SRNTT:Image Super-Resolution by Neural Texture Transfer
Image Super-Resolution by Neural Texture Transfer
Zhifei Zhang,Zhaowen Wang,Zhe Lin,Hairong Qi
CVPR2019
摘要
之前提出的RefSR的方法虽然很有潜力,但是存在一些问题,一旦RefSR与LR不够相似的时候超分辨率的结果就很差。论文为了充分发挥RefSR的作用。不仅只学习RefSR的像素级的文本信息还同时学习多个层次的信息。
主要贡献
- 论文学会用RefSR的思想,打破了SISR的束缚。(其实就是不再单纯地学习HR和LR的映射,而是引入RefSR)
- 论文提出了SRNTT,可以得到更好的超分辨率效果。
- 论文建立了一个新的数据集,CUFED5,对LR有不同相似程度的RefSR,用来进行进一步探索。
相关工作
SISR工作存在的问题:
- 纹理不够清晰。
- 加上感知损失,纹理清晰了但是大多是捏造的,不符合真实情况。
基于Ref的SR存在的问题:
- Ref需要跟LR足够相似。
- 只学习了Ref的像素级特征,或者一些浅层的特征。
- Ref需要与LR对齐的。
为了得到更真实纹理的高分辨率图像,论文提出了SRNTT。
主要方法
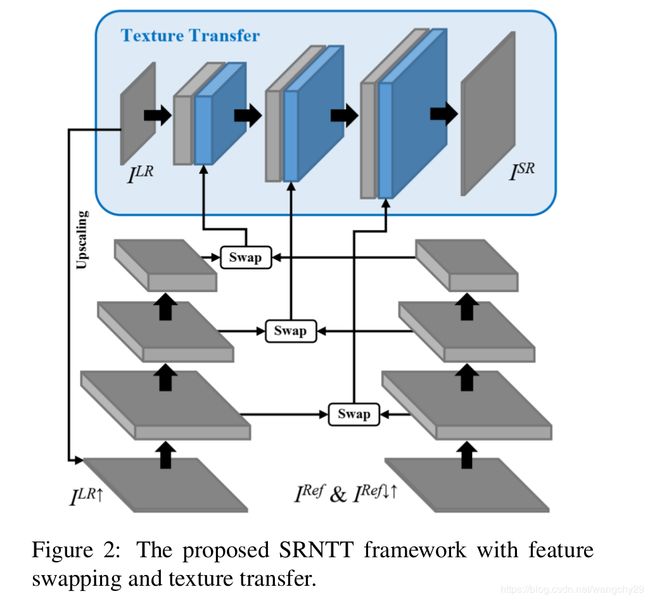
网络结构如上图。
特征交换
特征交换这一部的主要工作就是在Ref中找到与LR最接近的块,然后替换掉LR中的块。这就涉及两个步骤(1)如何计算相似度(2)如何交换对应块。
(1)如何计算相似度
论文提出的方法不是计算整个图的相似度,而是分块计算。这里因为LR和Ref的大小不同,先对LR用bicubic进行上采样使LR和Ref具有相同的大小,而同时考虑到二者的分辨率不同,对Ref用bicubic进行下采样再上采样,使得![]() 的模糊程度跟
的模糊程度跟![]() 接近。
接近。
考虑到![]() 和
和![]() 的块在颜色和光照上面可能有些不同,于是论文不直接对Patch的像素进行计算相似度,而在高层次的特征图上计算,即
的块在颜色和光照上面可能有些不同,于是论文不直接对Patch的像素进行计算相似度,而在高层次的特征图上计算,即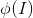 ,来突出结构和纹理信息。
,来突出结构和纹理信息。
论文采用内积方法来计算相似度:
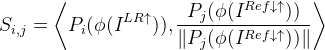
![]() 表示第i块,而从公式中可以看出
表示第i块,而从公式中可以看出![]() 的块被规范化了。
的块被规范化了。
而对于整个![]() 计算相似度的操作也就相当于是将
计算相似度的操作也就相当于是将![]() 的j块当做卷积核的卷积操作。
的j块当做卷积核的卷积操作。
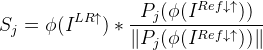
![]() 即
即![]() 第j个块得到的相似度map。
第j个块得到的相似度map。
定义![]() 表示以(x,y)为中心的
表示以(x,y)为中心的![]() 块和
块和![]() 的第j块得到的相似度图。
的第j块得到的相似度图。
(2)交换操作
![]()
![]() 指的是索引,即以(x,y)为中心的块的索引,M是交换后得到的特征图,这个公式的意思先找到
指的是索引,即以(x,y)为中心的块的索引,M是交换后得到的特征图,这个公式的意思先找到![]() 与
与![]() 相似度最大的那个块,找到
相似度最大的那个块,找到![]() 中对应的块的特征图来做M的
中对应的块的特征图来做M的![]() 块。
块。
如果有重叠的部分,就取均值。
Neural Texture Transfer
这一结果的主要功能就是将这些不同规模和大小的M和深度学习结合起来。
论文采用残差块和跳跃连接来建立基本的生成网络。记![]() 是第l层的输出,可以定义为:
是第l层的输出,可以定义为:
![]()
![]() 即2倍上采样。
即2倍上采样。![]() 表示通道连接。
表示通道连接。
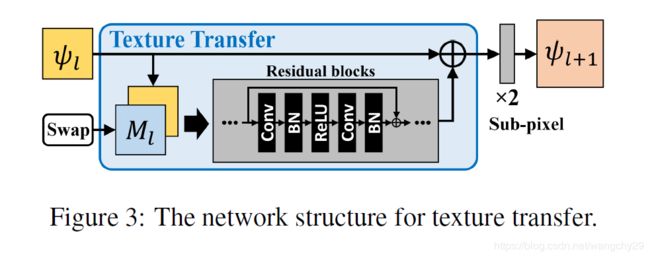
上图是纹理迁移的结构。
假设有L层,那最终SR:
![]()
不同于SISR只考虑![]() 和
和![]() 的不同,SRNTT还考虑了
的不同,SRNTT还考虑了![]() 和
和![]() 的纹理差异。于是论文定义了一个纹理损失:
的纹理差异。于是论文定义了一个纹理损失:
![]()
其中GR表示Gram矩阵,![]() 表示全部LR块对应的最匹配的相似度的评分。
表示全部LR块对应的最匹配的相似度的评分。![]() 就是正则化系数。
就是正则化系数。
训练目标函数
为了保留LR的空间结构、改善SR的视觉效果,并充分利用Ref的纹理信息。损失函数包括重构损失、感知损失、对抗损失、纹理损失。
重构损失:
![]()
采用1范数是为了产生更尖锐的细节。
感知损失:
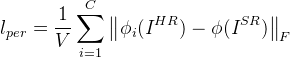
V表示长乘宽,C表示通道数。感知损失取得是VGG19中relu5_1的特征图。
对抗损失:
![]()
实现细节
前面的特征提取层来自于不同的VGG层,relu1_1,relu2_1,relu3_1。
![]() 的权值分别为1,1e-4,1e-6,1e-4.
的权值分别为1,1e-4,1e-6,1e-4.
学习率设置为1e-4.优化器为adam.
网络先只用重构损失训练2epochs,再用全部的损失训练20epochs。
论文还对![]() 做数据增强,获取其对应的放缩和旋转。
做数据增强,获取其对应的放缩和旋转。
数据集
论文通过捕获日常生活中的场景,建立了1863个目录,每个目录包含30到100张图片。每个目录内都包含相似程度不同的图像对。

论文的方法在训练时,随机裁剪![]() 的图像块,作为HR,,其对应的作为Ref,对HR用bicubic下采样4倍得到LR.
的图像块,作为HR,,其对应的作为Ref,对HR用bicubic下采样4倍得到LR.
用13761对patch作为训练集。用120组图像作为测试集,每组都包括四个相似度等级的ref图像。
论文还采用了Sun80,Urban100作为测试图像,Sunn80中的80个图像没有ref,论文在网上为其搜集了对应的ref。而Urban100没有ref。
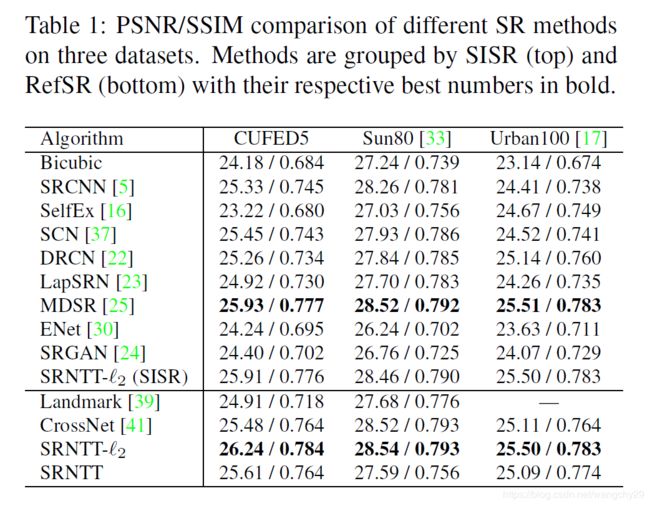
结果可以证明SRNTT的纹理损失的作用。

论文还对比了cross-net的optic flow的方法。证明了块匹配的效果。
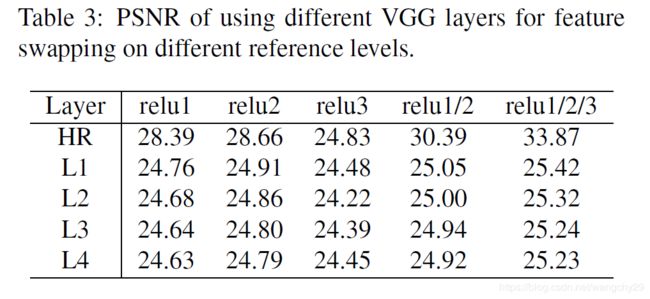
论文还对比了使用不同VGG层和在不同参考等级下的psnr。

最后论文对比了有纹理损失和没有纹理损失的SR结果,证明了纹理损失的意义。