2019独角兽企业重金招聘Python工程师标准>>> 
Splunk是啥?
Splunk是日志/流式数据领域中做的最好的商业软件实现,它的核心能力只有一个:
像Google那样搜索企业内部所有产生的日志
这个的威力非常大,现在的企业不缺数据,缺的是有效挖掘数据的能力。而显然大部分企业没有Google的能力去做搜索,于是Splunk提供这样的能力。与之相竞争的开源实现有Logstash。
Splunk ≈ Logstash
Logstash = Redis(传输) + ElasticSearch(搜索) + Kibana(展现)
ElasticSearch = Lucene + Search
那么,哪里可以买到呢?##
Splunk官网上有,我就不替他们做广告了,总之,很贵,一万美元能买1G的流量每天。言归正传,我还是分析一下这个玩意儿的一些功能特性吧。
首先,Splunk有一个很炫酷的界面

可以看到,Splunk的主要使用方式就是那个搜索框,在里面输入一种叫做SPL的搜索语言,就能获取到你想要的各种信息了。Splunk能在后台对数据进行过滤、聚合、统计,最后得到各种报表、图像
SPL是一种向SQL致(chao)敬(xi)的语言,语法非常的类似,不同的是,SPL搜索的不是关系数据库,而是输入到Splunk系统中所有的日志数据,以下是几个具体的案例:
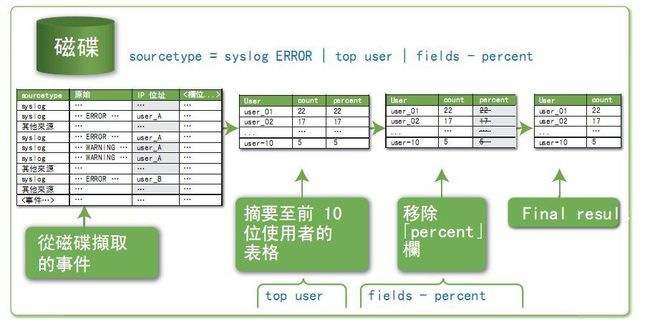
可以看到,对于一行SPL搜索语句
sourcetype = syslog ERROR | top user | fields - precent
Splunk是这么干的,
- 首先从硬盘上搜索字段sourcetype(来源类型)为syslog的日志,同时,在日志中含有ERROR这个关键字的。
- 通过管道符,把上面的搜索结果根据user字段做聚合,取出其中出现次数最多的前10个
- 再通过管道符,去掉百分比字段,最后得出结果
最后看到,这个搜索干了什么事情呢?它一下子就把日志中出错最多的前十个用户给统计出来了,这样后续程序员就能跟踪这些错误为什么产生,然后着手去解决。

| where distance/time > 100
使用where,对日志中两个字段进行相除后比较。
前因后果架构图

Splunk主要做了3件事
- 解析原始日志格式,分解成有意义的字段,有的 log 收集方案在第一阶段就解析日志只发送关心的字段,以节省带宽。
- 根据时间戳,request ID,session ID,user ID 等关联日志条目,以尽量清晰当时各个子系统的状态;
- 根据分析的目的做过滤、聚合、统计等等,最后整一份漂亮的报表出来。
Splunk出彩的特性是……
- WEB的UI很出色,插件式的,把这个做成了一个平台,允许很多第三方的公司在上面发布应用。
- 搜索语法强大,例如查找HTTP 503错误近期的出现频率,例如某一个地区用户访问最多的商品列表,例如页面访问量排名。基本上,你能想到的可以由SQL完成的搜索,SPL都能够做出来。
- 自动猜测一些日志的字段,同时可以在Web上手动调整怎么解析源头日志。
- 以上所有操作,都能由掌握SPL语言的非程序员来完成,也就是说Splunk可以由产品经理或者运营团队来操控。而且还能把数据可视化做出来。
- 流式搜索,实时过滤日志然后报警,这个对运维团队很有用。
以上几点,就决定了Splunk的市场非常的大,这家公司的概念是流式数据领域的数据仓库,2012在纳斯达克上市,不过这两年被人做空,股票大跌。因为很多云计算厂商都能提供这种服务,例如阿里云1MB/S都是免费的。
竞品分析 —— Logstash, Kafka##
###Splunk vs Logstash###
Logstash是个开源的日志搜索工具,也是一体化的开箱即用的产品。基本上,能实现Splunk六成的功力。Web没有那么强,也没有SPL这样简单的语言,ElasticSearch需要通过Json来查询,Kibana的搜索语句能力有限。目前可以说Logstash这个项目还在成熟期。需要后续很多的工作才能做好。
###Splunk vs Kafka ###
这么比较其实不是很公平。
Kafka只解决了日志的统一搜集、传输、序列化存储问题。Splunk做的更多些,还做了数据索引的深加工。
同时,Kafka需要在源头使用schema来定义数据格式,严格,有利于后期的消费程序使用。
Splunk却对源头数据要求没有那么高,对现有系统改动小,因为是个企业软件,需要追求兼容性。
从高可用方面来看,Splunk目前还没有一天搜集几个T的数据的案例,Kafka在这方面的能力绝对没有问题。
Kafka是个比较好的车身框架,但还缺一个强大的发动机和不少内饰;Splunk是一辆功能完善的车子,就是价格很贵,而且没有在150码以上开过的案例。
所以,对于Kafka,可能的总体解决方案有:
Kafka + YARN + Hadoop = Samza(Linkin)
Kafka + Strom + MySQL
Kafka + ElasticSearch + Kibana
To be continued...##
Splunk和Logstash可以说是日志处理领域较为成功的商业和开源产品了
—— 但是,我认为对于云计算厂商来讲,还有两个产品可以做分析,那就是2014年开始有的阿里云的简单日志服务SLS,以及亚马逊的Amazon kinesis。
欲知后事如何,且听下回分解 ~~
主要参考文章
探索 Splunk ,搜尋處理語言 (SPL) 入門和操作手冊 —— 繁体的技术手册,估计是Splunk找台湾人翻译的吧
ElasticSearch 权威指南 —— 上海的一家互联网公司,做EverMemo和食色的那家,的某位员工翻译的
访谈与书评:《LogStash,使日志管理更简单》 —— 英文原书要9刀,作者穷疯了……还是看看评论吧
次要参考文章
《通过 ElasticSearch 进行可伸缩搜索》
《使用logstash+elasticsearch+kibana快速搭建日志平台》
《LogStash日志分析系统》
《logstash VS splunk》