Hbase基础全解析
HBASE基础全解析
标签: 大数据生态
本文使用版本 hbase-0.98.6-cdh5.3.6
源码库: https://github.com/apache/hbase/releases
注:rel = release即发行版本 , RC=Release Candidate即候选发行版
Write By VinFly
HBASE概述
HBASE概述
HBASE是HADOOP数据库,是一个分布式的,可扩展的,存储海量数据的数据库,存储级别一般为数十亿行及数百万列的数据,它是一个非关系型数据库,能随机、实时读写,部署在低廉的商用机上(扩展性好),基于高可用性的分布式系统。
HBASE数据表结构
HBASE是以表的形式存储数据,表有行和列组成,列划分为若干个列族(Column Family)。
在HBASE的表中,Row Key的设计是表中每条记录的“主键”,在查询HBASE中的数据时,也是根据Row Key来查询,所以Row Key的设计非常重要,Row Key的值在表中以字节数组的类型存储。HBASE表结构如下图所示。 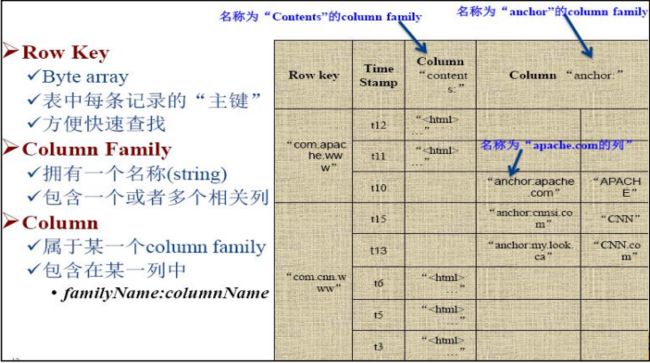
数据表结构详解:
- Row Key
与nosql数据库们一样,row key是用来检索记录的主键。访问hbase table中的行,只有三种方式:
- 通过单个rowkey访问 (get)
- 通过rowkey的range (scan)
- 全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,row key保存为字节数组。
存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
- 列族(Column Family)
hbase表中的每个列,都归属与某个列族。列族是表的schema的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history , courses:math 都属于 courses 这个列族。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能 帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因 为隐私的原因不能浏览所有数据)。
- 时间戳(Time Stamp)
HBase中通过row和columns确定的为一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。maxversion=3 verson=1
- Cell
唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮{rowkey, column( =+
HBASE安装部署及简单SHELL使用
1、下载、解压源码包
使用HBASE要注意其与Hadoop的兼容性,本文使用CDH5.3.6版本的HBASE及HADOOP,下载地址:
http://archive.cloudera.com/cdh5/cdh/5/
下载完成后上传Hbase压缩包,赋予执行权限,解压至指定目录
2、配置
检查jdk是否正确(jdk版本使用1.7以上),启动hadoop,检查dfsadmin是否脱离安全模式 
配置{HBASE_HOME}/conf下的hbase-enc.sh export JAVA_HOME=/opt/modules/jdk1.7.0_67
export HBASE_MANAGES_ZK=false
其中的export HBASE_MANAGES_ZK=false是配置是否使用HBASE自带的zookeeper
配置{HBASE_HOME}/conf下的hbase-site.xml
首先在hbase目录下创建目录(可以在任意目录下):
mkdir -p data/tmp
配置hbase.tmp.dir属性值为创建的目录 
配置hbase.root.dir指定存储的数据在HDFS上的目录 
配置hbase.cluster.distributed值为true,指定是否为分布式模式 
配置hbase.zookeeper.quorum ,这里配置的是zookeeper所在机器,在设置了主机名与IP地址映射之后,这里写的是主机名,中间用逗号隔开。 
配置{HBASE_HOME}/conf下的regionservers,这里配置的是regionserver所在机器,根据需要自己设定。 
注:如果下载的hbase版本与使用的hadoop版本不兼容,替换掉{HBASE_HOME}/lib下的hadoop jar包即可。
到这里基本的配置就完成了,如果有其他参数要求,参考官网。
地址:http://hbase.apache.org/book.html#config.files
3、启动与shell基本使用
启动命令: ${HBASE_HOME}/bin/hbase-daemon.sh start master ${HBASE_HOME}/bin/hbase-daemon.sh start regionserver
查看启动的进程: 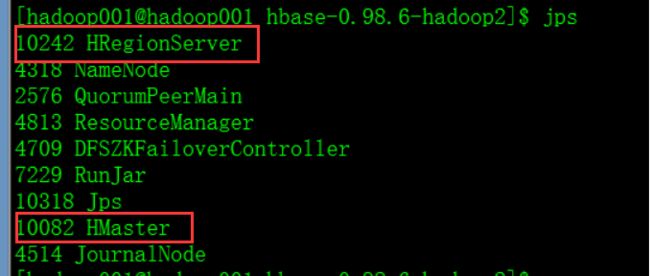
启动Hbase命令行:bin/hbase shell 
在命令行中,如果不熟悉某个命令,可以使用 help:查看帮助信息 比如help+’create’查看create命令使用方法
基本命令举例
创建表 create 'user', 'info' //创建user表,列族名为info
PUT/UPDATE //插入数据 put 'user', '100001', 'info:name', 'zhangsan' 
查询
get
依据ROWKEY进行查询,速度最快的 get 'user', '100001' 
scan
全表扫描,也就测试用用,实际慎用 scan 'user'
scan range
范围查询
使用最多最广泛 scan 'user' , {STARTROW => ‘100001’} 
HBASE也有它的端口号,默认为60010,可在浏览器中监控HBASE运行状况。 
HBASE的物理结构
首先看HBASE的物理模型图 
从图中可以看出一下几点:
- 在HBASE的表中,所有的行都是按照Row Key的字典序排列(a~z,1~9…)
在行的方向上分割为多个Region,而Region是按大小进行分割的,每个表初始只有一个Region,随着数据的增多,Region不断增大,当增大到一定阀值得时候,Region就会等分为两个新的Region

Region是HBASE中分布式存储的最小单元,不同的Region分布到不同的RegionServer上

Region是分布式存储的最小单元,但它不是存储的最小单元,Region又由一个或者多个Store组成,每个Store保存一个column family,每个Store由一个memStore和0到多个StoreFile组成,其中的memStore存储在内存中,StoreFile存储在HDFS文件系统上。

- HBASE在HDFS上的存储
HBASE中所有数据文件都存储在了HDFS文件系统上,HBASE主要包括两种文件类型:
HFile:HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上上面提到的StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile
HLog File:HBASE中的WAL(Write Ahead Log :预写日志)的存储格式,物理上是Hadoop的Sequence File,具体的WAL将在后面讲解。
HBASE架构
HBase架构也是主从服务器架构,它由HRegion服务器(HRegion Server)群和HBase Master服务器(HBaseMaster Server)构成。HBase Master服务器负责管理所有的HRegion服务器,而HBase中所有的服务器都是通过ZooKeeper来进行协调,并处理HBase服务器运行期间可能遇到的错误。HBase Master Server本身不存储HBase中的任何数据,HBase中的表可能会被划分为多个HRegion,然后存储到HRegion Server群中,HBase Master Server中存储的是从数据到HRegionServer中的映射。
HBASE架构见图 
HBASE架构中的组件解析
Client
客户端Client是整个集群的访问入口
Client使用HBase RPC机制与HMaster和HRegionserver进行通信
与HMaster进行通信进行管理类操作
与HRegionserver进行数据读写类操作
包含访问HBase的接口,并维护cache来加快对HBase的访问
协作组件zookeeper
zookeeper作为一个大数据协作框架,它的HBASE中的地位相当重要。
1、 zookeeper管理着HBASE的meta表的region等相关信息,那么何谓meta表?
在HBASE中,有命名空间——NAMESPACE的概念,它类似于数据库,我们用户自定义的表存储在名为default的namespace下,而meta表是hbase自带的系统表,它存储在名为hbase的命名空间下,见图。
其中的user table是我们自定义的表,而catalog tables是系统自带的表,那么meta表中存储的是什么数据呢?
通过完整的hbase命令hbase(main):005:0> scan 'hbase:meta'查看meta表中的信息
在这个meta表中可以看到user表的信息,比如user表的某个region存储在了哪个regionserver上,region的startRowKey和endRowKey等信息。但是meta表也是HBASE中的一张表,它也遵循HBASE表的一般特性,那么它也有自己的region,比如某个region存储某张用户自定义的表,这些region的信息(表名、表的唯一标识符、startRowKey、endRowKey/存储在哪个regionserver上…)存储在哪里呢?
这里我们进入zookeeper的znode里面查看zookeeper存储的一些数据
使用命令:bin/zkCli.sh->ls->ls /hbase
在这里可以看到zookeeper存储了关于hbase的数据,其中的meta-region-server中就是存储了hbase中meta表的region的相关数据。所以,这里我们总结出对HBASE中数据操作的流程:
client->zookeeper->meta-region-server->regionServer上meta数据查找具体Regioin
2、 zookeeper中存储了监控着regionserver是否存活的数据,见图。也就是说,zookeeper实时监控了Hregionserver的上线和下线信息,并通知给HMaster。
3、 zookeeper保证了在任何时候,集群只有一个HMaster,如果一个HMaster宕掉,那么zookeeper会通过它的选举机制再重新选取一个regionserver作为新的HMaster,所以HBase集群不会有单节点故障。





主节点HMaster
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改查操作
Client访问hbase中的数据的过程并不需要master参与(寻址访问的是zookeeper和Regionserver,数据读写访问的是HRegionserver),HMaster仅仅维护元数据信息,负载很低。
HRegionserver
1、维护HRegion,处理这些Region的IO请求,向HDFS文件系统中读写数据
2、负责切分在运行过程中变大的HRegion
3、一台机器上面一般只运行一个HRegionServer,且每一个区段的HRegion也只会被一个HRegionServier维护
4、当用户需要更新数据的时候,他会被分配到对应的HRegionServer上提交修改,这些修改先是被写到memStore(内存中的缓存,保存最近更新的数据)缓存和服务器的Hlog(磁盘上面的记录文件,它记录着所有的更新操作)文件里面。在操作写入Hlog之后,commit()调用才会将其返回给客户端。
5、在读取数据的时候,HRegionServier会先访问memStore缓存,如果缓存里没有改数据,才会回到Store磁盘上面寻找,每一个列族都会有一个Store集合,每一个Store集合包含很多storeFile(封装了Hfile)文件
HBASE的数据存储
数据存储原理
这里首先介绍一下LSM树(log-structured merge-tree)
输入数据首先被存储在日志文件,这些文件内的数据完全有序。当有日志文件被修改时,对应的更新会被先保存在内存中来加速查询。当系统经历过许多次数据修改,且内存空间被逐渐被占满后,LSM树会把有序的“键-记录”对写到磁盘中,同时创建一个新的数据存储文件。此时,因为最近的修改都被持久化了,内存中保存的最近更新就可以被丢弃了。
存储文件的组织与B树相似,不过其为磁盘顺序读取做了优化,所有节点都是满的并按页存储。修改数据文件的操作通过滚动合并完成,也就是说,系统将现有的页与内存刷写数据混合在一起进行管理,直到数据块达到它的容量
在内存中多个块存储归并到磁盘的过程,合并写入会产生一个新的结果块,最终多个块被合并为更大块。
多次数据刷写之后会创建许多数据存储文件,后台线程就会自动将小文件聚合成大文件,这样磁盘查找就会 被限制在少数几个数据存储文件中。磁盘上的树结构也可以拆分成独立的小单元,这样更新就可以被分散到多个数据存储文件中。所有的数据存储文件都按键排序, 所以没有必要在存储文件中为新的键预留位置。
查询时先查找内存中的存储,然后再查找磁盘上的文件。这样在客户端看来数据存储文件的位置是透明的。
删除是一种特殊的更改,当删除标记被存储之后,查找会跳过这些删除过的键。当页被重写时,有删除标记的键会被丢弃。
此外,后台运维过程可以处理预先设定的删除请求。这些请求由TTL(time-to-live)触发,例如,当TTL设为20天后,合并进程会检查这些预设的时间戳,同时在重写数据块时丢弃过期的记录。

根据LSM树的原理,可以总结出:在HBASE中数据写入的流程如下:
Client写入 ->存入memStore,一直到memStore满->Flush成一个StoreFile,直到成长到一定阀值->出现Compact合并操作->多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除->当StoreFile Compact合并后,逐步形成一个大的StoreFile->单个StoreFile超过一定阀值后,触发split操作,把当前的Region split成两个region,老region会下线,新Split出的两个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先一个Region压力得以分流到2个Region上
注:所有的更新和删除操作,都是在Compact阶段做的,所以,用户写操作只需要进入到内存即可,从而保证了IO高性能。
WAL(write-ahead-log)
WAL即为预写日志,它的存储格式是HLog File,WAL主要用作数据恢复,类似于MYSQL中的binlog。
HLog记录着数据的变更,一旦数据更改,就可以通过log进行恢复,每个HRegionserver维护一个HLog,而不是每个Region一个 ,这样不同的Region(来自不同的表)的日志会混在一起,这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此提高对table的写性能,但是带的缺点是,如果一台Regionserver下线,为了恢复其上的region,需要将该Regionserver的HLog进行拆分,然后分发到其它Regionserver上进行恢复。
WAL的处理流程如下:
首先客户端启动一个操作来修改数据。例如,可以对put()、delete()和increment()进行调用。每一个修改都封装到一个KeyValue对象实例中,并通过RPC调用发送出去。这些调用(理想情况下)成批地发送给含有匹配region的HRegionServer。一旦KeyValue实例到达,它们会被发送到管理相应行的HRegion实例。数据被写入到WAL,然后被放入到实际拥有记录的存储文件的MemStore中。实质上,这就是HBase大体的写路径。最后,当memstore达到一定的大小或是经历一个特定的时间之后,数据就会异步地连续写入到文件 系统中。在写入的过程中,数据以一种不稳定的状态存放在内存中,即使在服务器完全崩溃的情况下,WAL也能够保证数据不会丢失,因为实际的日志存储在HDFS上。其他服务器可以打开日志文件然后回放这些修改—恢复操作并不在这些崩溃的物理服务器上进行。
HBASE的JAVA API基本使用
在IDE或者IDEA环境中开发HBASE都使用MAVEN工程来进行管理,所以在开发代码前要做以下几步:
1、 在Maven工程中的 pom.xml 文件中添加HBASE依赖
<hbase.version>0.98.6-hadoop2hbase.version>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>${hbase.version}version>
dependency>2、确定maven工程中依赖包里有Hbase jar包,并拷贝
${HADOOP_HOME} /conf下的core-site.xml、hdfs-site.xml配置文件以及${HBASE_HOME}/conf下的hbase-site.xml配置文件到maven工程中,确保所有regionserver启动,master启动即可在eclipse下运行java application
添加数据到HBASE
package hbase_study;
import .......
public class HBaseClientApp {
public static HTable getHTableByTableName(String tableName)throws Exception{
// Get instance of Configuration
Configuration configuration = HBaseConfiguration.create();
// Get table instance
HTable table = new HTable(configuration, tableName) ;
// System.out.println(table);
return table ;
}
public static void putData() throws Exception{
String tableName = "user" ;
HTable table = getHTableByTableName(tableName) ;
// create put instance
Put put = new Put(Bytes.toBytes("100002")) ;
// add a column with value
put.add(
Bytes.toBytes("info"),
Bytes.toBytes("name"),
Bytes.toBytes("lisi")
);
put.add(
Bytes.toBytes("info"),
Bytes.toBytes("age"),
Bytes.toBytes("22")
);
put.add(
Bytes.toBytes("info"),
Bytes.toBytes("sex"),
Bytes.toBytes("female")
);
put.add(
Bytes.toBytes("info"),
Bytes.toBytes("address"),
Bytes.toBytes("nanjing")
);
put.add(
Bytes.toBytes("info"),
Bytes.toBytes("tel"),
Bytes.toBytes("188888888")
);
// put data into table
table.put(put);
// close
table.close();
}查询数据(get Row Key)
/**
* Get Data From Table By ROWKEY
*
* @throws Exception
*/
public static void getData() throws Exception{
String tableName = "user" ;
//
HTable table = getHTableByTableName(tableName) ;
/**
* get 'user', '10001', 'info:name'
*/
// Create Get with rowkey
Get get = new Get(Bytes.toBytes("1001")) ;
/*
get.addColumn(//
Bytes.toBytes("info"),//
Bytes.toBytes("name") //
) ;
*/
// Get Data
Result result = table.get(get);
// System.out.println(result);
/**
* Key:
* rowkey + cf + c + version
* Value:
* value
*/
for(Cell cell : result.rawCells()){
System.out.println(//
// column family
Bytes.toString(CellUtil.cloneFamily(cell))
+ ":"
// column
+ Bytes.toString(CellUtil.cloneQualifier(cell))
+ "->"
// value
+ Bytes.toString(CellUtil.cloneValue(cell))
+ " "
// timestamp
+ cell.getTimestamp()
);
System.out.println("=============================");
}
// close
table.close();
}查询数据(scan)
/**
* Scan Data
*
* @throws Exception
*/
public static void scanData() throws Exception{
String tableName = "user" ;
//
HTable table = null ;
ResultScanner resultScanner = null ;
try{
//
table = getHTableByTableName(tableName) ;
//
Scan scan = new Scan() ;
//==========================================================
// Range
// scan.setStartRow(startRow) ; // 2016070112000000_
// scan.setStopRow(stopRow) ; // 2016070113000000_
//==========================================================
// Range
// iterator
// Scan scan2 = new Scan(startRow, stopRow) ;
// add Column
// scan.addColumn(family, qualifier) ;
// scan.addFamily(family) ;
// Filter
// Filter filter = new PrefixFilter(prefix) ;
// scan.setFilter(filter) ;
// page
// PageFilter
//
// 是否缓存查询出来的数据
// scan.setCacheBlocks(false);
//
// scan.setCaching(2);
scan.setBatch(2);
// scan all table
resultScanner = table.getScanner(scan) ;
for(Result result : resultScanner){
System.out.println(Bytes.toString(result.getRow()));
for(Cell cell : result.rawCells()){
System.out.println(//
// column family
Bytes.toString(CellUtil.cloneFamily(cell))
+ ":"
// column
+ Bytes.toString(CellUtil.cloneQualifier(cell))
+ "->"
// value
+ Bytes.toString(CellUtil.cloneValue(cell))
+ " "
// timestamp
+ cell.getTimestamp()
);
}
System.out.println("=============================");
}
}catch(Exception e){
e.printStackTrace();
}finally{
IOUtils.closeStream(resultScanner);
IOUtils.closeStream(table);
}
}删除HBASE中的数据
/**
* Delete Data
*
* @throws Exception
*/
public static void deleteData() throws Exception{
String tableName = "user" ;
//
HTable table = getHTableByTableName(tableName) ;
//
Delete delete = new Delete(Bytes.toBytes("1004")) ;
/*
delete.deleteColumn(
Bytes.toBytes("info"),//
Bytes.toBytes("address") //
) ;
*/
// delete data
table.delete(delete);
// close
table.close();
} HBASE与MapReduce集成
HBASE与MapReduce集成的三种方式:
1、input - source ==== 从HBase表中读取数据
2、output - sink ==== 将MapReduce的计算结果存储到HBase表中
3、input & output - source & sink ====既从HBase表中读取数据,又向HBase表中存储数据,mapreduce程序可以看作是hbase的一个客户端
1、运行测试HBASE自带的mapreduce例子
首先测试运行: [vin@vin01 hbase-0.98.6-cdh5.3.6]$ /opt/modules/hadoop-2.5.0-cdh5.3.6/bin/yarn jar lib/hbase-server-0.98.6-cdh5.3.6.jar 
发现报错,原因是mapreduce运行需要HBASE的jar包,我们通过执行bin/hbase mapredcp来查看需要哪些jar包,而解决这些jar包的方法就是设置classpath:
参考官网:http://hbase.apache.org/book.html#hbase.mapreduce.classpath
设置方式:
export HADOOP_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6
export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.6
export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath`设置完成之后再测试运行该jar包: 
可以看出该jar包中有多个实例,这里再测试运行rowcounter来计算user表:
执行:
export HADOOP_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6
export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.6
export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath`
/opt/modules/hadoop-2.5.0-cdh5.3.6/bin/yarn jar lib/hbase-server-0.98.6-cdh5.3.6.jar rowcounter user测试结果: 
测试既从HBase表中读取数据,又向HBase表中存储数据
这里就需要使用MAVEN工程来开发mapreduce程序了,代码如下:
package hbase_study;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ExportBasicFromUserMapReduce extends Configured implements Tool {
// step 1: Mapper
/**
* Mapper
*/
public static class ReadFromUserMapper
extends TableMapper<ImmutableBytesWritable, Put> {
@Override
public void map(ImmutableBytesWritable key, Result value, Context context)
throws IOException, InterruptedException {
// get rowkey
// String rowkey = Bytes.toString(key.get()) ;
// create put
Put put = new Put(key.get());
// iterator
for (Cell cell : value.rawCells()) {
// add family: info
if ("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))) {
// add column : name
if ("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
put.add(cell);
}
// add column : age
else if ("age".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
put.add(cell);
}
}
}
// output
context.write(key, put);
}
}
// step 2: Reducer
/**
* Reducer
*/
public static class WriteToBasicReducer
extends TableReducer<ImmutableBytesWritable, Put, ImmutableBytesWritable> {
@Override
public void reduce(ImmutableBytesWritable key, Iterable values,
Context context) throws IOException, InterruptedException {
for(Put put : values){
// output
context.write(key, put);
}
}
}
// step 3: Driver
public int run(String[] args) throws Exception {
// 1) get conf
Configuration conf = super.getConf();
// 2) create job
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(ExportBasicFromUserMapReduce.class);
// 3) set job
// input & mapper
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
TableMapReduceUtil.initTableMapperJob(
"user", // input table
scan, // Scan instance to control CF and attribute selection
ReadFromUserMapper.class, // mapper class
ImmutableBytesWritable.class, // mapper output key
Put.class, // mapper output value
job //
);
// reducer & output
TableMapReduceUtil.initTableReducerJob(
"basic", // output table
WriteToBasicReducer.class, // reducer class
job //
);
job.setNumReduceTasks(1); // at least one, adjust as required
// 4) submit job
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
/**
* Entry
*
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// create conf
Configuration configuration = HBaseConfiguration.create();
// run job
int status = ToolRunner.run( //
configuration, new ExportBasicFromUserMapReduce(), args);
// exit program
System.exit(status);
}
} 上述代码完成的功能是编写mapreduce从user表中查询抽取某些字段到basic表中
代码编写完成,打成jar包 
上传该jar包并运行:
export HADOOP_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6
export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.6
export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath`
/opt/modules/hadoop-2.5.0-cdh5.3.6/bin/yarn jar mr-user2basic.jar hbase_study.ExportBasicFromUserMapReduce注:上述shell代码是在$HBASE_HOME主目录下执行的,上传的jar包也在该主目录下,所以省略了路径,在实际运行中应该写上jar的绝对路径。
HBASE的数据迁移
HBASE的数据来源一般就是Logs 、 RDBMS,或者本身的备份。
1)数据迁移几种方式:
1、PUT API 写入数据
这种方式主要是通过编写mapreduce,通过连接JDBC,将RDBMS关系型数据库中的数据迁移到HBASE中,编写过程复杂,这里我们使用HBASE自带的一个mapreduce来测试将以制表符分隔的tsv格式的文件导入到HBASE表中,该mapreduce也在自带的jar包中,见图。
测试运行:
查看其用法:/opt/modules/hadoop-2.5.0-cdh5.3.6/bin/yarn jar lib/hbase-server-0.98.6-cdh5.3.6.jar importtsv
测试步骤:


- 首先在hbase创建表:create ‘person’ ,‘info’ 用来存放要导入的数据
- 将tsv数据上传到hdfs文件系统中,本文使用的是
/user/hadoop001/hbase/data/importtsv/目录 运行:
export HADOOP_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6 export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.6 export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf \ /opt/modules/hadoop-2.5.0-cdh5.3.6/bin/yarn jar lib/hbase-server-0.98.6-cdh5.3.6.jar importtsv \ -Dimporttsv.columns=HBASE_ROW_KEY,\ info:name,info:age,info:sex,info:address \ person \ /user/hadoop001/hbase/data/importtsv说明:通常MapReduce在写HBASE时使用的是TableOutputFormat方式,在reduce中直接生成put对象写入Hbase,该方式在大数据量时写入效率低下,HBase会Block写入,频繁进行flush、split、compact等大量IO操作,并对HBase节点的稳定性造成一定影响。
2、使用bulk load tool
过程:先将数据转换为HFile格式文件,然后将HFile文件加载到HBase表中。
BULK LOAD 是利用HBase的数据信息按照特定格式存储在HDFS内这一原理,直接在HDFS中生成持久化的HFile数据格式文件,然后上传至合适位置,完成了海量数据快速入库的方式,配合mapreduce完成, 高效便捷,不占用region资源,消除看对HBase集群插入数据的压力,提高了job运行效率。
在hbase-server-0.98.6-cdh5.3.6.jar中的importtsv方法也具有bulkload功能,见图。下面对它进行测试
测试步骤:设置HFile存储的目录(该目录会自动创建)
-Dimporttsv.bulk.output=/user/hadoop001/hbase/hfileOutput
要处理的数据仍然为/user/hadoop001/hbase/data/importtsv目录下的student.tsv文件- 运行代码,生成HFile文件
export HADOOP_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6
export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.6
export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf \
/opt/modules/hadoop-2.5.0-cdh5.3.6/bin/yarn jar lib/hbase-server-0.98.6-cdh5.3.6.jar importtsv \
-Dimporttsv.bulk.output=/user/hadoop001/hbase/hfileOutput \
-Dimporttsv.columns=HBASE_ROW_KEY, \
info:name,info:age,info:sex,info:address \
person \
/user/hadoop001/hbase/data/importtsv

- 加载HFile数据到HBase表中
export HADOOP_HOME=/opt/modules/hadoop-2.5.0-cdh5.3.6
export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.6
export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf \
${HADOOP_HOME}/bin/yarn jar \
${HBASE_HOME}/lib/hbase-server-0.98.6-hadoop2.jar completebulkload \
/user/hadoop001/hbase/hfileOutput \
person通过运行此条命令,会将/user/hadoop001/hbase/hfileOutput下的文件剪切到/hbase/data/default/person/0731f5632f614b5bfdc2381353eb2d70/目录下 
这时我们通过查看HBASE表,就可以看到数据被成功的加载到其中了。
3、 编写mapreduce的固定模式 
HBASE表的设计
- HBASE创建表的方式及预分区
通过在HBASE SHELL命令行中输入help 'create'可以查看创建表的方法及其常用属性 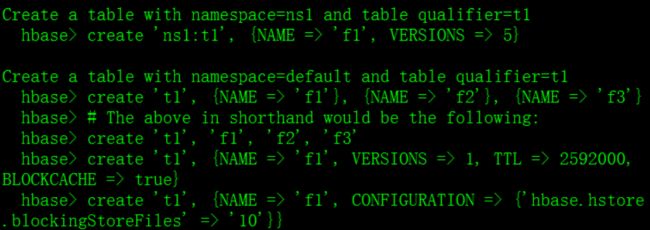

从HBASE给出的示例中可以总结:
- 创建的表可以有多个列族,列族可以有多个属性
- split
在HBASE中,前面我们谈过了其数据来源有两种,一种是日志文件写入,一种是将文件转换成HFile,通过BULK load导入到HBASE表中,但是我们知道HBASE初始给表设计的是一个Region,而Bulk Load 短时间将大量的数据文件写入到Region,所以管理这个Region的Regionserver负载会非常大,可能会造成节点损坏,那么解决办法就是在创建表的时候指定多个Region(根据表的Row Key进行设计,结合实际业务)。那么如何在创建表的时候创建多个Region呢?
split就是对HBASE表的预分区,分区是相对于region而已,而Region的划分是根据Row Key划分的,[startRow , endRow)
测试split:
create 'ns1:t1', 'f1', SPLITS => ['10', '20', '30', '40']

这其中的’10’, ‘20’, ‘30’, ‘40’就是预估的分区,这里还可以将分区写入到文件中,然后创建表的时候加载该文件即可,在创建很多个region的时候使用这个方式:
hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt'
文件中的格式为
10
20
30
40- 在设计表的时候,某些不常用但是有需求的业务表设计成索引表,索引表的某个列必须是主表的RowKey,而实现主表与索引表的数据同步需要使用Phoenix的JDBC方式。
2.RowKey的设计原则
- rowkey长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以 byte[] 形式保存,一般设计成定长。
建议越短越好,不要超过16个字节,原因如下:
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
- rowkey散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
- rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
- 什么是热点
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
下面是一些常见的避免热点的方法以及它们的优缺点:
- 加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
- 哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
- 反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
- 时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如 [key][reverse_timestamp] , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。
比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计
[userId反转][Long.Max_Value - timestamp],在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是[userId反转][000000000000],stopRow是[userId反转][Long.Max_Value - timestamp]
如果需要查询某段时间的操作记录,startRow是[user反转][Long.Max_Value - 起始时间],stopRow是[userId反转][Long.Max_Value - 结束时间]
- 其他一些建议
尽量减少行和列的大小在HBase中,value永远和它的key一起传输的。当具体的值在系统间传输时,它的rowkey,列名,时间戳也会一起传输。如果你的rowkey和列名很大,甚至可以和具体的值相比较,那么你将会遇到一些有趣的问题。HBase storefiles中的索引(有助于随机访问)最终占据了HBase分配的大量内存,因为具体的值和它的key很大。可以增加block大小使得storefiles索引再更大的时间间隔增加,或者修改表的模式以减小rowkey和列名的大小。压缩也有助于更大的索引。
- 列族尽可能越短越好,最好是一个字符
冗长的属性名虽然可读性好,但是更短的属性名存储在HBase中会更好
HBASE表的压缩属性配置
压缩 首先在HBASE SHELL中输入`describe ‘user’`来查看user表的信息: ![image_1arcl4ca6gifhcqn6n1vm1i9u9.png-72.5kB][39] 其中的COMPRESSION =’NONE’表示的表的存储是否使用压缩,而HBASE数据是存储在HDFS上的,检查hadoop支持哪些压缩格式: `bin/hadoop checknative`
配置HBASE压缩步骤(以常用的压缩格式snappy为例):
– 配置hadoop压缩
使用bin/hadoop checknative检查
–配置HBASE
1、将hadoop与snappy集成的jar包放入HBASE安装目录下的lib目录中
2、将本地native库放入HBASE安装目录中
–在hbase-site.xml文件中配置压缩属性 
–在做好上面步骤好,就可以在表中将压缩属性设置为想要的压缩格式
注:已经存在的数据不会因为设置压缩属性而压缩
HBASE与Hive集成
参考官网: https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration
喜欢我的文章请关注微信公众号DTSpider
