/aqs.pdf
所有的算法实现都是基于Java的。不考虑,锁的取消,中断处理,condition等功能。
下文的锁算法都实现了简化了的Lock接口:
public interface Lock {
void lock();
void unlock();
}
基于内存读写的自旋锁实现
双线程锁
先考虑简单的双线程互斥,先来看两个实验性的想法
lock one
用一个共享变量能否实现互斥呢?
ThreadID.get()是当前的线程编号,从0开始递增,以后会经常利用这个id号
public class NaiveLock2 implements Lock {
private volatile int victim;
public void lock() {
int id = ThreadID.get();
victim = id; // another first
while (victim == id) { // FIXME 最后一个试图获得锁的接盘侠会死锁
}
}
public void unlock() {
}
}
互斥。但是最后一个试图获得锁的线程会一直等待
lock two
public class NaiveLock1 implements Lock {
private boolean[] flag = new boolean[2];
public void lock() {
int id = ThreadID.get(); // 获得线程id从0开始
int anotherThreadId = 1 - id;
flag[id] = true; // 声明我想要获得锁,让另一个等待
// FIXME dead lock when both threads run here
while (flag[anotherThreadId]) { // 根据另外一个线程的状态选择是否等待
}
}
public void unlock() {
int id = ThreadID.get();
flag[id] = false;
}
}
同样,互斥但死锁
lock one + lock two = Peterson lock
public class PetersonLock implements Lock {
private volatile boolean[] flag = new boolean[2];
private volatile int victim;
@Override
public void lock() {
int id = ThreadID.get();
int anotherThreadId = 1 - id;
flag[id] = true;
victim = id;
// 如果另一个线程试图抢占,并且我再其之后,就等待
while (flag[anotherThreadId] && victim == id) {
}
}
@Override
public void unlock() {
int id = ThreadID.get();
flag[id] = false;
}
}
This algorithm is arguably the most succinct and elegant two-thread mutual exclusion algorithm.
证明无死锁: 反证:假设如果线程1死锁,线程2在干嘛呢?
- 也死锁了? victim不可能被赋予两个值,不可能两个线程都在忙等
- 正常进出临界区,或者终止? 一定会调用unlock(), 会将flag[2]置为false,线程1不可能一直忙等
volatile数组
事实上volatile boolean[] flag描述的只是数组引用,并不能保证里面的每个数组元素都是volatile的。
但这个上面的实现 运行的结果却很可能是正确的。
其实这里去掉flag的volatile也没有任何影响,大概的解释是victim变量和flag[]的内存被jvm分配到了一起,在一个cpu cache line size中(一般是64B), 所以对victim的可见性保证也会影响到flag。
更正确的做法可以把数组元素用对象包装一下。也可以用AtomicIntegerArray来代替。
volatile array in java
N线程锁
The Filter Lock
PetersonLock 可以扩展到多线程中, 找到一位灵魂画师的解说图..
对于6个线程的情况:

- 假设有个6层的城堡。达到城堡顶层需要穿过第0到5层。每进入上一层前都需要申请。到达第5层可以成为King,做完为所欲为的事情之后需要卸任(unlock),同一时间只能有一个人成为King(临界区)。
- 有6个士兵都想要当国王,为了防止发生混乱,大家达成了一个协定: 当你想更上一层时需要遵循两个规则:
- C1:其他所有人所在层都比你低时,就可以直接进入上一层
- C2: 在每一层N中,最后一个申请进入N+1的人,会被留在当前N层接手守卫工作,而之前申请的人都会进入上一层。
结合图可以脑补场景:
- 6个人(t0-t5)先后都来到了0层
- t0-t5先后申请上1层, t5最晚
- t5 不满足C1,C2 , 留在0层当守卫
- t0-t4 不满足C1,满足C2,于是t0-t4进入了1层
- t0-t4先后申请上1层, t4最晚
- ...
- t0-t5分别处于5-0层, t0是king
- t0卸任
- 此时t1发现自己满足C1条件,进入下一层
- ...
这里和PetersonLock一样可以用反证来证明互斥性,无饥饿,公平
public class PetersonNLock implements Lock {
int n;
/**
* level[T]=l 表示线程T正在尝试进入的层数l
* 初始化所有线程都在第0层
*/
private int[] level;
/**
* victim[l]=T 表示需要在第l层留守的线程
*/
private int[] victim;
private volatile boolean barrier;
public PetersonNLock(int n) {
this.n = n;
level = new int[n];
victim = new int[n];
}
@Override
public void lock() {
int T = ThreadID.get();
for (int l = 1; l < n; l++) { // 尝试穿透1到n-1层
level[T] = l; // 告诉大家,我正尝试上第l层
victim[l] = T; // 替换victim。"你先来的,你走吧,l层由我来守护"
barrier = true;
Outer:
for (; ; ) {
for (int k = 0; k < n; k++) { // 看别的线程是啥情况
// 如果有接盘侠(victim[l] != T) 或者,
// 其他所有人所在的层级都比我低, 就可以进入上一层
if (k != T && level[k] >= l && victim[l] == T) {
continue Outer;
}
}
break;
}
}
}
@Override
public void unlock() {
int id = ThreadID.get();
level[id] = 0; // 回到0层
}
}
Bakery Lock
面包店锁: 采用一种发号的方式
public class BakeryLock implements Lock {
int n;
private boolean[] flag;
private int[] label;
private volatile boolean barrier;
public BakeryLock(int n) {
this.n = n;
flag = new boolean[n];
label = new int[n];
for (int i = 0; i < n; i++) {
flag[i] = false;
label[i] = 0;
}
}
@Override
public void lock() {
int i = ThreadID.get();
flag[i] = true; // 标识我试图获得锁
// 递增生成号码,可能重复
label[i] = maxLabel() + 1;
barrier = true;
Outer:
for (; ; ) {
// 检查其他线程的情况
for (int k = 0; k < n; k++) {
// 如果存在其他线程K,也试图获得锁,并且号码比自己小(相同的情况下,比线程号大小),就继续等待
if (k != i && flag[k] && ((label[k] < label[i]) || (label[k] == label[i] && k < i))) {
continue Outer;
}
}
break; // 如果自己是最小的,获得锁
}
}
@Override
public void unlock() {
flag[ThreadID.get()] = false;
}
private int maxLabel() {
int max = 0;
for (int i : label) {
if (i > max) {
max = i;
}
}
return max;
}
}
基于读写内存锁的问题
The Bakery lock is succinct, elegant, and fair. So why is it not considered practical? The principal drawback is the need to read and write n distinct locations, where n (which may be very large) is the maximum number of concurrent threads.
Is there a clever Lock algorithm based on reading and writing memory that avoids this overhead? We now demonstrate that the answer is no. Any deadlock-free Lock algorithm requires allocating and then reading or writing at least n distinct locations in the worst case. This result is crucially important, because it motivates us to add to our multiprocessor machines, synchronization operations stronger than read-write, and use them as the basis of our mutual exclusion algorithms.
可以证明:基于读写内存的互斥实现,至少需要N个存储单元(n是并发线程数)。 这个开销是很大的,所以不管是FilterLock还是BakeryLock都不实用。
这个结论促使了在硬件上增加的原子操作指令
基于原子指令的锁
基于同步指令我们可以实现更实用、更高效的锁
TAS & TTAS
test-test-and-set
public class TTASLock implements Lock {
private AtomicBoolean state = new AtomicBoolean();
public void lock() {
while ( /* state.get() || */ !state.compareAndSet(false, true)) {
}
}
public void unlock() {
state.set(false);
}
}
TAS主要的问题是:
- 自旋时,compareAndSet 独占cpu总线,并且擦除其他线程的cpu cache
- 持有锁的线程释放锁时,可能会被delay。 因为spinner可能独占总线
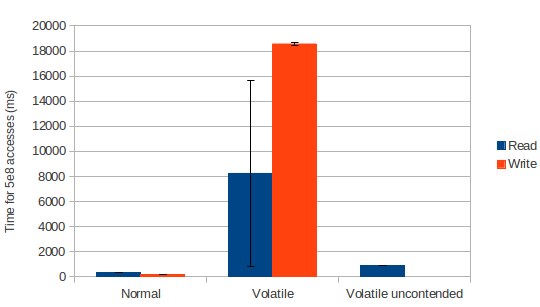
由于TTAS优先调用get(volatile read)而不是cas,cpu cache能在自旋时被利用,避免了上面的问题。
volatile读在x86架构上,低争用的场景下,性能很好
The JSR-133 Cookbook for Compiler Writers - Doug Lea
Are volatile reads really free?
深入理解Java内存模型(四)——volatile
但是当释放锁时,争用的情况仍会发生:所有的spinner发生cache miss,然后从内存中重读新值,然后调用cas ,第一个线程成功后,其他线程又需要重读新值。
这种触发大量线程争用的情况也可称之为 惊群(thundering herd)
要解决这个问题,可以考虑将各个spinner的自旋的存储单元分散。即 释放锁只“惊动”一个spinner
ALock
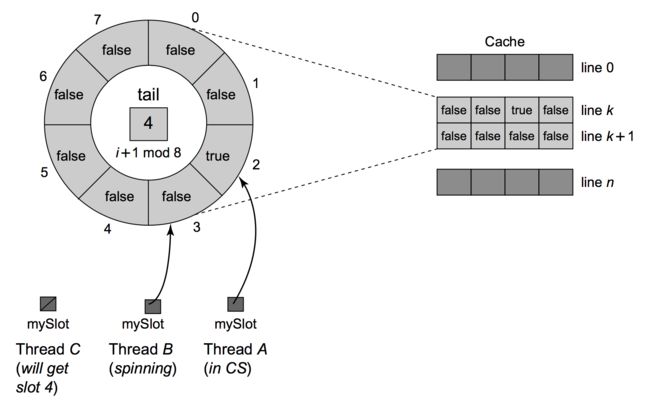
考虑一种基于数组的队列
- 初始化一个size为n的数组,n为最大并发线程数
- 将其看成一个环,每个线程都会被分配一个slot = (当前slot + 1) % n , slot从0开始(0被初始化成true)
- 线程在被分配的数组单元上自旋, while(!flag[slot]){}
- 当释放锁时,将当前slot置为false, 为了解锁下一个线程,将下一个slot置为true
- 在这个slot上自旋的线程将会获得锁,进入临界区
public class ALock2 implements Lock {
static class WBoolean {
volatile boolean element;
//public volatile long p1, p2, p3, p4, p5, p6 = 7L;
}
int[] slotIndex; // 保存每个线程自旋的slot
AtomicLong tail; // 原子更新tail
WBoolean[] flag; // ring
int size;
public ALock2(int capacity) {
size = capacity;
slotIndex = new int[capacity];
tail = new AtomicLong(0L);
flag = new WBoolean[capacity];
for (int i = 0; i < capacity; i++) {
flag[i] = new WBoolean();
}
flag[0].element = true;
}
public void lock() {
int tid = ThreadID.get();
// enqueue 原子入队
int slot = (int) (tail.getAndIncrement() % size);
slotIndex[tid] = slot;
// 等待其变为true
while (!flag[slot].element) {
}
}
public void unlock() {
int slot = slotIndex[ThreadID.get()];
// 释放并重置slot
flag[slot].element = false;
// 唤醒下一个spinner
flag[(slot + 1) % size].element = true;
}
}
这个实现存在一个问题。 队列锁的目标是使spinner自旋在不同的存储单元上,unlock只使一个spinner 脱离“本地旋转”。 但是cpu cache的最小单元是一个 cache line(缓存行,一般是64个字节),上面的数组存储单元实际上存在了共享cache line的情况(这是测试后证实的结果,没有了解jvm的内存分配策略和执行行为), 这导致unlock使一个cache line失效,从而这影响了多个存储单元上的spinner。
一种优化方式是,填充cache line ,比如上面代码中WBoolean的注释部分。 测试结果打开注释,性能会有近一倍的提升。
值得一提的是,在实际测试中有一个现象: ALock在 线程数
猜测: spinner忙等时占用了cpu core。 TTAS unlock时任何一个spinner 都可能获得锁,得以让程序继续进行。 而ALock只释放一个后继的spinner,当线程数>core num时 ,这个spinner很有可能被系统 cs出去了,没有分配到时间片(time slice),而等待到时间片的量级可能是毫秒。
书中一直强调的自旋锁在单核环境中没用也是类似的原因,因为单核系统的多应用执行依赖上下文切换,spinner会不断的被分配操作系统时间片。
CLHLock
ALock若要支持的最大并发量N,需要事先分配好N的空间。
考虑一种基于链表的队列锁。
public class CLHLock implements Lock {
AtomicReference tail;
QNode head;
public CLHLock() {
// 队尾初始化一个node
tail = new AtomicReference<>(new QNode());
}
@Override
public void lock() {
QNode me = new QNode();
me.locked = true; // locked 表示后续节点的状态
QNode pred = tail.getAndSet(me);
me.pred = pred;
while (pred.locked) {
// 自旋在前驱节点
}
head = me; // 获得锁,标识node
}
@Override
public void unlock() {
QNode me = head;
me.pred = null; // gc
me.locked = false; // release successor
}
}
唯一的缺点就是: 在无竞争的环境下,仍然需要 new 一个node,并且入队。 可以考虑和TTAS结合。(下文BlockingLock会提到,这里省略自旋锁的实现了)
Blocking Lock
自旋锁在持有锁时间很短的环境下,比较有效,毕竟频繁的进行系统调用阻塞线程开销很大。 反之,当持有锁的时间较长,阻塞便有意义了。实际中高效的锁实现往往是这两种方式的结合。(例如hotspot 的 synchronized的自适应自旋优化,adaptive spinning)
Aqs做了Adaptive spinning 优化了吗?
参考aqs实现,java层面是没有的。
vm层面可以参考Doug 在 一篇帖子中的回复:
aqs是java语言层面的锁,做Adaptive spinning 有点tricky,况且真的有需要也可以很方便的自己通过tryLock来实现。 有一个JEP-143(Java Enhancement-proposal) 在 vm层面(Unsafe.park)去做。但是发帖时 oracle没有在jdk8中没有实现,尽管doug认为这是"pretty good idea"。
http://openjdk.java.net/jeps/143
https://bugs.openjdk.java.net/browse/JDK-8046133
最终java9里实现了这个增强
CLHBlockingLock
我们试图将CLHLock自旋锁,改成阻塞方式。
自旋锁和阻塞锁,最大的区别是unlock时需要持有锁的线程(队列head)主动通知其后继节点(successor)。 CLH只有prev指针,而原子的操作双向链表是不可能的,所以从tail回溯是唯一的准确办法。
QNode tail = this.tail.get();
QNode next = null;
while (tail != me) {
next = tail;
tail = tail.pred;
}
if (next != null) {
释放(next.thread);
}
CLHLock中入队是通过调用tail.getAndSet,然后在设置prev指向返回的前驱节点。设想如果回溯寻找successor时,入队的线程完成了tail.getAndSet,却没有完成prev指针的�赋值,这种情况就unlock就无法回溯到successor了。 所以prev的设置一定要在真正入队(getAndSet)之前。
for (; ; ) {
pred = this.tail.get();
me.pred = pred; // set pred first
if (tail.compareAndSet(pred, me)) {
break;
}
}
if (pred.locked) {
LockSupport.park();
}
此时我们的CLHBlockingLock的形态是这样
public class CLHBloc implements Lock {
AtomicReference tail; // 队尾
QNode tmpHead; // 记录当前进入临界区的节点
public CLHBloc() {
tail = new AtomicReference<>(new QNode());
}
public class QNode {
volatile Thread thread;
volatile QNode pred;
volatile boolean locked;
}
@Override
public void lock() {
QNode me = new QNode();
me.thread = Thread.currentThread();
me.locked = true;
QNode pred;
for (; ; ) {
pred = this.tail.get();
me.pred = pred; // set pred first
if (tail.compareAndSet(pred, me)) {
break;
}
}
if (pred.locked){
Thread.suspend()
}
tmpHead = me; // 获得锁,标识node
me.pred = null; // gc
}
@Override
public void unlock() {
QNode me = tmpHead;
me.locked = false;
QNode tail = this.tail.get();
QNode next = null;
while (tail != me) {
next = tail;
tail = tail.pred;
}
if (next != null) {
next.thread.resume();
}
}
}
java如何阻塞线程
我们比较熟知的方式是Thread.suspend Thread.resume。但是这对api要求resume,必须在suspend之后执行。不然是没有效果的。而在实现这种并发场景中,“阻塞”和“释放”的顺序是无法保证的。
JSR-166,专门为了实现Synchronizor而提供了一种新的线程阻塞的方式:LockSupport.park unpark 。 park可能会无条件返回,不保证一定会阻塞住线程(上文提到的自旋和阻塞结合,就是在这个方法的实现层面做的)。 所以我们的编程方式应该和自旋锁差不多,需要在循环中check互斥条件。
unpark会立刻释放被park阻塞的线程,如果没有,下一次park会直接返回。unpark可以理解为:只是为了更有效的,在锁释放后,第一时间调用unpark释放可能正在或者将要park的线程** ,保证临界区的利用。
使用LockSupport:
public class CLHBloc implements Lock {
AtomicReference tail; // 队尾
QNode tmpHead; // 记录当前进入临界区的节点
public CLHBloc() {
tail = new AtomicReference<>(new QNode());
}
public class QNode {
volatile Thread thread;
volatile QNode pred;
volatile boolean locked;
}
@Override
public void lock() {
QNode me = new QNode();
me.thread = Thread.currentThread();
me.locked = true;
QNode pred;
for (; ; ) {
pred = this.tail.get();
me.pred = pred; // set pred first
if (tail.compareAndSet(pred, me)) {
break;
}
}
while (pred.locked) {
LockSupport.park();
}
tmpHead = me; // 获得锁,标识head
me.pred = null; // gc
}
@Override
public void unlock() {
QNode me = tmpHead;
me.locked = false;
QNode tail = this.tail.get();
QNode next = null;
while (tail != me) {
next = tail;
if (tail == null) { // successor may wake up and cut off chain
break;
}
tail = tail.pred;
}
if (next != null) {
LockSupport.unpark(next.thread);
}
}
}
下面证明:“在锁释放后,上面的实现会第一时间调用unpark释放可能正在或者将要park的线程 ”
假设:A为持有锁,即将unlock的线程,B为争用线程。当“B正在或者将要执行park()”,必定至少一次进入了while循环,至少一次看见pred.lock=true。由于代码中有以下顺序
Thread(A): (A1)设置pred.locked=false > (A2)find successor
Thread(B): (B1)enqueue > (B2)检查 pred.locked=true > (B3)park()
所以B1 > B2{1st} > A1 > A2,即find successor 一定在enqueue之后。 所以必定能找到后继线程并调用unpark阻止其park调用阻塞线程,或者当已经阻塞的话释放之。
防止空指针
由于B3 park()可能随时无条件返回,可能会循环到B2。
有以下几种情况:(A1之后的B2会跳出循环,进入临界区)
A:............................................A1..........A2..............
B:B1 B2{1st} [B3 B2 .... ] B3 .......B2 END
这种情况,
A:..........................................A1..........A2..............
B:B1 B2{1st} [B3 B2 .... ] B3 ...................B2 END
A:..........................................A1..............A2.........
B:B1 B2{1st} [B3 B2 B3 .... ] ......B3..B2 END
A:..........................................A1..A2.....................
B:B1 B2{1st} [B3 B2 B3 .... ] ............B3..B2 END
考虑B2发生在A1和A2之间情况,B线程后续可能执行完临界区,继而运行到unlock,unlock会断掉prev指针。导致A线程回溯节点时找不到successor了,所以需要回溯时考虑这种情况,防止空指针。
优化 CLHBlockingLock
上一节已经有了雏形。但还有很大的优化空间。
optimize for non-contented
显然,最需要改进的一点是,上面的实现,每次lock()必定要经过一次入队操作,在没有争用的情况下效果很差。
TTASLock在无争用环境下效果很好。能否结合这两种算法呢?
可是回顾TTASKLock我们知道,TTASLock是用的统一的存储单元做互斥,而CLH是利用分散在队列中的存储单元。
TTAS的缺点就是释放锁时的“惊群”效应,而为了避免惊群,才用队列的方式,分散spinner自旋的存储单元。
确实,但那是在自旋锁实现中的改进,我们现在要实现的是BlockingLock了啊,没有spinner了,可以说不用考虑惊群的效应了,不用考虑单存储单元的总线争用了,因为根本就没那么多争用线程了,原来busy waiting的spinner 都block了,所以,完全可以放弃各个节点中的locked属性,回归到单一存储单元。
回到实现中,就是放弃各个节点中的locked标识,用TTASLock的统一的存储单元来做互斥。
由于自旋在分散存储单元,CLHLock自旋锁unlock时,只会释放下一个节点,保证队列的完整性。
而改为统一存储单元就没有这个天然的保证了。但我们可以通过检查node.pred == head 来保证只有队列中的头结点才能获取锁。
lock:
if (try acquire) return
enqueue
while(head != pred OR try acquire fail)
park()
unlock:
release
find successor and unpark;
一些其他的优化
fast path to find successor
回溯找节点很慢,但是可以提供一个快速查找的的next指针,找不到了在failback到回溯的方式。
avoid unnecessary park & unpark & find successor
避免每次unlock都会find successor。
增加一个node中的标志位
lock不立刻park线程,先set 标志位,再经过一次条件检查再park。
unlock,检查标志位被设置了,才去find successor。
最终有了下面的实现,建议此时再去看aqs的实现,会发现很多相同的设计,再去理解其高级特性的实现也会容易的多。
public class CLHBlockingLock2 implements Lock {
AtomicReference tail;
volatile QNode head;
AtomicBoolean state = new AtomicBoolean();
public CLHBlockingLock2() {
head = new QNode();
tail = new AtomicReference<>(head);
}
public class QNode {
volatile Thread thread;
volatile QNode pred;
volatile QNode next;
volatile boolean signal;
}
@Override
public void lock() {
if (tryAcquire()) return;
QNode me = new QNode();
me.thread = Thread.currentThread();
QNode pred;
for (; ; ) {
pred = this.tail.get();
me.pred = pred; // set pred first
if (tail.compareAndSet(pred, me)) {
break;
}
}
pred.next = me;
while (pred != head || !tryAcquire()) {
if (pred.signal) {
LockSupport.park(this);
} else {
pred.signal = true;
}
}
head = me;
pred.next = null;
me.pred = null;
}
private boolean tryAcquire() {
return !state.get() && state.compareAndSet(false, true);
}
@Override
public void unlock() {
QNode me = head;
state.set(false);
if (me.signal) {
QNode tail = this.tail.get();
QNode next = me.next;
if (next == null) {
while (tail != me) {
next = tail;
if (tail == null) { // successor may wake up and cut off chain
break;
}
tail = tail.pred;
}
}
if (next != null) {
LockSupport.unpark(next.thread); // ensure successor recheck locked
}
}
}
}