我们的机器 由于 日志量大 又开始了扩容,hadoop 2.8 不支持 disk volume level rebalance ,hadoop 3.0支持,可是 我们安装的是2.8,所以只能通过添加新的数据节点来完成 数据容器的扩容和负载均衡。
首先 hadoop 是支持动态扩容,原来的NameNode 和DataNode都不需要停止服务,新的数据节点启动 DataNode 和NodeManager 两个后台进程后 就自动直接加入即可,当然这里面还是有一些学问的,需要你来自己配置,集群机器都部署在阿里云,以下为具体的操作步骤
1.首先 购买 机器和磁盘
4核8G 32T ,cpu和内存不大,硬盘很大,因为我们这次 最主要是为了装日志 装数据,这台机器 很贵,好几千呢
2.格式化 新机器 磁盘
十六块 磁盘,每块2T ,单单格式化磁盘就要很久
幸好我写了一个脚本,自动化完成格盘,不然 单单格式化磁盘,我就要吐血了,末尾张贴 脚本
3.新机器 配置 1.主机名 2 jdk 3 hadoop 4环境变量 5 host 和 6创建 hadoop 操作用户,要和原来集群的hadoop 操作用户是一致的,
hadoop的文件 建议直接把NameNode上的hadoop安装目录直接copy过来,这样原来的配置 就不需要重新配置了,jdk hadoop 和其他的和集群原先的保持 安装位置尽量一致,不然需要单独个性化配置,比较繁琐,注意一定要把 hadoop/log目录排除在外,第一 好几个月了 log真的很大数据量,我们的好像是8G 了,第二 真的没用,
新机器要把原来 集群上的ip 主机名 配置在自己的机器上的 /etc/hosts上,并把自己的 ip 主机名也配置在集群上原先的所有机器上
4.所有的 原来 集群集群 host 及hadoop slaves文件 添加 新机器 的主机名和内网地址
5.配置 NameNode 的hadoop操作用户免登陆到新机器
这个环节 其实是非常简单的,但是我已经载过三次跟头了,真是没头脑,这次要单独做一下 整理,白白浪费五六个小时,
比如 我要做的是 NameNode A 免登陆到DataNode B,我想让 A 的hadoop 操作用户 角色 hadoop_role 免登陆到 B上并以B上的hadoop操作用户 hadoop_role 登录
首先 在 A 机器上 切换到 hadoop_role 用户
然后执行 生成 ssh-key ,我们要注意的就是ssh-key 是和用户绑定的,
然后在 B机器上确认 在 /home/hadoop_role 目录下有隐藏目录 .ssh目录
然后在 A 机器下 把 A 的hadoop-role 目录下的author-key 传递到 B机器的 hadoop-role 目录 .ssh 目录下
这个时候可能需要确认 A B 两台机器上 ./ssh 目录 权限 和 author-key的权限,由于权限不足造成 ssh 无法登录的还是很多的
具体的就是
在管理节点上执行下面操作:
1. sudo su hadoop
2. ssh localhost
3. [cd](http://3.cd/)
~/.ssh
4. rm ./id_rsa*
5. ssh-keygen -t rsa -P ""
6. cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys [root]
6 cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys
7. 把id_rsa.pub传输到数据节点hadoop用户下的.ssh目录中
其实我是传的 authorized_keys ,在 NameNode A上操作
scp /home/hadoop/.ssh/authorized_keys root@hadoop-data04:/home/hadoop/.ssh/authorized_keys
在数据节点上执行下面操作:
1. cat id_rsa.pub >> authorized_keys
2. rm -rf id_rsa.pub
3. chmod 600 authorized_keys
最后在管理节点上测试是否配置成功
基本上就可以 A 免登陆 B了
`
我这次就因为偷懒 错误 使用ssh-copy-id 命令
参考 http://man.linuxde.net/ssh-copy-id
正确操作是
- ssh-keygen -t rsa -P ""
生成的公钥位置
 image.png
image.png
2.ssh-copy-id 时一定要 指定公钥位置,不然就悲剧了,用 -i 指定
比如是这样
ssh-copy-id -i /root/.ssh/id_rsa.pub [email protected] ,回车 会让输入 要登录机器 的该用户角色 的密码
一次,然后退出后 ,下次就可以免密码登录了
造成这个错误 ,耽搁太久,最终还把 B 机器的ssh 服务搞乱了 挂掉了,正常无法登录了,而且 ssh的配置文件也被篡改了,最后经过多方努力,通过阿里云的后台 远程连接到这台机器,修复了ssh配置文件,然后重启ssh服务,整好了
image.png
_ssh 公钥认证报错:Permission denied (publickey,gssapi-keyex,gssapi-with-mic).解决](http://blog.csdn.net/wang_zhenwei/article/details/53105390)
6.在 新机器上 确认 hadoop 配置文件 中 hdfs-site.xml 中 数据存储是否需要修改增加 ,其他在配置文件中的 硬件 配置信息 是否要做修改,比如说 内存和 cpu 的核数 配置 hadoop 安装目录权限,另外就是 数据存储磁盘 的写入权限 ,之后 启动 DataNode 和NodeManager 后台进程,注意查看是否启动成功,启动失败则通过日志 出错信息 确认到底是什么造成失败
sbin/hadooo-daemon.sh start datanode
sbin/yarn-daemon.sh start nodemanager
jps
7.查看 hadoop的web ui 确认新机器是否已经加入到集群中来
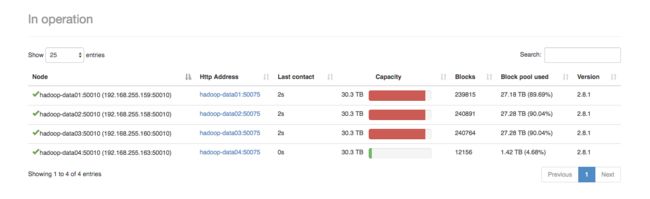
8.之后执行 hadoop balancer
这个建议 后台执行 ,不然远程连接一断,这个就断了
而且要注意的是,这个balancer 是一个漫长的过程 ,你内网网络传输是最大的瓶颈,它有多大,极限就有多大,我们的内网传输也就 不到200m/s,所以 要balancer 18T 的数据真的 ,哎,好久好久
9.总结 教训
扩容是一个比较 有挑战的内容,可能会造成数据重复 丢失等情况
扩容 是一个细致的活儿,要注意到很多琐碎的事情
扩容最好 安排在晚上 或者周五,格式化硬盘和 rebalance是一个 相当耗时的,把耗时的内容尽量安排在 晚上或者业务空闲或者非工作时间
ssh key 免登陆 这个要好好整整,折腾了五六个小时 错误的,太耽误时间,了解一下ssh的原理是很必须的
hdfs 数据压缩归档一定要日常化,再大的盘也有满的时候
不要等hdfs 达到 90% 以后才开始 扩容,不然会影响 到数据流的写入和其他业务进程
数据流到hdfs的管道一定要正常化, 上来就压缩是最好的,
扩容rebalance时 数据可能无法正常写入 ,mapReduce job也可能无法进行,想想也是,数据存储位置在不断改变,
最重要的是 一定要早点【逼着】领导给你买机器扩容,不然 逼到临界点,写不进去数据才扩容,修补数据 就更烦人了
送你一句箴言 : 【 年轻人,删库 跑路是要 坐牢 滴 /手动微笑/ 】
格盘脚本
#!/bin/sh
disks=("/dev/vdb" "/dev/vdc" "/dev/vdd" "/dev/vde" "/dev/vdf" "/dev/vdg" "/dev/vdh" "/dev/vdi" "/dev/vdj" "/dev/vdk" "/dev/vdl" "/dev/vdm" "/dev/vdn" "/dev/vdo" "/dev/vdp" "/dev/vdq" )
counts=1
for disk in ${disks[*]}
do
echo "begin fenqu disk :"+ $disk
echo "format disk complete mkdir ing"+${counts}
sudo -i mkdir /data${counts}
echo "n
p
1
wq"| fdisk $disk &
echo "fenqu finish,format disk ing"
mkfs.ext3 ${disk}1
echo "register in fstab"
echo "${disk}1 /data${counts} ext3 defaults 0 0">> /etc/fstab
echo "gua zai disk"
echo "all complete"
counts=$(expr $counts + 1)
echo "counts"+$counts
done
mount -a
参考文献 :
https://www.cnblogs.com/fefjay/p/6048269.html
http://blog.csdn.net/lichangzai/article/details/19118711
后台启动 hadoop 的部分单独进程
http://blog.csdn.net/lazythinker/article/details/47836097
http://www.cnosx.com/2017/10/08/%E9%98%BF%E9%87%8C%E4%BA%91ECS%E5%85%AC%E5%8C%99%E6%97%A0%E6%B3%95%E7%99%BB%E9%99%86/
https://stackoverflow.com/questions/36300446/ssh-permission-denied-publickey-gssapi-with-mic
https://www.cnblogs.com/xubing-613/p/6844564.html
http://www.oschina.net/question/54100_28922