R for Data Science总结之——Factors
R for Data Science总结之——Factors
factor类型在R中用于处理分类变量,这里我们使用forcats包,也就是for categorical variables:
library(tidyverse)
library(forcats)
定义factor:
x1 <- c("Dec", "Apr", "Jan", "Mar")
month_levels <- c(
"Jan", "Feb", "Mar", "Apr", "May", "Jun",
"Jul", "Aug", "Sep", "Oct", "Nov", "Dec"
)
y1 <- factor(x1, levels = month_levels)
y1
#> [1] Dec Apr Jan Mar
#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
sort(y1)
#> [1] Jan Mar Apr Dec
#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
如果levels中没有的变量会自动转化为NA:
y2 <- factor(x2, levels = month_levels)
y2
#> [1] Dec Apr Mar
#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
如果想得到一个warning信息,可以使用readr::parse_factor():
y2 <- parse_factor(x2, levels = month_levels)
#> Warning: 1 parsing failure.
#> row # A tibble: 1 x 4 col row col expected actual expected actual 1 3 NA value in level set Jam
如果省略levels,那么数据会按字母顺序排列:
factor(x1)
#> [1] Dec Apr Jan Mar
#> Levels: Apr Dec Jan Mar
如果想让levels顺序符合数据中第一次出现的顺序可以使用unique()或在定义后进行fct_inorder():
f1 <- factor(x1, levels = unique(x1))
f1
#> [1] Dec Apr Jan Mar
#> Levels: Dec Apr Jan Mar
f2 <- x1 %>% factor() %>% fct_inorder()
f2
#> [1] Dec Apr Jan Mar
#> Levels: Dec Apr Jan Mar
想直接获得levels可用:
levels(f2)
#> [1] "Dec" "Apr" "Jan" "Mar"
现在拿gss_cat数据集做实验:
gss_cat
#> # A tibble: 21,483 x 9
#> year marital age race rincome partyid relig denom tvhours
#>
#> 1 2000 Never ma… 26 White $8000 to… Ind,near … Protes… Southe… 12
#> 2 2000 Divorced 48 White $8000 to… Not str r… Protes… Baptis… NA
#> 3 2000 Widowed 67 White Not appl… Independe… Protes… No den… 2
#> 4 2000 Never ma… 39 White Not appl… Ind,near … Orthod… Not ap… 4
#> 5 2000 Divorced 25 White Not appl… Not str d… None Not ap… 1
#> 6 2000 Married 25 White $20000 -… Strong de… Protes… Southe… NA
#> # ... with 2.148e+04 more rows
当factor储存在tibble中,我们无法清晰地看到levels,这时可以使用count:
gss_cat %>%
count(race)
#> # A tibble: 3 x 2
#> race n
#>
#> 1 Other 1959
#> 2 Black 3129
#> 3 White 16395
或者使用柱状图:
ggplot(gss_cat, aes(race)) +
geom_bar()
用ggplot2包进行画图时会自动丢弃没有值的变量,也可以让其不丢弃:
ggplot(gss_cat, aes(race)) +
geom_bar() +
scale_x_discrete(drop = FALSE)
修改factor顺序
relig_summary <- gss_cat %>%
group_by(relig) %>%
summarise(
age = mean(age, na.rm = TRUE),
tvhours = mean(tvhours, na.rm = TRUE),
n = n()
)
ggplot(relig_summary, aes(tvhours, relig)) + geom_point()

想要改变量顺序的话可以使用fct_reorder():
ggplot(relig_summary, aes(tvhours, fct_reorder(relig, tvhours))) +
geom_point()
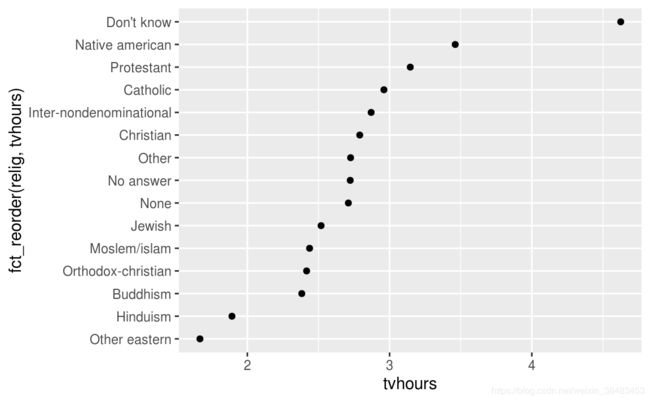
这里也推荐先使用mutate再进行作图:
relig_summary %>%
mutate(relig = fct_reorder(relig, tvhours)) %>%
ggplot(aes(tvhours, relig)) +
geom_point()
我们也可以就收入水平进行作图:
rincome_summary <- gss_cat %>%
group_by(rincome) %>%
summarise(
age = mean(age, na.rm = TRUE),
tvhours = mean(tvhours, na.rm = TRUE),
n = n()
)
ggplot(rincome_summary, aes(age, fct_reorder(rincome, age))) + geom_point()

这里可以用fct_relevel()进行调整:
ggplot(rincome_summary, aes(age, fct_relevel(rincome, "Not applicable"))) +
geom_point()

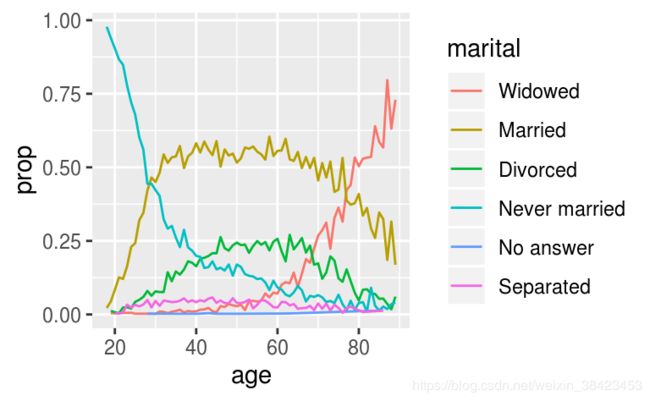
另外还有fct_reorder2()可以将factor按照y以及最大的x值重排序,通常用于作图的颜色控制:
by_age <- gss_cat %>%
filter(!is.na(age)) %>%
count(age, marital) %>%
group_by(age) %>%
mutate(prop = n / sum(n))
ggplot(by_age, aes(age, prop, colour = marital)) +
geom_line(na.rm = TRUE)
ggplot(by_age, aes(age, prop, colour = fct_reorder2(marital, age, prop))) +
geom_line() +
labs(colour = "marital")
最后对于柱状图而言,fct_infreq()可用于按frequency递增排列柱图,可与fct_rev()搭配使用:
gss_cat %>%
mutate(marital = marital %>% fct_infreq() %>% fct_rev()) %>%
ggplot(aes(marital)) +
geom_bar()

若要更改各个level的名称,可使用fct_recode():
gss_cat %>% count(partyid)
#> # A tibble: 10 x 2
#> partyid n
#>
#> 1 No answer 154
#> 2 Don't know 1
#> 3 Other party 393
#> 4 Strong republican 2314
#> 5 Not str republican 3032
#> 6 Ind,near rep 1791
#> # ... with 4 more rows
gss_cat %>%
mutate(partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat"
)) %>%
count(partyid)
#> # A tibble: 10 x 2
#> partyid n
#>
#> 1 No answer 154
#> 2 Don't know 1
#> 3 Other party 393
#> 4 Republican, strong 2314
#> 5 Republican, weak 3032
#> 6 Independent, near rep 1791
#> # ... with 4 more rows
若想将几组level合并:
gss_cat %>%
mutate(partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat",
"Other" = "No answer",
"Other" = "Don't know",
"Other" = "Other party"
)) %>%
count(partyid)
#> # A tibble: 8 x 2
#> partyid n
#>
#> 1 Other 548
#> 2 Republican, strong 2314
#> 3 Republican, weak 3032
#> 4 Independent, near rep 1791
#> 5 Independent 4119
#> 6 Independent, near dem 2499
#> # ... with 2 more rows
若想折叠大量的level,fct_collapse()是个更好的选择:
gss_cat %>%
mutate(partyid = fct_collapse(partyid,
other = c("No answer", "Don't know", "Other party"),
rep = c("Strong republican", "Not str republican"),
ind = c("Ind,near rep", "Independent", "Ind,near dem"),
dem = c("Not str democrat", "Strong democrat")
)) %>%
count(partyid)
#> # A tibble: 4 x 2
#> partyid n
#>
#> 1 other 548
#> 2 rep 5346
#> 3 ind 8409
#> 4 dem 7180
若想将小类合并进行快速画图可使用fct_lump():
gss_cat %>%
mutate(relig = fct_lump(relig)) %>%
count(relig)
#> # A tibble: 2 x 2
#> relig n
#>
#> 1 Protestant 10846
#> 2 Other 10637
我们可以调整参数n来指定保留多少组:
gss_cat %>%
mutate(relig = fct_lump(relig, n = 10)) %>%
count(relig, sort = TRUE) %>%
print(n = Inf)
#> # A tibble: 10 x 2
#> relig n
#>
#> 1 Protestant 10846
#> 2 Catholic 5124
#> 3 None 3523
#> 4 Christian 689
#> 5 Other 458
#> 6 Jewish 388
#> 7 Buddhism 147
#> 8 Inter-nondenominational 109
#> 9 Moslem/islam 104
#> 10 Orthodox-christian 95
所有代码已上传GITHUB点此进入