手把手带撸Junior AlphaGo算法「AI工程论」
关注:决策智能与机器学习,深耕AI脱水干货

作者 | 长风
来源 | 机器学习与数据挖掘实践
强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,包含五大关键要素:agent(智能体),reward(奖励),action(行为),state(状态),environment(环境)。具体而言:agent处在一个环境中,每个状态为机器对当前环境的感知;agent只能通过动作来影响环境,当agent执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。
1. 强化学习简介
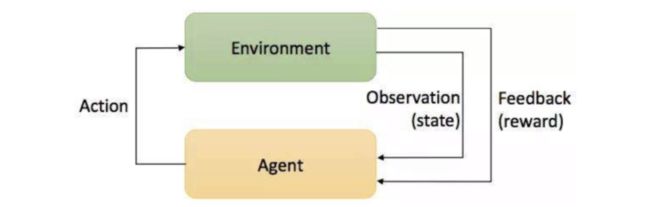
agent:主要涉及到:策略(Policy),价值函数(Value Function)和模型(Model)。Policy,可以理解为行动指南,让agent执行什么动作,在数学上可以理解为从状态state到动作action的映射,可分为确定性策略(Deterministic policy)和随机性策略(Stochastic policy),前者是指在某特定状态下执行某个特定动作,后者是根据概率来执行某个动作。Value Function,对未来总Reward的一个预测。Model,一个对环境的认知框架,可以预测采取动作后的下一个状态是什么,很多情况下是没有模型的,agent只能通过与环境互动来提升策略。
state:可以细分为三种,Environment State,Agent State和Information State。Environment State是agent所处环境包含的信息,简单理解就是很多特征数据,也包含了无用的数据。Agent State是输入给agent的信息,也就是特征数据。Information State是一个概念,即当前状态包含了对未来预测所需要的有用信息,过去信息对未来预测不重要,该状态就满足马尔科夫性(Markov Property)。Environment State,Agent State都可以是Markov Property。
environment:可以分为完全可观测环境(Fully Observable Environment)和部分可观测环境(Partially Observable Environment)。Fully Observable Environment就是agent了解了整个环境,显然是一个理想情况。Partially Observable Environment是agent了解部分环境的情况,剩下的需要靠agent去探索。
2.项目框架和简介
AlphaGo 将AI和围棋强势的摆到大众面前,围棋作为人类的娱乐游戏中复杂度最高的一个,它横竖各有 19 条线,共有 361 个落子点,状态空间高达 10^171,对于新手和强化学习入门不是特友好,而五子棋是博弈游戏当中较简单的一种玩法,规则、赢法都很简单,故此项目初期先对五子棋进行实现,根据进展,后期再逐渐深入。
该项目涉及到的知识主要是强化学习,随着项目进行,我们需要并行的解决相关理论知识:1.强化学习的主要挑战是什么?2.如何用数学术语表示强化学习?3.如何制定长期策略?4.如何估计未来的报酬?5.如何解决状态空间太大的问题?6.如何让强化学习稳定发挥作用?同时阅读 Key Papers in Deep RL
Model-Free RL
Exploration
Transfer and Multitask RL
Hierarchy
Memory
Model-Based RL
Meta-RL
Scaling RL
RL in the Real World
Safety
Imitation Learning and Inverse Reinforcement Learning
Reproducibility, Analysis, and Critique
Bonus: Classic Papers in RL Theory or Review
项目框架
Env: 利用PyQt5编写界面,对棋盘环境进行进行封装
Agent: 处理与环境的交互,并保存历史转移状态等信息
Model: 实现不同的policy,来实现具体的一步下法
具体目录结构如下所示:

3. 功能实现框架
3.1 Environment可视化

Junior AlphaGo实现的棋盘可视化如上图所示,主要利用PyQt5实现以下功能:棋盘初始化,鼠标移动监听,agent调用,落子画图,胜负判断。
class GoBang(QWidget):
def __init__(self):
super().__init__()
self.init_ui()
def init_ui(self):
self.chessboard = ChessState() # 棋盘类
palette1 = QPalette() # 设置棋盘背景
palette1.setBrush(self.backgroundRole(), QtGui.QBrush(
QtGui.QPixmap('img/chessboard.jpg')))
self.setPalette(palette1)
self.setCursor(Qt.PointingHandCursor) # 鼠标变成手指形状
self.resize(WIDTH, HEIGHT) # 固定大小 540*540
self.setMinimumSize(QtCore.QSize(WIDTH, HEIGHT))
self.setMaximumSize(QtCore.QSize(WIDTH, HEIGHT))
self.setWindowTitle("Junior-AlphaGo") # 窗口名称
self.setWindowIcon(QIcon('img/black.png')) # 窗口图标
self.black = QPixmap('img/black.png')
self.white = QPixmap('img/white.png')
self.turn = Color.BLACK
self.pre_x, self.pre_y = 1, 1000
self.mouse_point = LaBel(self) # 将鼠标图片改为棋子
self.mouse_point.setScaledContents(True)
tmp = self.black if HUMAN_FIRST else self.white
self.mouse_point.setPixmap(tmp) # 加载黑棋
self.mouse_point.setGeometry(270, 270, PIECE, PIECE)
self.pieces = [LaBel(self) for i in range(225)] # 新建棋子标签,准备在棋盘上绘制棋子
for piece in self.pieces:
piece.setVisible(True) # 图片可视
piece.setScaledContents(True) # 图片大小根据标签大小可变
self.mouse_point.raise_() # 鼠标始终在最上层
self.ai_down = True # AI已下棋,主要是为了加锁,当值是False的时候说明AI正在思考,这时候玩家鼠标点击失效,要忽略掉 mousePressEvent
self.setMouseTracking(True)
self.show()
if not HUMAN_FIRST:
self.call_ai()
3.2 agent 和 Environment交互
上文中的启动界面的线程暂称为UI线程,界面执行命令时都在自己的UI线程中。如果我们在UI线程中执行比较复杂的操作(网络计算,大计算量),如果在UI线程中执行网络连接和数据库操作等耗时的操作,界面会被卡住,Windows下有可能会出现“无响应”的警告。阻塞UI线程会降低用户体验和应用稳定性。因此我们可以把agent的计算操作放在线程中去执行,继承PyQt中的线程类
QtCore.QThread ,我们可以复写run函数来执行我们要的操作。
QThread可以使用 QtCore.pyqtSignal 来与environment交互和传输数据,将当前的棋盘信息(state)传入,然后将当前策略计算的结果(在哪个点位落子)返回,并在环境中画出。
class AI(QtCore.QThread):
"""定义线程类执行AI的算法
"""
finishSignal = QtCore.pyqtSignal(int, int)
def __init__(self, state, role, parent=None):
super(AI, self).__init__(parent)
self.agent = NaiveAgent(15, 15, role)
#self.agent = SarsaAgent(15, 15, role, False, 'model/sarsa_default_2019-11-21_17:54:09.ckpt-226184')
self.x, self.y, _ = self.agent.interact(None, state, False, True)
def run(self):
self.finishSignal.emit(self.x, self.y)
3.3 agent 和 用户相互落子
def mousePressEvent(self, e): # 玩家下棋
if e.button() == Qt.LeftButton and self.ai_down:
x, y = e.x(), e.y() # 鼠标坐标
i, j = self.pixel2coordinate(x, y) # 对应棋盘坐标
if i is not None and j is not None: # 棋子落在棋盘上,排除边缘
if self.chessboard._state[i][j] == Color.EMPTY: # 棋子落在空白处
if self.draw(i, j):
self.call_ai()
4. 总结
本文完成agent框架和environment的实现,并将environment可视化,后续强化学习的相关算法只需要在agent进行迭代即OK。
交流合作
请加微信号:yan_kylin_phenix,注明姓名+单位+从业方向+地点,非诚勿扰。
