Spark SQL
1、介绍
Spark SQL是构建在Spark core模块之上的四大模块之一,提供DataFrame等丰富API,可以采用传统的SQL语句进行数学计算。运行期间,会通过Spark查询优化器翻译成物理执行计划,并行计算后输出结果。底层计算原理仍然采用RDD计算实现。
2、Spark与Hive集成
在spark配置目录下创建指向hive-site.xml文件的同名软连接
$>cd /soft/spark/conf $>ln -s /soft/hive/conf/hive-site.xml hive-site.xml
复制hive元数据库使用的驱动程序到spark的jars目录下,比如mysql
$>cp mysql-java-connector.jar /soft/spark/jars
关闭hive配置文件hive-site.xml文件中版本检查,否则会报版本不一致异常
hive.metastore.schema.verification false
3、在Spark shell中访问hive
启动spark-shell,观察输出内容,打印hive配置信息
$>spark-shell --master spark://s101:7077启动时,输入如下hive信息:
下图红色部分表示spark的sql可用:

在scala命令行执行如下命令
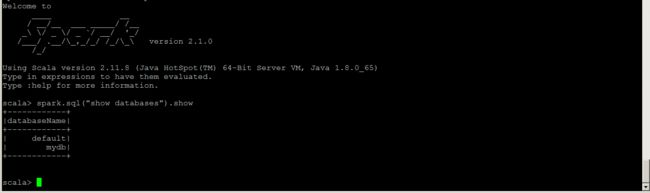
#显式所有数据库 $scala>spark.sql("show databases").show() #使用默认库 $scala>spark.sql("use default").show() #显式当前库中表 $scala>spark.sql("show tables").show() #查询custs表数据 $scala>spark.sql("select * from custs").show(1000,false) #构造RDD $scala>val rdd1= sc.parallize(Array((1,"tom1",12) ,(2,"tom2",13) ,(2,"tom3",14) )) #转换RDD成DataFrame $scala>val df = rdd1.toDF("id" , "name" , "age") #通过DataFrame select API实现SQL中的select语句 $scala>df.select("id").show() #注册临时表 $scala>df.registerTempTable("_cust") #通过临时表进行数据操纵 $scala>spark.sql("select * from _cust").show(1000 ,false) ;执行spark.sql("show databases").show()效果如下:
4、在idea中编写spark sql程序(scala版本)
创建模块引入spark-sql模块,注意还需要引入spark-hive模块和mysql驱动的依赖
org.apache.spark spark-sql_2.11 2.1.0 org.apache.spark spark-hive_2.11 2.1.0 mysql mysql-connector-java 5.1.17
复制core-site.xml、hdfs-site.xml和hive-site.xml文件到模块的resources目录下

编写scala代码
import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession /** * 老男孩大数据序列-Spark SQL */ object SQLScala { def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setAppName("SQLScala") conf.setMaster("local[4]") //创建sparksession val sess = SparkSession.builder() .config(conf) .enableHiveSupport() .getOrCreate() // val df = sess.sql("show databases") sess.sql("use default").show() sess.sql("select dep, max(salary) from emp group by dep").show(10000 , false) //使用SparkContext创建RDD对象 val rdd1 = sess.sparkContext .parallelize(Array((1,"tom1",12),(2,"tom2",12),(3,"tom3",14))) //导入SparkSession隐式转换,例如RDD转换成DF import sess.implicits._ val df1 = rdd1.toDF("id" , "name" , "age") df1.select("id","age").show(1000) //创建或替换临时视图 df1.createOrReplaceTempView("_cust") sess.sql("select id,name,age from _cust where age < 14").show() } }
5、在idea中编写spark sql程序(java版本)
创建模块引入spark-sql模块,注意还需要引入spark-hive模块和mysql驱动的依赖
同(4)。
复制core-site.xml、hdfs-site.xml和hive-site.xml文件到模块的resources目录下
同(4)。
编写java代码
package com.oldboy.bigdata.spark.java; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.*; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.Metadata; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; import java.util.ArrayList; import java.util.List; /** * Created by Administrator on 2018/8/2. */ public class SQLJava { public static void main(String[] args) { SparkConf conf = new SparkConf( ) ; conf.setAppName("SQLJava") ; conf.setMaster("local[*]") ; SparkSession sess = SparkSession.builder() .config(conf) .enableHiveSupport() .getOrCreate(); //创建数据集,即DataFrame Datasetds = sess.sql("select * from custs") ; ds.show(); //查询SQL ds.select("id" , "name").show(); ds.createOrReplaceTempView("_cust"); sess.sql("select * from _cust where age < 12").show(); //创建JavaSparkContext对象 JavaSparkContext sc = new JavaSparkContext(sess.sparkContext()) ; //加载文件得到rdd JavaRDD
rdd1 = sc.textFile("file:///d:\\mr\\temp3.dat" , 3) ; //变换RDD1到RDD 类型 JavaRDD
rdd2 = rdd1.map(new Function
dff = sess.createDataFrame(rdd2 , type) ; //select查询year列 dff.select("year").show(); } }
6、DataSet介绍
强类型集合,可以转换成并行计算。Dataset上可以执行的操作分为transfermation和action,类似于rdd。transfermation生成新的dataset,action执行计算并返回结果。DataSet是延迟计算,只有当调用action时才会触发执行。内部表现为逻辑计划。action调用时,spark的查询优化器对逻辑计划进行优化,生成物理计划,用于分布式行为下高效的执行。具体的执行计划可以通过explain函数来查看,方式如下:
$scala>spark.sql("explain select dep , max(salary) from emp group by dep").show结果如图所示,show(1000 , false)表示显式1000行数据,结果不截断显式。

7、Spark SQL访问json文件
准备json数据custs.json
{"id":1,"name":"tom","age":12} {"id":2,"name":"tomas","age":13} {"id":3,"name":"tomasLee","age":14} {"id":4,"name":"tomson","age":15} {"id":5,"name":"tom2","age":16}加载json文件成数据框
val df = sess.read.json("file:///d:/java/custs.json")
保存DataFrame成json文件
df.write.json("d:\\mr\\1.json")
8、Spark SQL访问Parquet文件
将数据框保存成parquet文件
$scala>spark.writer.parquet(path)
读取parquet文件
$scala>spark.read.parquet(path) ;
9、Spark SQL访问JDBC数据库
处理第三方jar
spark SQL是分布式数据库访问,需要将驱动程序分发到所有worker节点或者通过--jars命令附件
分发jar到所有节点
$>xsync /soft/spark/jars/third.jar
通过--jars命令指定
$>spark-shell --master spark://s101:7077 --jars /soft/spark/jars/third.jar
读取mysql数据
val prop = new java.util.Properties() prop.put("driver" , "com.mysql.jdbc.Driver") prop.put("user" , "root") prop.put("password" , "root") //读取 val df = spark.read.jdbc("jdbc:mysql://192.168.231.1:3306/big10" , "customers" ,prop) ;
保存数据到mysql表(表不能存在)
val prop = new java.util.Properties() prop.put("driver" , "com.mysql.jdbc.Driver") prop.put("user" , "root") prop.put("password" , "root") //保存 dataframe.write.jdbc("jdbc:mysql://192.168.231.1:3306/big11" , "emp" ,prop ) ;
10、Spark SQL作为分布式查询引擎
描述
终端用户或应用程序可以直接同spark sql交互,而不需要写其他代码。
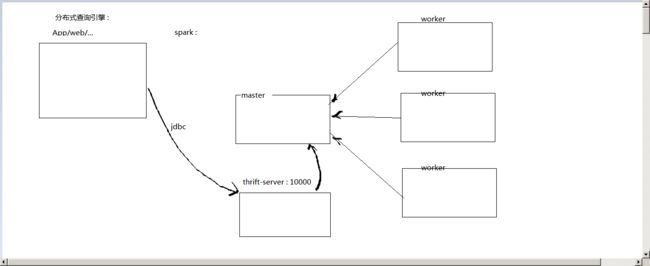
启动spark的thrift-server进程
$>start-thrift-server --master spark://s101:7077检测
webui检查
看spark webui,访问http://master:8080
端口检查,检查10000端口是否启动
$>netstat -anop | grep 10000
使用spark的beeline程序测试
$>spark/bin/beeline $>beeline>!conn jdbc:hive2://s101:10000/mydb $>beeline>select * from customers
编写客户端java程序交互spark分布式查询引擎
引入maven依赖
org.apache.hive hive-exec 2.1.0 org.apache.hive hive-jdbc 2.1.0
编写java代码
package com.oldboy.bigdata.spark.java; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; /** * 使用spark分布式查询引擎 */ public class DistributedQueryBySparkSQL { public static void main(String[] args) throws Exception { //注册驱动 Class.forName("org.apache.hive.jdbc.HiveDriver") ; //url String url = "jdbc:hive2://s101:10000/default" ; Connection conn = DriverManager.getConnection(url) ; String sql = "select * from emp" ; PreparedStatement ppst = conn.prepareStatement(sql) ; ResultSet rs = ppst.executeQuery() ; while(rs.next()){ int id = rs.getInt(1) ; String name = rs.getString(2) ; int salary = rs.getInt("salary") ; System.out.printf("%d,%s,%d\r\n" , id , name , salary); } rs.close(); conn.close(); } }
11、使用Spark SQL实现标签生成程序
分析
将标签从json格式解析出来后,注册成含有商家和评论两个字段的临时表,通过分组、排序、嵌套子查询方式统计结果即可。
代码实现
import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} /** * Created by Administrator on 2018/7/29. */ object TaggenSparkSQLScala { //从json中抽取出所有评论,形成list返回 def extractTags(json: String): List[String] = { var list: List[String] = Nil if (json != null && !json.equals("")) { import com.alibaba.fastjson.JSON //构造json对象 val obj = JSON.parseObject(json) //提取数组属性 val arr = obj.getJSONArray("extInfoList") if (arr != null && arr.size() > 0) { //提取数组一个json对象 val first = arr.getJSONObject(0) //标签集合 val tags = first.getJSONArray("values") if (tags != null && tags.size() > 0) { for (i <- 0 until tags.size()) { list = tags.getString(i) :: list } } } } list } def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.setAppName("tempAggPro") conf.setMaster("local") val sess = SparkSession.builder() .config(conf) .enableHiveSupport() .getOrCreate val sc = sess.sparkContext val rdd1 = sc.textFile("file:///d:\\temptags.txt") //变换成商家和评论 val rdd2 = rdd1.map(line=>{ val arr = line.split("\t") val busid = arr(0) val json = arr(1) val list = extractTags(json) (busid , list) }) //filter,过滤掉空评论 val rdd3 = rdd2.filter(!_._2.isEmpty) //对value进行压扁(70611801,环境优雅) val rdd4 = rdd3.flatMapValues(t=>t) //导入spark session的隐式转换 import sess.implicits._ //转换成dataframe,并注册成临时表 rdd4.toDF("busid" , "tag").createOrReplaceTempView("tags") //转换成dataframe,并注册成临时表 rdd4.toDF("busid" , "tag").createOrReplaceTempView("tags") //select val sql = """ select t3.busid, t3.tagstr from ( select t2.busid, max(t2.cnt) mx , collect_list(concat(t2.tag , '(' , t2.cnt , ')')) tagstr from ( select t.busid, t.tag, t.cnt from ( select busid, tag, count(*) cnt from tags group by busid, tag )t order by t.busid, t.cnt desc )t2 group by t2.busid )t3 order by t3.mx desc """ sess.sql(sql).show(1000,false) } }运行结果如下:
