labelme批量制作数据集教程(windows10+python3.6+tensorflow)
最近在用FCN学习图像语义分割,需要制作自己的数据集,看了很多教程,摸索出来一些经验,特地来总结一下。本人的开发环境为Win10+Anaconda(python3.6),希望能给大家一些参考。
1. 图像大小调整
这一步应该不是必须的,图片调整成256*256可能会更便于池化(我获取原始图像的时候特意取成了正方形的),
图1给出调整文件夹内批量图片大小的代码截图,参考自图像分割 | FCN数据集制作的全流程(图像标注)。
 图1 操作实例
图1 操作实例
2. 图像标注
2.1 labelme安装
参考自labelme安装及使用,原文为Labelme新创建了一个环境,我在为了深度学习已经配置好的TF环境下直接安装了labelme,如图2。
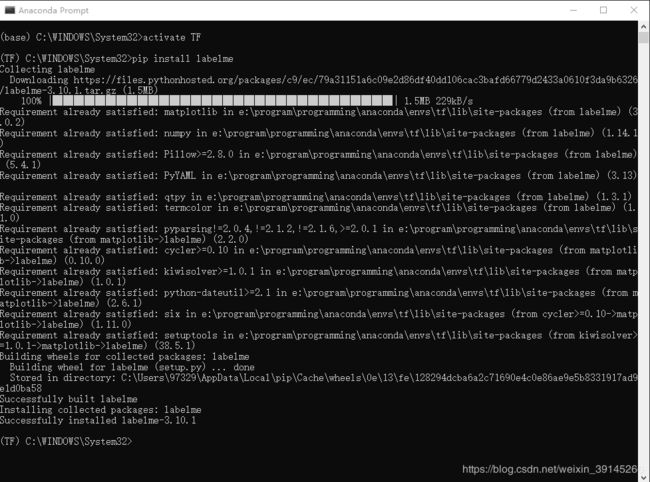 图2 labelme安装
图2 labelme安装
安装完成后,在TF环境下输入labelme,就会启动程序,如图3。
 图3 labelme启动
图3 labelme启动
2.2 labelme标注数据
点击OpenDir选择我们的图像所在文件夹,会导入文件内所有图片,如图4所示。
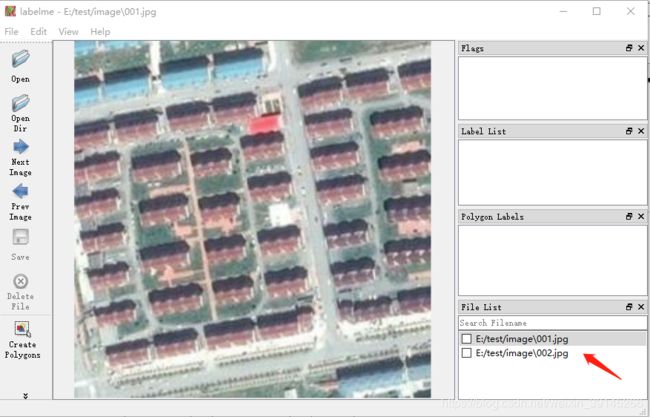 图4 批量导入数据
图4 批量导入数据
点击左下角的CreatePolygons,单击鼠标左键添加多边形顶点,Ctrl+Z撤销上一个顶点,最后点击起始点完成多边形的选择,弹出命名框。同一类下有多个实体对象时,如城区对象时,用City1,City2区分,Ctrl+S保存生成json文件,同时右下角文件目录下该图像前打钩显示已标注,如图5所示。
 图5 标注数据
图5 标注数据
2.3 格式转换
json文件需要转换成png文件,基本转换方法是在安装了labelme的环境下(我的是TF环境),输入下面的代码:
labelme_json_to_dataset E:\test\image\001.json在001.json所在文件夹内,会生成一个001_json的文件夹,里面有5个文件,如图6所示。
 图6 json转化dataset
图6 json转化dataset
但是当数据文件很多时,需要批量处理的方法,我找到3种,大家可以试一试。
2.3.1 更改json_to_dataset.py
参考自改进json_to_dataset.py和改进json_to_dataset,通过修改py文件使得能够直接批量转换json文件,但是我在用的过程中报错UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: illegal multibyte sequence,错误在这一句:data = json.load(open(path))。当我把open(path)改成open(path,encoding="UTF-8")后,又会报错UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0:invalid start byte。让我很绝望,不知道大家知不知道错误在哪里。
2.3.2 shell脚本循环法
参考自利用shell脚本批量处理json_to_dataset,通过shell脚本,循环处理文件。但是我对shell脚本了解不多,直接把原文里的脚本做成.sh文件在git里运行,提示json_to_dataset command not found,这篇文章倒是指出了要激活Anaconda的环境,但是他并没有说该怎么做,所以激励我写教程一定要很详细。
2.3.3 bat脚本循环法
绝望的我开始百度怎么样在cmd写循环命令,然后我发现了这个提问,惊奇发现还有一个倒霉蛋和我的问题一模一样,然后我就用了答案里的代码。不过比较悲催的是,他的命名方式是1.json,2.json,3.json....221.json,我的命名方式是001.json,002.json...010.json...,答案里是直接从1-221循环,然后生成文件名。所以我还不能直接套用。(当然如果有人的命名方式和他一样的话,会发现这个代码还有问题,就是循环里套了循环,生成一遍再来一遍)
最后我百度了批命令里遍历文件夹内文件的方式,写出了自己的命令,如下:
@echo off
for %%i in (*.json) do labelme_json_to_dataset %%i
pause就这三行代码,解决了困扰我一下午的问题。新建一个txt文件,把这个复制进去,然后改名为test.bat,和要转换的文件放在一起。然后在激活相应环境下(我的就是TF环境命令行下),进入所在文件目录,命令行输入test.bat就可以了,如图7,图8所示。
 图7 bat批量转换json
图7 bat批量转换json
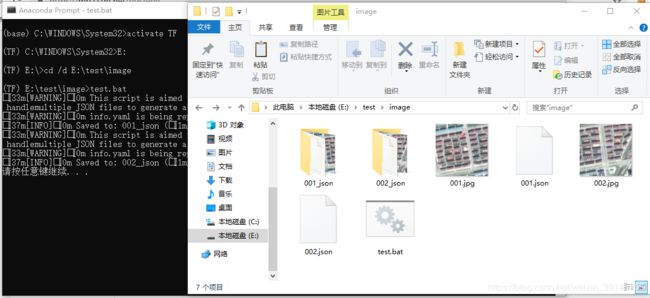 图8 转换结果
图8 转换结果
2.4 图片提取
生成的label图片均在文件中,且图片名均是label.png,所以需要批量提取label.png,其他4个文件没有用,在images文件夹同级目录下,新建文件夹annotations,存放标签图,代码如下。
#将标签图从json文件中批量取出
import os
import shutil
path = 'E:/test/images/'
file = os.listdir(path)
dirpath = 'E:/test/annotations/'
for eachfile in file:
if os.path.isdir(path+eachfile):
if os.path.exists(path+eachfile+'/label.png'):
(temp_name,temp_extention) = os.path.splitext(eachfile) #分离文件名与后缀
shutil.copy(path+eachfile+'/label.png',dirpath+temp_name+'.png')
print(eachfile+' successfully moved')得到标签图,如图9所示。
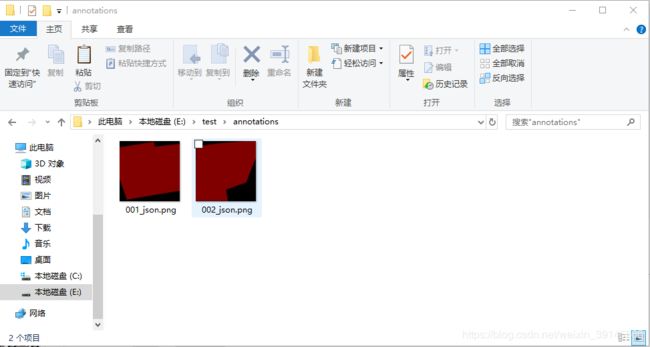 图9 批量提取标签图
图9 批量提取标签图
3 分训练集和测试集
在images和annotations下新建文件夹training和validation,将之前的原始图片和标签图片分为训练集和测试集,同名文件夹下原始图和标签图一一对应,如图10所示。
 图10 最终数据集
图10 最终数据集