工具:Fiddler
首先下载安装Fiddler,这个工具是用来监听网络请求,有助于你分析请求链接和参数。
打开目标网站:http://www.17sucai.com/,然后点击登录
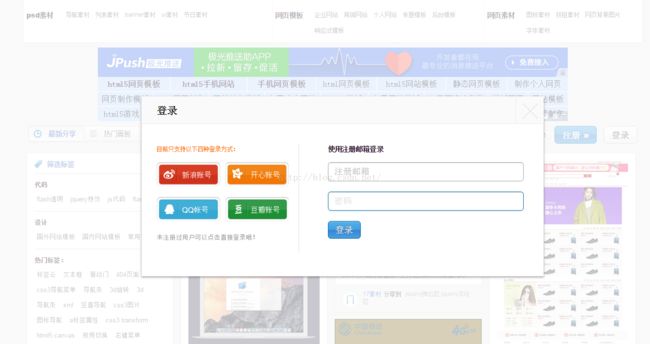
好了,先别急着登录,打开你的Fiddler,此时Fiddler里面是没有监听到网络请求的,然后回到页面,输入邮箱和密码,点击登录,下面再到fiddler里面去看

这里面的第一个请求就是你点击登录的网络请求,点击这个链接可以在右边看到你的一些请求信息

然后点击WebForms可以看到你的请求参数,也就是用户名和密码


下面我们有代码来实现登录功能
import urllib.request import urllib import gzip import http.cookiejar #定义一个方法用于生成请求头信息,处理cookie def getOpener(head): # deal with the Cookies"code" class="python"> cj = http.cookiejar.CookieJar() pro = urllib.request.HTTPCookieProcessor(cj) opener = urllib.request.build_opener(pro) header = [] for key, value in head.items(): elem = (key, value) header.append(elem) opener.addheaders = header return opener #定义一个方法来解压返回信息 def ungzip(data): try: # 尝试解压 print('正在解压.....') data = gzip.decompress(data) print('解压完毕!') except: print('未经压缩, 无需解压') return data #封装头信息,伪装成浏览器 header = { 'Connection': 'Keep-Alive', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Accept': 'application/json, text/javascript, */*; q=0.01', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'X-Requested-With': 'XMLHttpRequest', 'Host': 'www.17sucai.com', } url = 'http://www.17sucai.com/auth' opener = getOpener(header) id = 'xxxxxxxxxxxxx'#你的用户名 password = 'xxxxxxx'#你的密码 postDict = { 'email': id, 'password': password, } postData = urllib.parse.urlencode(postDict).encode() op = opener.open(url, postData) data = op.read() data = ungzip(data) print(data)
好了,接下来清空一下你的Fiddler,然后运行这个程序,看一下你的Fiddler
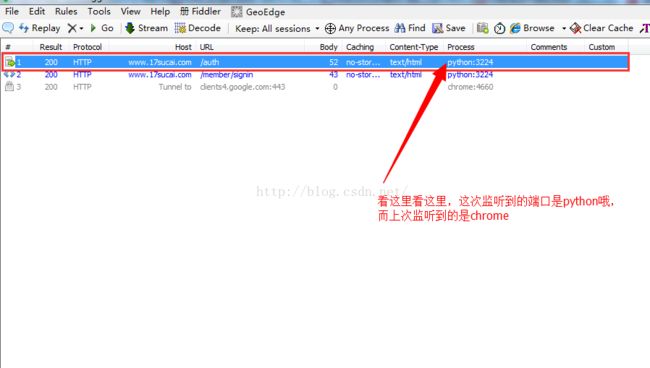
你可以点击这个链接,看看右边的请求信息和你用浏览器请求的是不是一样
下面是程序后代打印的信息

code=200表示登陆成功
解析来就需要获取到签到的url,这里你需要一个没有签到的账号在网站中点击签到按钮,然后通过Fiddler来获取到签到的链接和需要的信息。
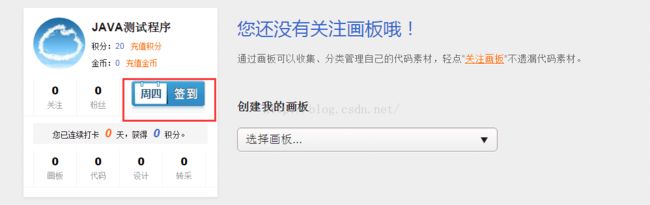
然后点击“签到”,签到成功后到Fiddler中查看捕捉到的url

点击这个url可以在右边查看访问这个链接时所需要的头信息和cookies神马的,我们已经登录成功后直接使用cookies就行了,python对cookies的处理做好了封装,下面是我的代码中对cookies的使用
cj = http.cookiejar.CookieJar() pro = urllib.request.HTTPCookieProcessor(cj) opener = urllib.request.build_opener(pro)
下面是签到成功返回的信息:code=200表示请求成功,day=1表示连续签到一天,score=20表示获得的积分数
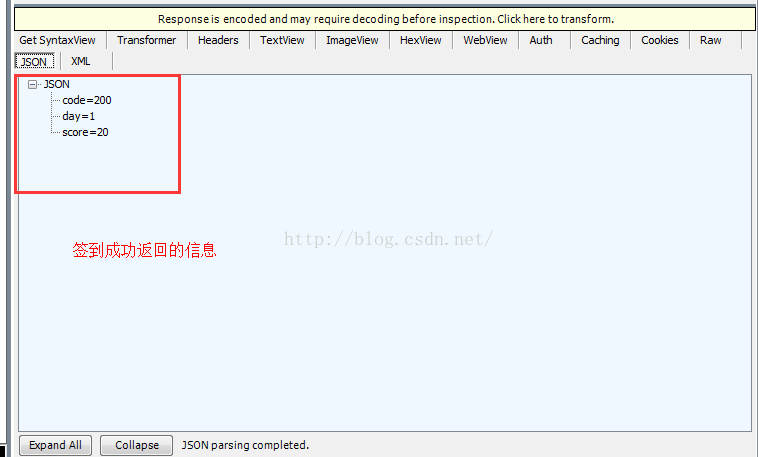
下面放出完整代码,当然,为了测试代码签到,你还需要你一没有签到过的账号
import urllib.request import urllib import gzip import http.cookiejar def getOpener(head): # deal with the Cookies cj = http.cookiejar.CookieJar() pro = urllib.request.HTTPCookieProcessor(cj) opener = urllib.request.build_opener(pro) header = [] for key, value in head.items(): elem = (key, value) header.append(elem) opener.addheaders = header return opener def ungzip(data): try: # 尝试解压 print('正在解压.....') data = gzip.decompress(data) print('解压完毕!') except: print('未经压缩, 无需解压') return data header = { 'Connection': 'Keep-Alive', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Accept': 'application/json, text/javascript, */*; q=0.01', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'X-Requested-With': 'XMLHttpRequest', 'Host': 'www.17sucai.com', } url = 'http://www.17sucai.com/auth' opener = getOpener(header) id = 'xxxxxxx' password = 'xxxxxxx' postDict = { 'email': id, 'password': password, } postData = urllib.parse.urlencode(postDict).encode() op = opener.open(url, postData) data = op.read() data = ungzip(data) print(data) url = 'http://www.17sucai.com/member/signin' #签到的地址 op = opener.open(url) data = op.read() data = ungzip(data) print(data)
相比登录,签到也就是在登录完成后重新打开一个链接而已,由于我的账号都已经签到过了,这里就不在贴运行代码的图 了。
接下来要做的就是在你电脑上写个bat 脚本,再在“任务计划”中添加一个定时任务就行了。

在此之前你还需要配置一下python的环境变量,这里就不在赘述了。
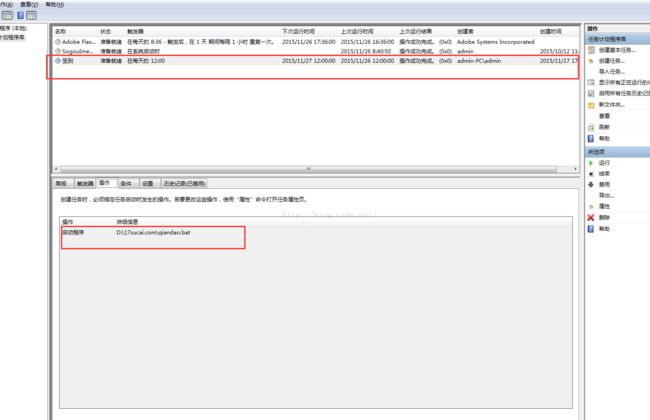
原文链接:http://blog.csdn.net/u283056051/article/details/49946981