1.创建scrapy项目
dos窗口输入:
scrapy startproject maoyan
cd maoyan
2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class MaoyanItem(scrapy.Item):
# define the fields for your item here like:
#影片中文名称/英文名称
ztitle = scrapy.Field()
etitle = scrapy.Field()
#影片类型
type = scrapy.Field()
#导演
dname = scrapy.Field()
#主演
star = scrapy.Field()
#上映时间
releasetime = scrapy.Field()
#影片时间
time = scrapy.Field()
# 评分
score = scrapy.Field()
#图片链接
image = scrapy.Field()
#详情信息
info = scrapy.Field()3.创建爬虫文件
dos窗口输入:
scrapy genspider -t crawl myspider maoyan.com
4.编写myspider.py文件(接收响应,处理数据)
# -*- coding: utf-8 -*-
import scrapy
#导入链接规则匹配
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
#导入模板
from maoyan.items import MaoyanItem
class MaoyanSpider(CrawlSpider):
name = 'myspider'
allowed_domains = ['maoyan.com']
start_urls = ['https://maoyan.com/board/4?offset=0']
rules = (
Rule(LinkExtractor(allow=r'offset=\d+'),follow=True),
Rule(LinkExtractor(allow=r'/films/\d+'),callback='parse_maoyan',follow=False),
)
def parse_maoyan(self, response):
item = MaoyanItem()
# 影片中文名称/英文名称
item['ztitle'] = response.xpath('//h3/text()').extract()[0]
item['etitle'] = response.xpath('//div[@class="ename ellipsis"]/text()').extract()[0]
# 影片类型
item['type'] = response.xpath('//li[@class="ellipsis"][1]/text()').extract()[0]
# 导演
item['dname'] = response.xpath('//a[@class="name"]/text()').extract()[0].strip()
# 主演
star_1 = response.xpath('//li[@class="celebrity actor"][1]//a[@class="name"]/text()').extract()[0].strip()
star_2 = response.xpath('//li[@class="celebrity actor"][2]//a[@class="name"]/text()').extract()[0].strip()
star_3 = response.xpath('//li[@class="celebrity actor"][3]//a[@class="name"]/text()').extract()[0].strip()
item['star'] = star_1 + "\\" + star_2 + '\\' +star_3
# 上映时间
item['releasetime'] = response.xpath('//li[@class="ellipsis"][3]/text()').extract()[0]
# 影片时间
item['time'] = response.xpath('//li[@class="ellipsis"][2]/text()').extract()[0].strip()[-5:]
# 评分,没抓到
# item['score'] = response.xpath('//span[@class="stonefont"]/text()').extract()[0]
item['score'] = "None"
# 图片链接
item['image'] = response.xpath('//img[@class="avatar"]/@src').extract()[0]
# 详情信息
item['info'] = response.xpath('//span[@class="dra"]/text()').extract()[0].strip()
yield item
5.编写pipelines.py(存储数据)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class MaoyanPipeline(object):
def __init__(self):
self.filename = open('maoyan.txt','wb')
def process_item(self, item, spider):
text = json.dumps(dict(item),ensure_ascii=False) + '\n'
self.filename.write(text.encode('utf-8'))
return item
def close_spider(self,spider):
self.filename.close()
6.编写settings.py(设置headers,pipelines等)
robox协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False headers
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
pipelines
ITEM_PIPELINES = {
'maoyan.pipelines.MaoyanPipeline': 300,
}7.运行爬虫
dos窗口输入:
scrapy crawl myspider 运行结果:
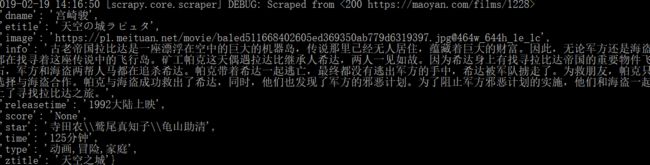

emmmm,top100只爬到99个,
问题:
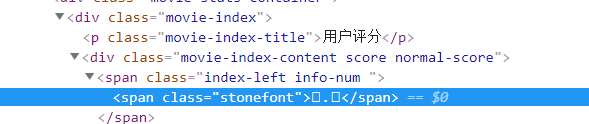
源码里面评分是□.□!!!全是套路,外面可以找到这个评分,懒得折腾了
单独爬取zname是100个,可能是哪个属性的xpath匹配,网页详情页没有,实现功能就行了
爬取成功
8.存储到mysql数据库
在mysql数据库建立相应的数据库和表:
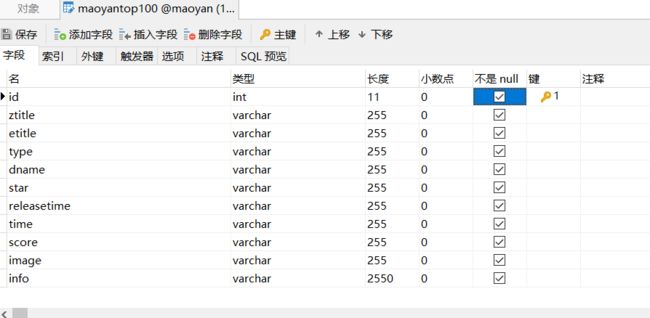
改写一下pipelines.py文件即可:
import pymysql.cursors
class MaoyanPipeline(object):
def __init__(self):
#连接数据库
self.connect = pymysql.connect(
host = 'localhost',
user = 'root',
password = '',
database = 'maoyan',
charset = 'utf8' # 别写成utf-8
)
self.cursor = self.connect.cursor() # 建立游标
def process_item(self, item, spider):
item = dict(item)
sql = "insert into maoyantop100(ztitle,etitle,type,dname,star,releasetime,time,score,image,info) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(item['ztitle'],item['etitle'],item['type'],item['dname'],item['star'],item['releasetime'],item['time'],item['score'],item['image'],item['info'],))
self.connect.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.connect.close()
运行:
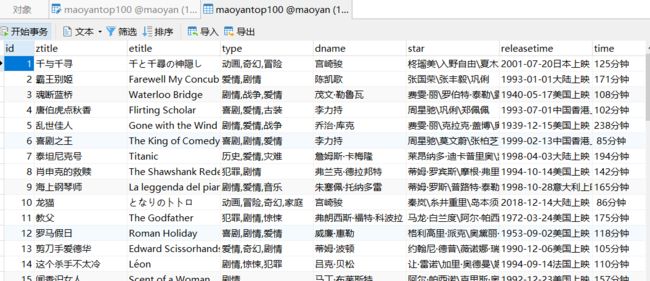
存储成功: