商汤科技面试准备
商汤科技面试准备
秋招收到了东软医疗算法,明略科技算法,云从算法的Offer
但是在我沉淀了整个求职季之后
心心念念的商汤,终终终终终终终终终于给我发起面试邀请了
商汤一直是我最想进的企业,没有之一
一些长久以来,秋招面试的相关知识点,各种原文链接总结在这
我有很努力去争取
希望世界上最好的商汤科技的明天的面试
顺利通过,fighting and praying
内容导航
- 一.医学影像方向相关知识
- 1. dicom图像的各种指标
- 2. CTA图像的特点
- 3. MRI图像的特点
- 4. 世界坐标和人体坐标及其相互转换
- 5. 超声图像的特点
- 二.传统图像处理算法
- 1. 区域生长法
- 2. 水平集算法CV模型及snake模型
- 3. 血管增强的Frangi算法及Hessian矩阵的特征值含义
- 4. 各种去噪算法(各向异性扩散滤波,小波滤波,中值滤波,其余的带过)
- 5.霍夫变换检测直线和圆
- 三.深度学习基础知识点
- 1. 深度学习的历史,各种神经网络优缺点
- 2. BN层的用法和实现
- 3. 各种正则化
- 4. 梯度消失和梯度爆炸及其解决方法
- 5. 过拟合及欠拟合及其解决方法
- 6. 优化算法和优化的策略
- 7. 输出尺寸计算,网络参数量FLOPS计算
- 8. 感受野的计算,反向传播的梯度推导
- 9. 常见损失函数的作用和用法
- 10. 常见的核函数及其解决的问题
- 11. TP,FP,TN,FN的解释及常用的评价指标
- 12. SVM推导
- 13. LR推导
- 14. K-MEANS推导
- 15. KNN推导
- 四.基础数据结构
- 1. C++的内存机制
- 2. C++的继承多态虚函数
- 3. 指针的用法及const和引用
- 4. 各种排序算法
- 6. 最长公共子序列
- 7. 最长公共子串
一.医学影像方向相关知识
1. dicom图像的各种指标
参考原文
- Patient Tag:包含患者的信息,比如身高体重之类的
- Study Tag:检查的信息,比如检查的日期这样的
- Series Tag:包含唯一识别的序列号和层厚这样的信息
- Image Tag:图像的信息,比如图像的窗宽窗位和坐标原点这样的
2. CTA图像的特点
- 全称Computer Tomography Angiography
- 计算机断层造影图像
- 打造影剂使得血管的对比度比其他组织的高,呈现白色
- 有运动伪影,灰度值分布不均的问题
3. MRI图像的特点
- 全称Magnetic Resonance Imaging
- 磁共振造影图像
- 不需注射造影剂
- 磁共振信号愈强,则亮度愈大
- 流动液体不产生信号。因此血管是灰白色,而血液为黑色。
4. 世界坐标和人体坐标及其相互转换
参考博客原文,基本的示例如下:
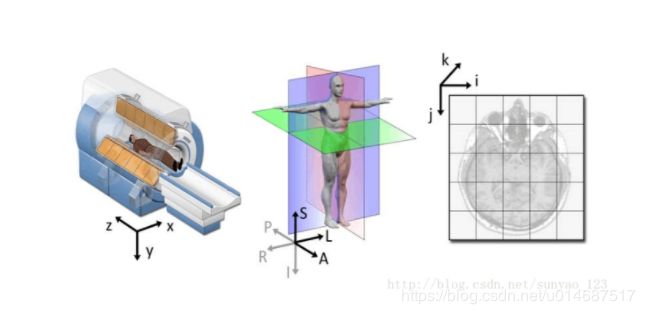
- 从左到右依次是世界坐标系,解剖坐标系和图像坐标系
- Dicom图像中通过在DICOM标准中通过Image Position(Patient)和Image Orientation(Patient)两个字段来确定患者Patient的空间定位.
- Image Position:表示图像的左上角在空间坐标系中的x,y,z坐标,单位是毫米.
- Image Orientation:表示图像坐标与解剖学坐标体系对应坐标的夹角余弦值.
- 将需要转换的世界坐标减去origin,再除以spacing就是对应的图像中的坐标
5. 超声图像的特点
- 通过对反射信号的接收、处理,以获得体内器官的图象
- 噪声相对于其余两种就比较大,声伪影,操作伪影,环境干扰
- 直接探测法,耦合剂
二.传统图像处理算法
1. 区域生长法
- 在8邻域(2D)或者26邻域(3D)进行相似像素/体素的搜索,分类
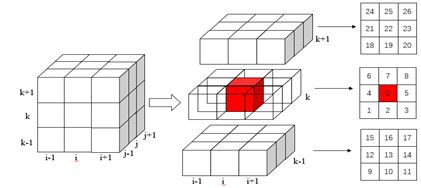
2. 水平集算法CV模型及snake模型
通过定义初始化零水平集,演化能量泛函,进行曲线的演化,在指定的迭代次数范围内,收缩到一个误差在指定范围内的边界停止达到分割的目的
3. 血管增强的Frangi算法及Hessian矩阵的特征值含义
3维图像的Hessian矩阵的是哪个特征值,代表了物体在空间中的形状,不同的特征值分别代表了长短,粗细以及凸扁,因此可以通过调节参数将图像中的管状结构增强,达到预处理的目的。
4. 各种去噪算法(各向异性扩散滤波,小波滤波,中值滤波,其余的带过)
- 各向异性扩散滤波(Anisotropic diffusion):将热能的方程引入图像中,类似平均的思想,在指定迭代次数之后,会将图像操作成“烧糊”的状态,达到去除异常点的效果
- 小波滤波:将小波变换引入图像之中,变换到频域上剔除异常点
- 中值滤波:主要去除图像中的椒盐噪声
5.霍夫变换检测直线和圆
参考博客1(检测直线讲的好):https://blog.csdn.net/weixin_40196271/article/details/83346442
参考博客2(检测圆讲得好):https://blog.csdn.net/shanchuan2012/article/details/74010561
- 核心思想:找参数空间中曲线交点最多的位置,作为检测出的基准点确定圆或者直线
- 采用极坐标系的方式表示直线( r θ r\theta rθ)同时检测当前点的比如八邻域,计算出 r θ r\theta rθ曲线相交的位置代表拥有相同长度和相同x轴的点,就是利用点共线检测出的直线位置
- 采用(a,b,r)表示圆,假设半径已知的话(一般初始化为某个范围),可以表示出圆,利用多点共圆来检测出最可能是圆心的位置,作为检测出的圆形的圆心
三.深度学习基础知识点
1. 深度学习的历史,各种神经网络优缺点
引用我自己的博客1和博客2,里面有原文链接,下面的论述想到什么写什么,没有严格按照时间顺序:
- lenet: 参数共享,局部感知,平均池化降采样
- zfnet :做了很多细小的试验,验证深度学习的可行性
- vgg:证明网络深度是很有影响力的,但是太深会梯度爆炸
- google net: 多种大小卷积并联,在增加宽度的同时增加网络对尺度的适应性
- inception:加入了BN层,后续扩宽了网络的维度
- resnet:引入了残差模块,解决了梯度消失和爆炸的问题
- renext:用更少的参数实现了和resnet差不多的效果
- senet:提出了se模块,在残差模块中加入了全局池化,提升效果
- mobilnet:可分离卷积
- shufflenet:分组卷积,参数量变为原来的1/组数
- xception:深度可分离卷积,将传统卷积分成了深度卷积和逐点卷积,参数量变为原来的1/N+1/k^2,N是输出的通道数,k是卷积核的长宽(假设一样)
- fcn:从分类到分割,同层的特征图对应相加
- segnet:考虑了时间和内存,改进了fcn,看上去更规整
- unet:适用于医学影像,在fcn的基础上,将同层的相加改成了concat
- attention unet:在unet的基础上在上采样部分加入了注意力机制,挖掘特征
- unet++:下采样改进的极致,充分利用了下采样过程中的中间信息
- danet:引入了位置注意力机制和通道注意力机制,更加充分的挖掘了特征信息
- DFN和BISENET:充分利用了SENet的SE模块,阐述的方面不同,但是将global pooling运用到了极致
- deeplab123+:1运用了带孔卷积条件随机场,2用了resnet和多尺度带孔卷积,3去掉了条件随机场用了BN,3+优化了decode部分,还原特征
2. BN层的用法和实现
- 全称:Batch Normalization,翻译为批量归一化
- 一种训练优化方法,加快网络学习速率,解决的问题是梯度消失与梯度爆炸
- 求均值和方差,数据标准化(类似正态分布),BN层有两个需要学习的参数,平移因子和缩放因子调整参数,输出值
3. 各种正则化
引用自博客
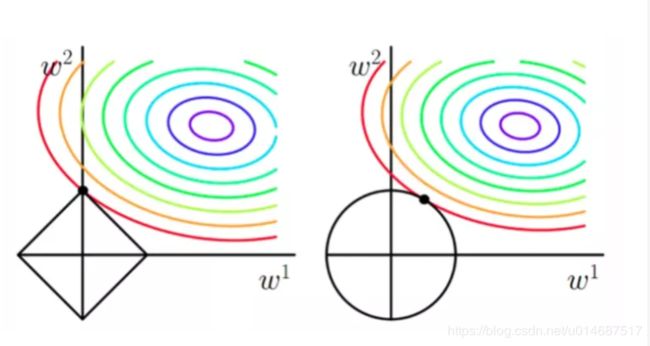
-
L1范数:符合拉普拉斯分布,完全不可微菱形去切等高线,会造成最优的值出现在坐标轴上,出现大量的0,造成稀疏,防止过拟合
-
L2范数:符合高斯分布,完全可微的,圆形去切等高线,一般最优值不会出现在坐标轴上,L2让系数缩小但不为0,加速优化。
-
L1会趋向于产生少量的特征,而其它特征都是0。
L2会选择更多的特征,这些特征都会趋近于0。 -
L1在特征选择时非常有用,而L2只是一种防止过拟合的方法。
-
在所有特征中只有少数特征起重要作用的情况下,选择L1范数比较合适。
而如果所有特征中,大部分特征都能起作用,而且起的作用很平均,那么使用L2范数也许更合适。
4. 梯度消失和梯度爆炸及其解决方法
- 训练过程中,正向传播的参数和反向传播的梯度计算可能会导致小数越来越小,或者大数越来越大
- 解决方法有:残差模块,使用合理的损失函数和非线性的激活函数,合理控制网络的深度
5. 过拟合及欠拟合及其解决方法
- 防止过拟合:正则化,减小模型复杂度,数据增强,dropout,学习策略
- 防止欠拟合:增加数据量,减小正则化参数
6. 优化算法和优化的策略
- 参数初始化,采用何凯明的方式初始化
- adam的优化算法,动量
- 每过几个epochs学习率衰减一些
7. 输出尺寸计算,网络参数量FLOPS计算
引用我自己的博客
- 参考链接,输出尺寸:(f-k+2p)/s+1,same的情况,f/s向上取整,valid的情况用p=0来计算
- 参考链接,参数量的计算,卷积层用 K 2 × C i n × C o u t + C o u t K^2\times{C_{in}}\times{C_{out}}+C_{out} K2×Cin×Cout+Cout,BN层用 2 × C i n 2\times{C_{in}} 2×Cin
- Flops计算:参数量xHxW,详细的推导参考这里
8. 感受野的计算,反向传播的梯度推导
引用我自己的博客
- r f k = r f k − 1 + ( f k − 1 ) × s 0 × s 1 . . . × s k − 1 rf_{k}=rf_{k-1}+(f_{k}-1)\times{s_0}\times{s_1}...\times{s_k-1} rfk=rfk−1+(fk−1)×s0×s1...×sk−1其中k代表第k层, s 0 s_0 s0初始化为1, r f 0 rf_0 rf0初始化为1
- y=wx+b正向推导,反向梯度推导参照链式法则
- relu表达式为: r e l u ( x ) = m a x ( 0 , x ) relu(x)=max(0,x) relu(x)=max(0,x),relu的导数是小于0的都是0,大于0的都是1
- sigmoid的表达式: g ( z ) = 1 1 + e x g(z)=\frac{1}{1+e^x} g(z)=1+ex1,导数为: g ′ ( z ) = g ( z ) × ( 1 − g ( z ) ) g'(z)=g(z)\times(1-g(z)) g′(z)=g(z)×(1−g(z))
9. 常见损失函数的作用和用法
- 指导深度学习方向的一盏灯,度量预测结果和实际结果之间的差距
- log loss:伯努利分布,大多数情况等价于交叉熵函数
- dice loss:-dice指数过来的损失函数
- focal loss:log loss的改进版本,乘上了负样本的指数幂次,使得样本均衡一些
- tversky loss:Tversky系数是Dice系数和 Jaccard 系数的一种广义系数,通过调参控制假阳性和假阴性之间的权衡
- generalized dice loss:通过定义每个类别的权重,实现了类似于归一化的操作,解决了样本不平衡的问题
10. 常见的核函数及其解决的问题
- 将数据映射到了高维的空间,使得其能够线性可分或者更容易剔除异常的数据
- 线性核函数: k ( x , y ) = x T y + c k(x,y)=x^Ty+c k(x,y)=xTy+c
- 多项式核函数: k ( x , y ) = ( a x T y + c ) 4 k(x,y)=(ax^Ty+c)^4 k(x,y)=(axTy+c)4
- RBF核函数: k ( x , y ) = e x p ( − ( x − y ) 2 2 σ ) k(x,y)=exp(-\frac{(x-y)^2}{2\sigma}) k(x,y)=exp(−2σ(x−y)2)
- 拉普拉斯核函数: k ( x , y ) = e x p ( − ∣ x − y ∣ σ ) k(x,y)=exp(-\frac{\left|x-y\right|}{\sigma}) k(x,y)=exp(−σ∣x−y∣)
11. TP,FP,TN,FN的解释及常用的评价指标
- 前面的字母表示实际的情况,后面的字母表示预测的情况
- TP:实际为1,预测为1
- FP:实际为0,预测为1
- TN:实际为1,预测为0
- FN:实际为0,预测为1
- Recall = TP/(TP+FN)
- Precision=TP/(TP+FP)
- F 1 = 2 × r e c a l l × p r e c i s i o n r e c a l l + p r e c i s i o n F1=\frac{2\times{recall}\times{precision}}{recall+precision} F1=recall+precision2×recall×precision
- D i c e c o e f f i c i e n t ( A , B ) = 2 A ∩ B A ∪ B Dice coefficient(A, B)=\frac{2{A}\cap{B}}{{A}\cup{B}} Dicecoefficient(A,B)=A∪B2A∩B
12. SVM推导
分为五个步骤:
- 假设超平面
- 正确分类的超平面的条件
- 满足函数间隔最大
- 带参数的优化问题,使用拉格朗日对偶函数解决
- 带回原式得到超平面实现分类
- 软间隔增加了惩罚项,惩罚项越大,支持向量越少,反之同理
- 软间隔的惩罚项约大越容易过拟合
- SVM的损失函数为hinge损失函数加上一个惩罚项,公式近似为: ∑ j ! = y i n m a x ( 0 , s j − s y j + Δ ) \sum\limits_{j!=y_i}^{n}max(0,s_j-s_{y_j}+\Delta) j!=yi∑nmax(0,sj−syj+Δ)
转换为对偶问题的原因:
合并为一个表达式相对简单,解决原函数非凸的情况,引入核函数解决部分线性不可分
13. LR推导
分为以下步骤:
- 根据sigmoid函数构建伯努利分布的概率表达式
- 根据概率表达式构建似然函数
- 根据似然函数构建损失函数(此处和交叉熵损失函数表达式一致)
- 计算导数,根据导数更新参数即可
14. K-MEANS推导
参考链接:https://www.cnblogs.com/bourneli/p/3645049.html
分为以下四个步骤:
- 第1步,随机选取k个中心点
- 第2步,遍历所有数据,将每个数据划分到最近的中心点中
- 第3步,计算每个聚类的平均值(其它博客中提到的质心),并作为新的中心点
- 第4步,重复2-3,直到这k个中线点不再变化(收敛了),或执行了足够多的迭代
以下对于Kmeans的特点的论述内容引用自另一篇博客
- 结果不一定是全局最优,只能保证局部最优
- 对K值敏感
- 对于不是凸的数据集比较难收敛
15. KNN推导
引用自博客:https://zhuanlan.zhihu.com/p/29925372具体的步骤如下:
- 计算已知类别数据集中的点与当前点之间的距离
- 按照距离递增次序排序
- 选取与当前点距离最小的k个点
- 确定前k个点所在类别的出现频率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
四.基础数据结构
1. C++的内存机制
引用自博客:https://blog.csdn.net/isunbin/article/details/93722162
在C++中,内存分成5个区,堆、栈、自由存储区、全局/静态存储区和常量存储区。
| 内存区 | 作用 |
|---|---|
| 堆 | new的对象在这里,若不delete系统自动回收 |
| 栈 | 存放函数内局部变量,集成在CPU上,容量有限 |
| 自由存储 | malloc分配的空间在这里,需要free掉 |
| 全局/静态存储 | 存放全局变量和静态变量 |
| 常量存储 | 不能被修改的常量(const) |
一个原博客中的例子:
void f()
{
int* p=new int[5];
}
在栈内存中新建了一个指向堆的指针
2. C++的继承多态虚函数
参考的原博客:https://www.cnblogs.com/qxxnxxFight/p/11131385.html
根据原博客的例子来说明问题:
定义了三个类,普通飞机(父类),直升机(子类),喷气式飞机(子类)
每个类都有一个叫fly和land的方法代表起飞和降落
因此同名函数的调用会涉及二义性,需要在继承中用虚函数来进行解决
一方面体现了继承,另一方面也体现了多态
具体例子参考原文
虚函数的定义需要注意一下几点:
- 类的成员函数,才能声明为虚函数
- virtual关键字,在虚函数的声明处,类外的实现不需要
- 静态成员函数不能声明为虚函数
- 内联函数不能声明为虚函数
- 构造函数也不能声明为虚函数
- 析构函数可以是虚函数而且通常声明为虚函数
3. 指针的用法及const和引用
const就近修饰,离const近的定义的变量类型对应的值,不能被修改
举例说明:
//定义指向常量的指针
const char * pstr = "str1"
//变量(char类型的)不能被改变,指针指向可以改变
//定义常指针
char * const pstr = "str1"
//指针(pstr)不能被改变,指向的变量的值可以改变
//定义指向常量的常指针
const char * const pstr = "str1"
//指针(pstr)不能被改变,指向的变量的值也不能改变
4. 各种排序算法
主要列举两种,其余的省略
- 快速排序
def par(a, sta, end):
pivot = a[sta]
# 左指针i,右指针j
i, j = sta, end
while i < j:
# 从右往左找第一个比他小的数并交换位置
while i < j and pivot <= a[j]:
j -= 1
a[i] = a[j]
# 从左往右找第一个比他大的数并交换位置
while i < j and pivot >= a[i]:
i += 1
a[j] = a[i]
a[i] = pivot
return i
def quick_sort(a, sta, end):
if sta < end:
pivot = par(a, sta, end)
quick_sort(a, sta, pivot - 1)
quick_sort(a, pivot + 1, end)
else:
return
if __name__ == '__main__':
arr = [6, 2, 7, 3, 8, 9]
quick_sort(arr, 0, len(arr)-1)
print(arr)
- 堆排序,参考链接:https://www.jianshu.com/p/d174f1862601
from collections import deque
def heap_adj(a, sta, end):
key = a[sta]
# i是当前节点的坐标,j是其左子树
i, j = sta, 2*sta
while j < end:
# 左子树小于右子树,让j指向较大的节点
if a[j] < a[j+1]:
j += 1
# 当前的哨兵比较大的子树小,则交换位置,并且更新下标,继续判断
if key < a[j]:
a[i] = a[j]
i = j
j = 2*i
else:
break
# 最后交换哨兵到恰当的位置
a[i] = key
def heap_sort(a):
length = len(a) - 1
first = length >> 1
# 调整大根堆
for i in range(first):
heap_adj(a, first - i, length)
# 交换最后一个元素,继续调整大根堆
for i in range(length - 1):
a[1], a[length - i] = a[length - i], a[1]
heap_adj(a, 1, length - i - 1)
return [a[k] for k in range(1, len(a))]
if __name__ == '__main__':
L = deque([50, 16, 30, 10, 60, 90, 2, 80, 70])
L.appendleft(0)
print(heap_sort(L))
6. 最长公共子序列
d p ( i , j ) = { 0 i = 0 , j = 0 d p ( i − 1 , j − 1 ) + 1 s 1 ( i ) = s 2 ( j ) m a x ( d p ( i − 1 , j ) , d p ( i , j − 1 ) ) o t h e r s dp(i,j)=\left\{ \begin{array}{lr} 0 & i=0, j=0\\ dp(i-1,j-1)+1 & s_1(i)=s_2(j)\\ max(dp(i-1,j), dp(i,j-1)) & others \end{array} \right. dp(i,j)=⎩⎨⎧0dp(i−1,j−1)+1max(dp(i−1,j),dp(i,j−1))i=0,j=0s1(i)=s2(j)others
def find_lcsubstr(s1, s2):
dp = [[0] * (len(s2) + 1) for _ in range(len(s1) + 1)]
s_max = 0
p = 0
for i in range(len(s1)):
for j in range(len(s2)):
if s1[i] == s2[j]:
dp[i + 1][j + 1] = dp[i][j] + 1
if dp[i + 1][j + 1] > s_max:
s_max = dp[i + 1][j + 1]
p = i + 1
return s1[p - s_max:p], s_max
print(find_lcsubstr('abcdfg', 'abdfg'))
7. 最长公共子串
d p ( i , j ) = { 0 i = 0 , j = 0 d p ( i − 1 , j − 1 ) + 1 s 1 ( i ) = s 2 ( j ) 0 o t h e r s dp(i,j)=\left\{ \begin{array}{lr} 0 & i=0, j=0\\ dp(i-1,j-1)+1 & s_1(i)=s_2(j)\\ 0 & others \end{array} \right. dp(i,j)=⎩⎨⎧0dp(i−1,j−1)+10i=0,j=0s1(i)=s2(j)others
def find_lcseque(s1, s2):
dp = [[0]*(len(s2) + 1) for _ in range(len(s1) + 1)]
direction = [[None]*(len(s2) + 1) for _ in range(len(s1) + 1)]
for i in range(len(s1)):
for j in range(len(s2)):
if s1[i] == s2[j]:
dp[i + 1][j + 1] = dp[i][j] + 1
direction[i + 1][j + 1] = 'ok'
elif dp[i + 1][j] > dp[i][j + 1]:
dp[i + 1][j + 1] = dp[i + 1][j]
direction[i + 1][j + 1] = 'left'
else:
dp[i + 1][j + 1] = dp[i][j + 1]
direction[i + 1][j + 1] = 'up'
(i, j) = (len(s1), len(s2))
s = []
while dp[i][j]:
c = direction[i][j]
if c == 'ok':
s.append(s1[i - 1])
i -= 1
j -= 1
if c == 'left':
j -= 1
if c == 'up':
i -= 1
s.reverse()
return ''.join(s)
print(find_lcseque('abdfg', 'abcdfg'))