sql
目录
1 条件函数
1.1 if
1.2 COALESCE(coalesce)
1.3 CASE
2 IFNULL 表达式
3 SQL 函数 instr的用法(Oracle)
4 join
4.1 LEFT JOIN 关键字
4.2 RIGHT JOIN 关键字
4.3 INNER JOIN 关键字
5 DATE_SUB() 函数
6 UCASE() 函数
7 LCASE() 函数
8 LEAD、LAG函数
9、结果保存为另一个表
10、增加从1 开始递增的一列
11、case when
12 Sql中的并(UNION)、交(INTERSECT)、差(minus)、除去(EXCEPT)详解
12.1 UNION
12.2 INTERSECT
12.3 minus
12.4 EXCEPT
13 replace与regexp_replace函数
13.1 REPLACE
13.2 REGEXP_REPLACE
14 CONVERT() 函数
15 DATENAME()的使用
16 sql获取当前时间
17 to_date()、to_char()和TO_NUMBER (Oracle )
17.1 to_date()
17.2 TO_CHAR
17.3 TO_NUMBER
18
19 数值计算函数(hive)
20 字符函数
21 正则
21.1 regexp_replace ,正则表达式替换(详见13)
21.2 regexp_extract 正则表达式解析:
22 URL解析
22.1 parse_url
22.2 parse_url_tuple
23 json解析
23.1 get_json_object
23.2 json_tuple
24 split
25 str_to_map,string转map
26 集合统计函数(hive)
27 复杂类型访问操作及统计函数
27.1 访问数组 Map 结构体
27.2 Map类型长度 Array类型长度
27.3 类型转换: cast
27.4 explode
27.5 LATERAL VIEW (lateral view)行转列
27.6 列转行(collect_list、collect_set )
28 窗口函数、分析函数、增强group
28.1 COUNT、SUM、MIN、MAX、AVG
28.2 RANK、ROW_NUMBER、DENSE_RANK
28.3 first_value与last_value
28.4 LEAD、LAG函数
28.5 Ntile
28.6 CUME_DIST、PERCENT_RANK
28.6.1 CUME_DIST
28.6.2 PERCENT_RANK
28.7 增强的聚合 Cube和Grouping 和Rollup
28.7.1 GROUPING SETS
28.7.2 CUBE
28.7.3 ROLLUP
28.8 nulls first、nulls last
http://www.w3school.com.cn/sql/func_date_sub.asp
https://blog.csdn.net/scgaliguodong123_/article/details/60881166
1 条件函数
1.1 if
IF( expr1 , expr2 , expr3 )
expr1 的值为 TRUE,则返回值为 expr2
expr2 的值为FALSE,则返回值为 expr3
SELECT IF(TRUE,1+1,1+2);
-> 2
SELECT IF(FALSE,1+1,1+2);
-> 3
SELECT IF(STRCMP("111","222"),"不相等","相等");
-> 不相等
IF (b_id IS NULL,'其他',b_id) AS id,
from table
1.2 COALESCE(coalesce)
COALESCE返回参数中的第一个非空值;如果所有值都为 NULL,那么返回 NULL
select COALESCE(null,user_id,device_id,user_type), COALESCE(null,null,device_id,user_type)
from order_detail
1.3 CASE
select
case user_type when 'new' then 'new_user' when 'old' then 'old_user' else 'others' end as name1,
case when user_type='new' and sales>=5 then 'gold_user' when user_type='old' and sales<3 then 'bronze_user' else 'silver_user' end as name2
2 IFNULL 表达式
IFNULL( expr1 , expr2 )
在 expr1 的值不为 NULL的情况下都返回 expr1,否则返回 expr2,如下:
SELECT IFNULL(NULL,"11");
-> 11
SELECT IFNULL("00","11");
-> 00
3 SQL 函数 instr的用法(Oracle)
INSTR(C1,C2,I,J) 在一个字符串中搜索指定的字符,返回发现指定的字符的位置;
C1 被搜索的字符串
C2 希望搜索的字符串
I 搜索的开始位置,默认为1
J 出现的位置,默认为1
SQL> select instr("abcde",'b');
结果是2,即在字符串“abcde”里面,字符串“b”出现在第2个位置。如果没有找到,则返回0;不可能返回负数
简单一句就是:instr函数返回字符串str中子字符串substr第一次出现的位置,在sql中第一字符的位置是1,如果 str不含substr返回0。
4 join
4.1 LEFT JOIN 关键字
LEFT JOIN 关键字会从左表 (table_name1) 那里返回所有的行,即使在右表 (table_name2) 中没有匹配的行。
LEFT JOIN 关键字语法
SELECT column_name(s)
FROM table_name1
LEFT JOIN table_name2
ON table_name1.column_name=table_name2.column_name
注释:在某些数据库中, LEFT JOIN 称为 LEFT OUTER JOIN。
4.2 RIGHT JOIN 关键字
RIGHT JOIN 关键字会右表 (table_name2) 那里返回所有的行,即使在左表 (table_name1) 中没有匹配的行。
RIGHT JOIN 关键字语法
SELECT column_name(s)
FROM table_name1
RIGHT JOIN table_name2
ON table_name1.column_name=table_name2.column_name
注释:在某些数据库中, RIGHT JOIN 称为 RIGHT OUTER JOIN。
4.3 INNER JOIN 关键字
在表中存在至少一个匹配时,INNER JOIN 关键字返回行。
INNER JOIN 关键字语法
SELECT column_name(s)
FROM table_name1
INNER JOIN table_name2
ON table_name1.column_name=table_name2.column_name
注释:INNER JOIN 与 JOIN 是相同的。
INNER JOIN 关键字在表中存在至少一个匹配时返回行。
5 DATE_SUB() 函数
定义和用法
DATE_SUB() 函数从日期减去指定的时间间隔。
语法
DATE_SUB(date,INTERVAL expr type)date 参数是合法的日期表达式。expr 参数是您希望添加的时间间隔。
type 参数可以是下列值:
| Type 值 |
|---|
| MICROSECOND |
| SECOND |
| MINUTE |
| HOUR |
| DAY |
| WEEK |
| MONTH |
| QUARTER |
| YEAR |
| SECOND_MICROSECOND |
| MINUTE_MICROSECOND |
| MINUTE_SECOND |
| HOUR_MICROSECOND |
| HOUR_SECOND |
| HOUR_MINUTE |
| DAY_MICROSECOND |
| DAY_SECOND |
| DAY_MINUTE |
| DAY_HOUR |
| YEAR_MONTH |
实例:
假设我们有如下的表:
| OrderId | ProductName | OrderDate |
|---|---|---|
| 1 | 'Computer' | 2008-12-29 16:25:46.635 |
现在,我们希望从 "OrderDate" 减去 2 天。
我们使用下面的 SELECT 语句:
SELECT OrderId,DATE_SUB(OrderDate,INTERVAL 2 DAY) AS OrderPayDateFROM Orders
结果:
| OrderId | OrderPayDate |
|---|---|
| 1 | 2008-12-27 16:25:46.635 |
6 UCASE() 函数
UCASE() 函数
UCASE 函数把字段的值转换为大写。
SELECT UCASE(column_name) FROM table_name7 LCASE() 函数
LCASE 函数把字段的值转换为小写。
SQL LCASE() 语法
SELECT LCASE(column_name) FROM table_name8 LEAD、LAG函数
可以 获取结果集中,按一定排序所排列的当前行的上下相邻若干offset 的某个行的某个列(不用结果集的自关联);
lag ,lead 分别是向前,向后;
lag 和lead 有三个参数,第一个参数是列名,第二个参数是偏移的offset,第三个参数是 超出记录窗口时的默认值)
lag(expression<,offset><,default>)函数可以访问组内当前行之前的行,
而lead(expression<,offset><,default>)函数则正相反,可以访问组内当前行之后的行.
其中,offset是正整数,默认为1。因组内第一个条记录没有之前的行,最后一行没有之后的行,default就是用于处理这样的信息,默认为空。
注意:这2个函数必须指定 order By 字句.
LAG函数:
作用:访问相同结果集中先前行的数据,而用不使用 SQL Server 2016 中的自联接。 LAG 以当前行之前的给定物理偏移量来提供对行的访问。 在 SELECT 语句中使用此分析函数可将当前行中的值与先前行中的值进行比较。
语法:
LAG (scalar_expression [,offset] [,default])
OVER ( [ partition_by_clause ] order_by_clause ) 参数:
scalar_expression
要根据指定偏移量返回的值。 这是一个返回单个(标量)值的任何类型的表达式。 scalar_expression不能为分析的函数。
偏移量
当前行(从中获得取值)后的行数。 如果未指定,则默认值为 1。 偏移量可以是列、 子查询或计算结果为正整数其他表达式或可以隐式转换为bigint。 偏移量不能为负值或分析函数。
默认值
要返回时的值scalar_expression在偏移量为 NULL。 如果未指定默认值,则返回 NULL。 默认可以是列、 子查询或其他表达式,但不是能为分析的函数。 默认必须是类型兼容与scalar_expression。
通过( [ partition_by_clause ] order_by_clause)
partition_by_clause将划分为分区函数应用到的 FROM 子句生成的结果集。 如果未指定,则此函数将查询结果集的所有行视为单个组。 order_by_clause应用函数之前确定数据的顺序。 如果partition_by_clause指定,它确定分区中的数据的顺序。 Order_by_clause是必需的。
例如:
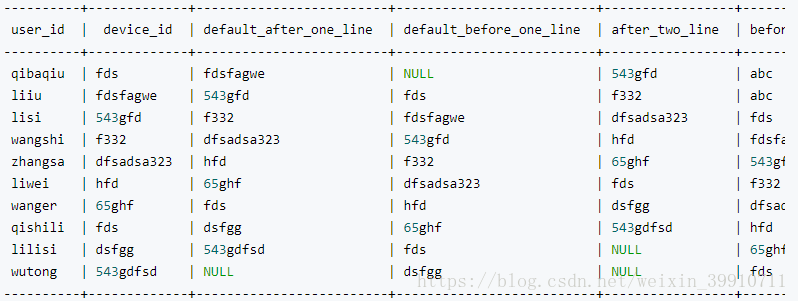
select user_id,device_id,
lead(device_id) over (order by sales) as default_after_one_line,
lag(device_id) over (order by sales) as default_before_one_line,
lead(device_id,2) over (order by sales) as after_two_line,
lag(device_id,2,'abc') over (order by sales) as before_two_line from order_detail;
结果:
9、结果保存为另一个表
select *
into tab_new
from
(
select distinct movie_ID
from data_more_5_paixv$) b
10、增加从1 开始递增的一列
alter table user_data_10 add user_ID int IDENTITY(1,1) NOT NULL
11、case when
SQL> select
2 count(case when u.sex=1 then 1 end)男性,
3 count(case when u.sex=2 then 1 end)女,
4 count(case when u.sex <>1 and u.sex<>2 then 1 end)性别为空
5 from users u;12 Sql中的并(UNION)、交(INTERSECT)、差(minus)、除去(EXCEPT)详解
12.1 UNION、union all
查询选修了180101号或180102号课程或二者都选修了的学生学号、课程号和成绩。
(SELECT 学号, 课程号, 成绩
FROM 学习
WHERE 课程号='180101')
UNION
(SELECT 学号, 课程号, 成绩
FROM 学习
WHERE 课程号='180102')
与SELECT子句不同,UNION运算自动去除重复。因此,在本例中,若只输出学生的学号,则相同的学号只出现一次。如果想保留所有的重复,则必须用UNION ALL代替UNION,且查询结果中出现的重复元组数等于两个集合中出现的重复元组数的和。
12.2 INTERSECT
查询同时选修了180101和180102号课程的学生学号、课程号和成绩。
(SELECT 学号, 课程号, 成绩
FROM 学习
WHERE 课程号='180101')
INTERSECT
(SELECT 学号, 课程号, 成绩
FROM 学习
WHERE 课程号='180102')
INTERSECT运算自动去除重复,如果想保留所有的重复,必须用INTERSECT ALL代替INTERSECT,结果中出现的重复元组数等于两集合出现的重复元组数里较少的那个。
intersect运算 返回查询结果中相同的部分既他们的交集
12.3 minus
minus-(oracle)
返回在第一个查询结果中与第二个查询结果不相同的那部分行记录,
即两个结果的差集
select * from abc2
minus
select * from abc ;
MINUS 指令是运用在两个 SQL 语句上。它先找出第一个 SQL 语句所产生的结果,然后看这些结果有没有在第二个 SQL 语句的结果中。如果有的话,那这一笔资料就被去除,而不会在最后的结果中出现。如果第二个 SQL 语句所产生的结果并没有存在于第一个 SQL 语句所产生的结果内,那这笔资料就被抛弃。
12.4 EXCEPT
查询选修了180101号课程的学生中没有选修180102号课程的学生学号、课程号和成绩。
(SELECT 学号, 课程号, 成绩
FROM 学习
WHERE 课程号='180101')
EXCEPT
(SELECT 学号, 课程号, 成绩
FROM 学习
WHERE 课程号='180102')
EXCEPT运算自动去除重复,如果想保留所有的重复,必须用EXCEPT ALL代替EXCEPT,结果中出现的重复元组数等于两集合出现的重复元组数之差(前提是差是正值)。
13 replace与regexp_replace函数
https://blog.csdn.net/gxftry1st/article/details/22489275
https://blog.csdn.net/itmyhome1990/article/details/50380718
13.1 REPLACE
传统的 REPLACE SQL 函数,它把一个字符串用另一个字符串来替换。假设您的数据在正文中有不必要的空格,您希望用单个空格来替换它们。利用 REPLACE 函数,您需要准确地列出您要替换多少个空格。
13.2 REGEXP_REPLACE
REGEXP_REPLACE 函数把替换功能向前推进了一步,其语法在下表中列出。以下查询用单个空格替换了任意两个或更多的空格。( ) 子表达式包含了单个空格,它可以按 {2,} 的指示重复两次或更多次。
| 语法 |
说明 |
| REGEXP_REPLACE(source_string, pattern |
该函数用一个指定的 replace_string 来替换匹配的模式,从而允许复杂的"搜索并替换"操作。 |
即
regexp_replace(1,2,3,4,5,6)
语法说明:1:字段 2:替换的字段 3:替换成什么 4:起始位置(默认从1开始) 5:替换的次数(0是无限次) 6:不区分大小写
REGEXP_REPLACE(source_char, pattern [, replace_string [, position [, occurrence [, match_parameter ] ] ] ] )
参数:
source_char
搜索值的字符表达式。这通常是一个字符列,可以是任何数据类型CHAR,VARCHAR2,NCHAR,NVARCHAR2,CLOB或NCLOB。
pattern
正则表达式
replace_string
可选。匹配的模式将被替换replace_string字符串。如果省略replace_string参数,将删除所有匹配的模式,并返回结果字符串。
position
可选。在字符串中的开始位置搜索。如果省略,则默认为1。
occurrence
可选。是一个非负整数默认为1,指示替换操作的发生:
match_parameter
可选。它允许你修改REGEXP_REPLACE功能匹配的行为。它可以是以下的组合:
| Value | Description |
| ‘c’ | 区分大小写的匹配. |
| ‘i’ | 不区分大小写的匹配. |
| ‘n’ | Allows the period character (.) to match the newline character. By default, the period is a wildcard. |
| ‘m’ | expression is assumed to have multiple lines, where ^ is the start of a line and $ is the end of a line, regardless of the position of those characters in expression. By default, expression is assumed to be a single line. |
| ‘x’ | Whitespace characters are ignored. By default, whitespace characters are matched like any other character. |
如果指定0,那么所有出现将被替换字符串。如果指定了正整数n,那么将替换第n次出现。
14 CONVERT() 函数
GETDATE() (getdate())函数来获得当前的日期/时间
定义和用法:
CONVERT() 函数是把日期转换为新数据类型的通用函数。
CONVERT() 函数可以用不同的格式显示日期/时间数据。
语法:
CONVERT(data_type(length),data_to_be_converted,style)data_type(length) 规定目标数据类型(带有可选的长度)。data_to_be_converted 含有需要转换的值。style 规定日期/时间的输出格式。
可以使用的 style 值:
| Style ID | Style 格式 |
|---|---|
| 100 或者 0 | mon dd yyyy hh:miAM (或者 PM) |
| 101 | mm/dd/yy |
| 102 | yy.mm.dd |
| 103 | dd/mm/yy |
| 104 | dd.mm.yy |
| 105 | dd-mm-yy |
| 106 | dd mon yy |
| 107 | Mon dd, yy |
| 108 | hh:mm:ss |
| 109 或者 9 | mon dd yyyy hh:mi:ss:mmmAM(或者 PM) |
| 110 | mm-dd-yy |
| 111 | yy/mm/dd |
| 112 | yymmdd |
| 113 或者 13 | dd mon yyyy hh:mm:ss:mmm(24h) |
| 114 | hh:mi:ss:mmm(24h) |
| 120 或者 20 | yyyy-mm-dd hh:mi:ss(24h) |
| 121 或者 21 | yyyy-mm-dd hh:mi:ss.mmm(24h) |
| 126 | yyyy-mm-ddThh:mm:ss.mmm(没有空格) |
| 130 | dd mon yyyy hh:mi:ss:mmmAM |
| 131 | dd/mm/yy hh:mi:ss:mmmAM |
实例:
下面的脚本使用 CONVERT() 函数来显示不同的格式。我们将使用 GETDATE() 函数来获得当前的日期/时间:
select CONVERT(VARCHAR(19),GETDATE())
select CONVERT(VARCHAR(10),GETDATE(),110)
select CONVERT(VARCHAR(11),GETDATE(),106)
select CONVERT(VARCHAR(24),GETDATE(),113)结果:
09 8 2018 12:03PM
09-08-2018
08 09 2018
08 09 2018 12:03:32:23315 DATENAME()的使用
1.获取星期(显示中文如:星期一)
Select DateName(dw,getdate())
2.获取季度
Select DateName(qq,getdate())
3.本年已过天数
Select Datename(dy,getdate())
4.本年第几个星期
Select Datename(wk,getdate())
第二个参数为指定日期数据,第一个参数说明如下:
| 日期部分 | 缩写 |
|---|---|
| year |
yy, yyyy |
| quarter |
qq, q |
| month |
mm, m |
| dayofyear |
dy, y |
| day |
dd, d |
| week |
wk, ww |
| weekday |
dw |
| hour |
hh |
| minute |
mi, n |
| second |
ss, s |
| millisecond |
ms |
16 sql获取当前时间
sql读取系统日期和时间的方法如下:
(1)--获取当前日期(如:yyyymmdd hh:MM:ss)
select GETDATE()
结果:2018-09-08 12:15:22.063
(2)--获取当前日期(如:yyyymmdd)
select CONVERT (nvarchar(12),GETDATE(),112)
结果:20180908
(3)--获取当前日期(如:yyyy-mm-dd)
Select Datename(year,GetDate())+'-'+Datename(month,GetDate())+'-'+Datename(day,GetDate())
结果:2018-09-8
(4)--获取当前日期(如:yyyy/mm/dd)
select DATENAME(YEAR,GETDATE())+'/'+DATENAME(MONTH,GETDATE())+'/'+DATENAME(DAY,GETDATE())
结果:2018/09/8
(5)其余方式
--获取几种日期
select DATENAME(YEAR,GETDATE()) --年份(YYYY)
select DATENAME(YY,GETDATE())
select DATENAME(MM,GETDATE()) --月份
select DATENAME(DD,GETDATE()) --日期
select dateName(hh,getdate()) --获取小时
select DATENAME(MI,GETDATE()) --获取分钟
select DATENAME(SECOND,GETDATE()) --获取秒
select DATENAME(WEEK,GETDATE()) --获取当前星期(周)是这一年中的第几个星期(周)
select DATENAME(WEEKDAY,GETDATE()) --星期几
select convert(char(8),getdate(),108) as yourtime--获取当前时间
SELECT convert(char(10),getdate(),120) as yourdate--获取当前日期
SELECT left(convert(char(10),getdate(),120),4) as youryear--获取当前年份
注:SYSDATE 是Oracle的函数。
17 to_date()、to_char()和TO_NUMBER (Oracle )
https://blog.csdn.net/zoucui/article/details/79347286
与date操作关系最大的就是两个转换函数:to_date(),to_char()
17.1 to_date()
to_date() 作用将字符类型按一定格式转化为日期类型,
TO_DATE(char[, '格式'])
具体用法:
to_date('2004-11-27','yyyy-mm-dd'),前者为字符串,后者为转换日期格式,注意,前后两者要以一对应。
如;to_date('2004-11-27 13:34:43', 'yyyy-mm-dd hh24:mi:ss') 将得到具体的时间
日期格式
格式控制 描述
YYYY、YYY、YY 分别代表4位、3位、2位的数字年
YEAR 年的拼写
MM 数字月
MONTH 月的全拼
MON 月的缩写
DD 数字日
DAY 星期的全拼
DY 星期的缩写
AM 表示上午或者下午
HH24、HH12 12小时制或24小时制
MI 分钟
SS 秒钟
SP 数字的拼写
TH 数字的序数词
17.2 TO_CHAR
是把日期或数字转换为字符串;
使用TO_CHAR函数处理数字:TO_CHAR(number, '格式')
TO_CHAR(salary,’$99,999.99’);
使用TO_CHAR函数处理日期:TO_CHAR(date,’格式’);
日期和字符转换函数用法:
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') as nowTime from dual; //日期转化为字符串
select to_char(sysdate,'yyyy') as nowYear from dual; //获取时间的年
select to_char(sysdate,'mm') as nowMonth from dual; //获取时间的月
select to_char(sysdate,'dd') as nowDay from dual; //获取时间的日
select to_char(sysdate,'hh24') as nowHour from dual; //获取时间的时
select to_char(sysdate,'mi') as nowMinute from dual; //获取时间的分
select to_char(sysdate,'ss') as nowSecond from dual; //获取时间的秒
17.3 TO_NUMBER
使用TO_NUMBER函数将字符转换为数字:TO_NUMBER(char[, '格式'])
18
https://blog.csdn.net/scgaliguodong123_/article/details/60881166
https://blog.csdn.net/scgaliguodong123_/article/details/60135385
19 数值计算函数(hive)
(1)round:四舍五入
取整:round(double a);
指定精度取整, round 语法: round(double a, int d)
select round(数值,小数点位数);
(2)ceil(ceiling):向上取整,返回等于或者大于该 double 变量的最小的整数
select ceil(45.6); --46
(3)floor:向下取整,返回等于或者小于该 double 变量的最大的整数
select floor(45.6); --45
hive中最高精度的数据类型是 double,只精确到小数点后16位,在做除法运算的时候要特别注意。
(4)自然指数: exp ,eg:exp(sales)
(5)自然对数: ln,eg:ln(price)
(6)取随机数: rand
说明: rand(),rand(int seed)。返回一个 0 到 1 范围内的随机数。如果指定种子 seed(整数),则会得到一个稳定的随机数序列。
(7)对数
以10为底对数: log10
以2为底对数: log2
log 语法: log(double base, double a) 说明: 返回以 base 为底的 a 的对数
(8)幂运算: pow power,eg:pow(2,4), power(2,4)
(9)开平方: sqrt,eg:sqrt(16)
(10)进制
二进制: bin
十六进制: hex
反转十六进制: unhex
进制转换: conv
语法: conv(BIGINT num, int from_base, int to_base)
说明: 将数值 num 从 from_base 进制转化到 to_base 进制
select bin(7),hex('19'),hex('abc'),unhex('616263'),unhex('41'),conv(17,10,16),conv(17,10,2) from order_detail limit 1;
(11)绝对值、三角函数、相反数
绝对值:abs
正取余:pmod (sql server 中为%)
正弦:sin
反正弦:asin
余弦:cos
反余弦:acos
返回A的值:positive
返回A的相反数:negative
select abs(-13),abs(10.10),pmod(9,4),pmod(-9,4), sin(0.8),
asin(0.7173560908995228),cos(0.9), acos(0.6216099682706644), positive(-10),negative(-10)
20 字符函数
(1)lower:转成小写
select lower('Hive'); --hive
(2)upper:转成大写
select upper('Hive'); --HIVE
| 方法 | MySql | Oracle |
|---|---|---|
| 转换大写 | upper()、ucase() | upper() |
| 转换小写 | lower()、lcase() | lower() |
(3)initcap()(Oracle):所有单词首字母与转换为大写。
(4)length:长度
select length('Hive'); --4
(5)concat:拼接字符串
select concat('hello','Hive'); --helloHive
(6)concat_ws:带分隔符字符串连接,eg:concat_ws('_',user_id,device_id,user_type)
(7)substr、substring:求子串
①语法: substr(string A, int start),substring(string A, int start)
说明:返回字符串 A 从 start 位置到结尾的字符串
②语法: substr(string A, int start, int len),substring(string A, int start, int len)
说明:返回字符串A从start位置开始,长度为len的字符串
select substr('hive',2); --ive
select substr('hive',2,1); --i
(8)trim:去掉前后的空格
select trim(' hive '); -hive
(9)ltrim:左边去空格
(10)rtrim:右边去空格
eg:select trim(' abc '),ltrim(' abc'),rtrim('abc ')
(11)lpad:左填充
语法: lpad(string str, int len, string pad)
说明:lpad将 str 进行用 pad 进行左补足到 len 位,
对hive填充到10位,补位用#
select lpad('hive',10,'#'); --######hive
(12)rpad:右填充
select rpad('hive',10,'#'); --hive######
rpad将 str 进行用 pad 进行右补足到 len 位
注意:与 GP,ORACLE 不同; pad不能默认
(13)reverse:字符串反转
eg:select reverse('fsfdghjhgfjg')
结果:gjfghjhgdfsf
(14)空格字符串:space
重复字符串:repeat
首字符ascii:ascii
select space(10), length(space(10)), repeat('abc',5), ascii('abcde')
21 正则
21.1 regexp_replace ,正则表达式替换(详见13)
说明:将字符串 A 中的符合 java 正则表达式 B 的部分替换为 C。
注意,在有些情况下要使用转义字符, 类似 oracle 中的 regexp_replace 函数。
21.2 regexp_extract 正则表达式解析:
(1)简介
regexp_extract(str, regexp[, idx]) - extracts a group that matches regexp
字符串正则表达式解析函数。
参数解释:
str是被解析的字符串或字段名
regexp 是正则表达式
idx 是返回结果 取表达式的哪一部分 默认值为1。0表示把整个正则表达式对应的结果全部返回;1表示返回正则表达式中第一个() 对应的结果, 以此类推 。
注意点:
要注意的是idx的数字不能大于表达式中()的个数。
实例:
1) select regexp_extract('hitdecisiondlist','(i)(.*?)(e)',0) ;
得到的结果为: itde
2) select regexp_extract('hitdecisiondlist','(i)(.*?)(e)',1) ;
得到的结果为: i
3) select regexp_extract('hitdecisiondlist','(i)(.*?)(e)',2) ;
得到的结果为: td
4) select regexp_extract('x=a3&x=18abc&x=2&y=3&x=4','x=([0-9]+)([a-z]+)',2) from default.dual;
得到的结果为: abc
此外,当前的语句只有2个()表达式 所以当idx>=3的时候 就会报错
(2)正则表达式的符号及意义
正则表达式由标准的元字符(metacharacters)所构成:
| / | 做为转意,即通常在"/"后面的字符不按原来意义解释,如/b/匹配字符"b",当b前面加了反斜杆后//b/,转意为匹配一个单词的边界。 |
| ^ | 匹配一个输入或一行的开头,/^a/匹配"an A",而不匹配"An a" |
| $ | 匹配一个输入或一行的结尾,/a$/匹配"An a",而不匹配"an A" |
| * | 匹配前面元字符0次或多次,/ba*/将匹配b,ba,baa,baaa |
| + | 匹配前面元字符1次或多次,/ba*/将匹配ba,baa,baaa |
| ? | 匹配前面元字符0次或1次,/ba*/将匹配b,ba |
| (x) | 匹配x保存x在名为$1...$9的变量中 |
| x|y | 匹配x或y |
| {n} | 精确匹配n次 |
| {n,} | 匹配n次以上 |
| {n,m} | 匹配n-m次 |
| [xyz] | 字符集(character set),匹配这个集合中的任一一个字符(或元字符) |
| [^xyz] | 不匹配这个集合中的任何一个字符 |
| [/b] | 匹配一个退格符 |
| /b | 匹配一个单词的边界 |
| /B | 匹配一个单词的非边界 |
| /cX | 这儿,X是一个控制符,//cM/匹配Ctrl-M |
| /d | 匹配一个字数字符,//d/ = /[0-9]/ |
| /D | 匹配一个非字数字符,//D/ = /[^0-9]/ |
| /n | 匹配一个换行符 |
| /r | 匹配一个回车符 |
| /s | 匹配一个空白字符,包括/n,/r,/f,/t,/v等 |
| /S | 匹配一个非空白字符,等于/[^/n/f/r/t/v]/ |
| /t | 匹配一个制表符 |
| /v | 匹配一个重直制表符 |
| /w | 匹配一个可以组成单词的字符(alphanumeric,这是我的意译,含数字),包括下划线,如[/w]匹配"$5.98"中的5,等于[a-zA-Z0-9] |
| /W | 匹配一个不可以组成单词的字符,如[/W]匹配"$5.98"中的$,等于[^a-zA-Z0-9]。 |
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
/num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]
[[:<:]],[[:>:]] 标记表示word边界。它们分别与word的开始和结束匹配。word是一系列字字符,其前面和后面均没有字字符。字字符是alnum类中的字母数字字符或下划线(_)
各种操作符的运算优先级:
/ 转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
22 URL解析
22.1 parse_url
语法: parse_url(string urlString, string partToExtract [, string keyToExtract])
说明:返回 URL 中指定的部分。
partToExtract 的有效值为: HOST, PATH, QUERY, REF,PROTOCOL, AUTHORITY, FILE, and USERINFO.
select
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'PATH'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY','k2'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'REF'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'PROTOCOL'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'AUTHORITY'),
parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'FILE')
结果:facebook.com、/path1/p.php、 k1=v1&k2=v2 、 v2 、
Ref1 、http、 facebook.com 、 /path1/p.php?k1=v1&k2=v2
22.2 parse_url_tuple
SELECT b.*
from ( select 'http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1' as urlstr from order_detail limit 1 )a
LATERAL VIEW
parse_url_tuple(a.urlstr, 'HOST', 'PATH', 'QUERY', 'QUERY:k1') b as host, path, query, query_k1 LIMIT 1;

23 json解析
23.1 get_json_object
语法: get_json_object(string json_string, string path)
说明:解析 json 的字符串 json_string,返回 path 指定的内容。如果输入的 json 字符串无效,那么返回 NULL。
select
get_json_object( '{"store": {"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"} }, "email":"amy@only_for_json_udf_test.net", "owner":"amy" }', '$.owner'),
get_json_object( '{"store": {"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"} }, "email":"amy@only_for_json_udf_test.net", "owner":"amy" }', '$.store.fruit[0].type') from order_detail limit 1;
结果:amy、apple
23.2 json_tuple
语法: json_tuple(string jsonStr,string k1,string k2, ...)
参数为一组键k1,k2……和JSON字符串,返回值的元组。
该方法比 get_json_object 高效,因为可以在一次调用中输入多个键.
select a.user_id, b.*
from order_detail a
lateral view
json_tuple('{"store": {"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"} }, "email":"amy@only_for_json_udf_test.net", "owner":"amy" }', 'email', 'owner') b as email, owner limit 1;
结果:

24 split
split(str, regex),返回值为一个数组
a.基本用法:
例1:split('a,b,c,d',',')
得到的结果:
["a","b","c","d"]
b.截取字符串中的某个值:
当然,我们也可以指定取结果数组中的某一项
例2:split('a,b,c,d',',')[0]
得到的结果:
a
c.特殊字符的处理:
特殊分割符号
regex 为字符串匹配的参数,所以遇到特殊字符的时候需要做特殊的处理
例3: "." 点
split('192.168.0.1','.')
得到的结果:[]
正确的写法:
split('192.168.0.1','\\.')
得到的结果:
["192","168","0","1"]
需要注意的是:
当然当split包含在 "" 之中时 需要加4个\
如 hive -e ".... split('192.168.0.1','\\\\.') ... " 不然得到的值是null
同样的 | 等特殊符号也需要做类似 处理。
25 str_to_map,string转map
语法:str_to_map(text[, delimiter1, delimiter2])
说明:使用两个分隔符将文本拆分为键值对。 Delimiter1将文本分成K-V对,Delimiter2分割每个K-V对。 对
于delimiter1默认分隔符是',',对于delimiter2默认分隔符是':'。
例1:select str_to_map('aaa:11&bbb:22', '&', ':')
from order_detail
limit 1;
结果:{"bbb":"22","aaa":"11"}
例2:select str_to_map('aaa:11&bbb:22', '&', ':')['aaa']
from order_detail
limit 1;
结果:11
例2:select str_to_map('aaa:11,bbb:22')
from person
limit 1;
结果:{"bbb":"22","aaa":"11"}
26 集合统计函数(hive)
(1)个数统计:count
(2)总和统计:sum
(3)平均值统计:avg
(4)最小值统计:min
(5) 最大值统计:max
(6)标准差:stddev_samp, stddev, stddev_pop
(7)方差:var_samp, var_pop
当我们需要真实的标准差/方差的时候最好是使用: stddev 、stddev_pop、 var_pop
而只是需要得到少量数据的标准差/方差的近似值可以选用: stddev_samp、 var_samp
(8)百分位数: percentile
percentile(col, p),返回col列p分位上的值,要求输入的字段必须是int类型的
(9)近似百分位数: percentile_approx
语法: percentile_approx(DOUBLE col, p [, B])
返回值: double
说明: 求近似的第 p个百分位数, p 必须介于 0 和 1 之间,返回类型为 double,但是col 字段支持浮点类型。参数 B 控制内存消耗的近似精度, B越大,结果的准确度越高。默认为 10,000。 当 col 字段中的 distinct 值的个数小于 B 时,结果为准确的百分位数。
后面可以输入多个百分位数,返回类型也为 array
select percentile(sales,array(0.2,0.4,0.6)), percentile_approx(sales,array(0.2,0.4,0.6),10000) from order_detail;
结果:

(10)直方图: histogram_numeric
语法: histogram_numeric(col, b)
返回值: array
说明: 以b为基准计算col的直方图信息。
27 复杂类型访问操作及统计函数
数据表employees:

27.1 访问数组 Map 结构体
select name,salary, subordinates[1],deductions['k2'],deductions['k3'],address.city
from employees;
结果:

27.2 Map类型长度 Array类型长度
select size(deductions),size(subordinates)
from employees
limit 1;

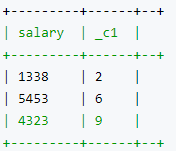
27.3 类型转换: cast
select cast(salary as int),cast(deductions['k2'] as bigint)
from employees;
结果:
27.4 explode
explode(ARRAY) 列表中的每个元素生成一行
explode(MAP) map中每个key-value对,生成一行,key为一列,value为一列
总结起来一句话:explode就是将hive一行中复杂的array或者map结构拆分成多行。
27.5 LATERAL VIEW (lateral view)行转列
例1:SELECT name, ad_subordinate
FROM employees
LATERAL VIEW explode(subordinates) addTable AS ad_subordinate;
结果:

注:addTable ,添加到表
例2:SELECT name, count(1)
FROM employees
LATERAL VIEW explode(subordinates) addTable AS ad_subordinate
group by name;
结果:

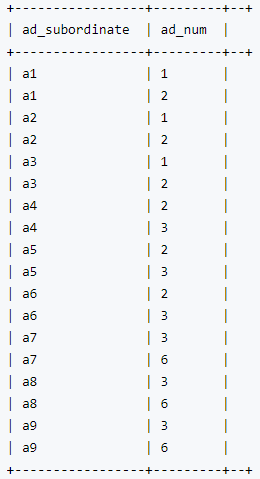
例3:SELECT ad_subordinate, ad_num
FROM employees
LATERAL VIEW explode(subordinates) addTable AS ad_subordinate
LATERAL VIEW explode(happy_num) addTable2 AS ad_num;
结果:
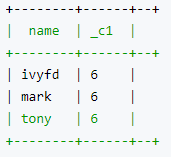
例4:多个LATERAL VIEW
SELECT name, count(1)
FROM employees
LATERAL VIEW explode(subordinates) addTable AS ad_subordinate
LATERAL VIEW explode(happy_num) addTable2 AS ad_num
group by name;
结果:
例5:不满足条件产生空行
SELECT AA.name, BB.*
FROM employees AA
LATERAL VIEW explode(array()) BB AS a
limit 10;
结果:
例6:OUTER 避免永远不产生结果,无满足条件的行,在该列会产生NULL值。
SELECT AA.name, BB.*
FROM employees AA
LATERAL VIEW OUTER explode(array()) BB AS a
limit 10;
结果:

例7:字符串切分成多列
SELECT name, word
FROM employees
LATERAL VIEW explode(split(happy_word,',')) addTable AS word;
结果:

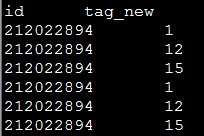
27.6 列转行(collect_list、collect_set )
测试数据t_column_to_row:
使用函数:concat_ws(',',collect_set(column))
说明:collect_list 不去重,collect_set 去重(Python的集合中的元素不允许有重复值)。 column 的数据类型要求是 string
例1(collect_set 去重):
select id,
concat_ws(',',collect_set(tag_new)) as tag_col
from t_column_to_row
group by id;
结果:
![]()
例2(collect_list 不去重):
select id,
concat_ws(',',collect_list(tag_new)) as tag_col
from t_column_to_row
group by id;
结果:
![]()
28 窗口函数、分析函数、增强group
窗口函数与分析函数
应用场景:
(1)用于分区排序
(2)动态Group By
(3)Top N
(4)累计计算
(5)层次查询
窗口函数:
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
LAST_VALUE: 取分组内排序后,截止到当前行,最后一个值
LEAD(col,n,DEFAULT) :用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
LAG(col,n,DEFAULT) :与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
OVER从句:
1、使用标准的聚合函数COUNT、SUM、MIN、MAX、AVG
2、使用PARTITION BY语句,使用一个或者多个原始数据类型的列
3、使用PARTITION BY与ORDER BY语句,使用一个或者多个数据类型的分区或者排序列
4、使用窗口规范,窗口规范支持以下格式:
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] PRECEDING AND (UNBOUNDED | [num]) FOLLOWING当ORDER BY后面缺少窗口从句条件,窗口规范默认是 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
当ORDER BY和窗口从句都缺失, 窗口规范默认是 ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
OVER从句支持以下函数, 但是并不支持和窗口一起使用它们。
Ranking函数: Rank, NTile, DenseRank, CumeDist, PercentRank.
分析函数:
①ROW_NUMBER() 从1开始,按照顺序,生成分组内记录的序列,比如,按照pv降序排列,生成分组内每天的pv名次,ROW_NUMBER()的应用场景非常多,再比如,获取分组内排序第一的记录;获取一个session中的第一条refer等。
②RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
③DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
④CUME_DIST 小于等于当前值的行数/分组内总行数。比如,统计小于等于当前薪水的人数,所占总人数的比例
⑤PERCENT_RANK 分组内当前行的RANK值-1/分组内总行数-1
⑥NTILE(n) 用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)。
28.1 COUNT、SUM、MIN、MAX、AVG
用于实现分组内所有和连续累积的统计。
数据:

以SUM为例:
SELECT cookieid, createtime, pv,
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS pv1, -- 默认为从起点到当前行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS pv2, --从起点到当前行,结果同pv1
SUM(pv) OVER(PARTITION BY cookieid) AS pv3, --分组内所有行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv4, --当前行+往前3行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS pv5, --当前行+往前3行+往后1行
SUM(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS pv6 ---当前行+往后所有行
FROM lxw1234;
结果:

pv1: 分组内从起点到当前行的pv累积,如,11号的pv1=10号的pv+11号的pv, 12号=10号+11号+12号
pv2: 同pv1
pv3: 分组内(cookie1)所有的pv累加
pv4: 分组内当前行+往前3行,如,11号=10号+11号, 12号=10号+11号+12号, 13号=10号+11号+12号+13号, 14号=11号+12号+13号+14号
pv5: 分组内当前行+往前3行+往后1行,如,14号=11号+12号+13号+14号+15号=5+7+3+2+4=21
pv6: 分组内当前行+往后所有行,如,13号=13号+14号+15号+16号=3+2+4+4=13,14号=14号+15号+16号=2+4+4=10
注意: ①结果和ORDER BY相关,默认为升序
②如果不指定ROWS BETWEEN,默认为从起点到当前行;
③如果不指定ORDER BY,则将分组内所有值累加;
ROWS BETWEEN含义,也叫做WINDOW子句:
① PRECEDING:往前 (preceding)
② FOLLOWING:往后 (following)
③ CURRENT ROW:当前行 (current row)
④ UNBOUNDED:无界限(起点或终点) (unbounded)
⑤ UNBOUNDED PRECEDING:表示从前面的起点 (unbounded preceding)
⑥ UNBOUNDED FOLLOWING:表示到后面的终点 (unbouneed following)
其他COUNT、AVG,MIN,MAX,和SUM用法一样。
28.2 RANK、ROW_NUMBER、DENSE_RANK
ROW_NUMBER() OVER(PARTITION BY COLUMN1 ORDER BY COLUMN2)
上述代码含义是首先根据COLUMN1进行结果集分组,结果集内部按照COLUMN2分组,输出结果是类似于双重分组的结果。
这里根据column分区,并未每个分区返回一个数字,递增的1.2.3.4.5.6......。
ROW_NUMBER() OVER (ORDER BY column DESC)
是先把column列降序,再为降序以后的每条xlh记录返回一个数组1.2.3.....。
select user_id, user_type, sales,
RANK() over (partition by user_type order by sales desc) as r,
ROW_NUMBER() over (partition by user_type order by sales desc) as rn,
DENSE_RANK() over (partition by user_type order by sales desc) as dr
from order_detail;
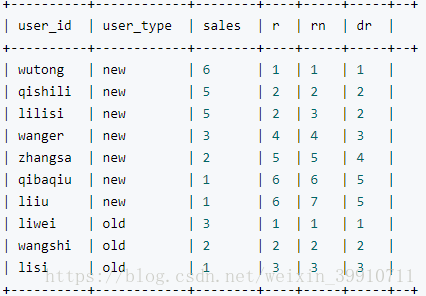
区别:
rank() 排序相同时会重复,总数不会变
row_number() 会根据顺序计算
dense_rank()排序相同时会重复,总数会减少
28.3 first_value与last_value
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
例如:
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
FROM lxw1234;
cookieid createtime url rn first1
---------------------------------------------------------
cookie1 2015-04-10 10:00:00 url1 1 url1
cookie1 2015-04-10 10:00:02 url2 2 url1
cookie1 2015-04-10 10:03:04 1url3 3 url1
cookie1 2015-04-10 10:10:00 url4 4 url1
cookie1 2015-04-10 10:50:01 url5 5 url1
cookie1 2015-04-10 10:50:05 url6 6 url1
cookie1 2015-04-10 11:00:00 url7 7 url1
cookie2 2015-04-10 10:00:00 url11 1 url11
cookie2 2015-04-10 10:00:02 url22 2 url11
cookie2 2015-04-10 10:03:04 1url33 3 url11
cookie2 2015-04-10 10:10:00 url44 4 url11
cookie2 2015-04-10 10:50:01 url55 5 url11
cookie2 2015-04-10 10:50:05 url66 6 url11
cookie2 2015-04-10 11:00:00 url77 7 url11
LAST_VALUE:取分组内排序后,截止到当前行,最后一个值
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM lxw1234;
cookieid createtime url rn last1
-----------------------------------------------------------------
cookie1 2015-04-10 10:00:00 url1 1 url1
cookie1 2015-04-10 10:00:02 url2 2 url2
cookie1 2015-04-10 10:03:04 1url3 3 1url3
cookie1 2015-04-10 10:10:00 url4 4 url4
cookie1 2015-04-10 10:50:01 url5 5 url5
cookie1 2015-04-10 10:50:05 url6 6 url6
cookie1 2015-04-10 11:00:00 url7 7 url7
cookie2 2015-04-10 10:00:00 url11 1 url11
cookie2 2015-04-10 10:00:02 url22 2 url22
cookie2 2015-04-10 10:03:04 1url33 3 1url33
cookie2 2015-04-10 10:10:00 url44 4 url44
cookie2 2015-04-10 10:50:01 url55 5 url55
cookie2 2015-04-10 10:50:05 url66 6 url66
cookie2 2015-04-10 11:00:00 url77 7 url77
如果不指定ORDER BY,则默认按照记录在文件中的偏移量进行排序,会出现错误的结果。
如果想要取分组内排序后最后一个值,则需要变通一下:(使用FIRST_VALUE与DESC)
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime DESC) AS last2
FROM lxw1234
ORDER BY cookieid,createtime;
cookieid createtime url rn last1 last2
-------------------------------------------------------------
cookie1 2015-04-10 10:00:00 url1 1 url1 url7
cookie1 2015-04-10 10:00:02 url2 2 url2 url7
cookie1 2015-04-10 10:03:04 1url3 3 1url3 url7
cookie1 2015-04-10 10:10:00 url4 4 url4 url7
cookie1 2015-04-10 10:50:01 url5 5 url5 url7
cookie1 2015-04-10 10:50:05 url6 6 url6 url7
cookie1 2015-04-10 11:00:00 url7 7 url7 url7
cookie2 2015-04-10 10:00:00 url11 1 url11 url77
cookie2 2015-04-10 10:00:02 url22 2 url22 url77
cookie2 2015-04-10 10:03:04 1url33 3 1url33 url77
cookie2 2015-04-10 10:10:00 url44 4 url44 url77
cookie2 2015-04-10 10:50:01 url55 5 url55 url77
cookie2 2015-04-10 10:50:05 url66 6 url66 url77
cookie2 2015-04-10 11:00:00 url77 7 url77 url77
28.4 LEAD、LAG函数
LEAD(col,n,DEFAULT) :用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
LAG(col,n,DEFAULT) :与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
详见8。
28.5 Ntile
可以看成是:它把有序的数据集合平均分配到指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
语法是:ntile (num) over ([partition_clause] order_by_clause) as your_bucket_num
然后可以根据桶号,选取前或后 n分之几的数据。
数据会完整展示出来,只是给相应的数据打标签;具体要取几分之几的数据,需要再嵌套一层根据标签取出。
例(1):
select
user_type,sales,
--分组内将数据分成2片
NTILE(2) OVER(PARTITION BY user_type ORDER BY sales) AS nt2,
--分组内将数据分成3片
NTILE(3) OVER(PARTITION BY user_type ORDER BY sales) AS nt3,
--分组内将数据分成4片
NTILE(4) OVER(PARTITION BY user_type ORDER BY sales) AS nt4,
--将所有数据分成4片
NTILE(4) OVER(ORDER BY sales) AS all_nt4
from
order_detail
order by
user_type,
sales结果:

例(2):
select
user_id
from
(
select
user_id,
NTILE(5) OVER(ORDER BY sales desc) AS nt
from
order_detail
)A
where nt=1;28.6 CUME_DIST、PERCENT_RANK、ratio_to_report
28.6.1 CUME_DIST
小于等于当前值的行数/分组内总行数。比如,统计小于等于当前薪水的人数,所占总人数的比例
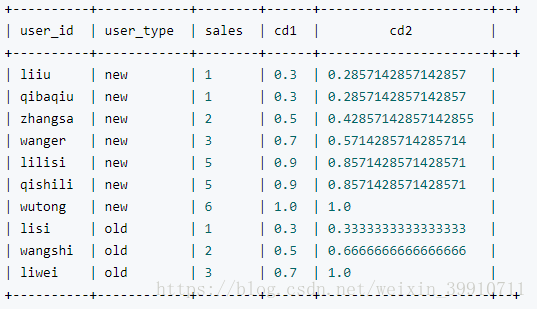
例如:
select
user_id,user_type,sales,
--没有partition,所有数据均为1组
CUME_DIST() OVER(ORDER BY sales) AS cd1,
--按照user_type进行分组
CUME_DIST() OVER(PARTITION BY user_type ORDER BY sales) AS cd2
from order_detail; 结果:
28.6.2 PERCENT_RANK
分组内当前行的RANK值-1/分组内总行数-1
select
user_type,sales
--分组内总行数
SUM(1) OVER(PARTITION BY user_type) AS s,
--RANK值
RANK() OVER(ORDER BY sales) AS r,
PERCENT_RANK() OVER(ORDER BY sales) AS pr,
--分组内
PERCENT_RANK() OVER(PARTITION BY user_type ORDER BY sales) AS prg
from
order_detail; 结果:

28.6.3 ratio_to_report,百分比
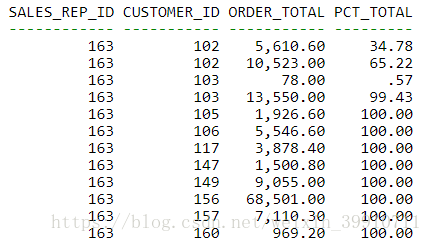
ratio_to_report() over() 第一个括号中就是分子,over() 括号中就是分母,分母缺省就是整个占比
SELECT
sales_rep_id,
customer_id,
order_total,
ROUND(100*ratio_to_report(order_total)
OVER (PARTITION BY customer_id),2) pct_total
FROM
orders
WHERE
sales_rep_id = 163
ORDER BY
sales_rep_id, customer_id, order_id结果:
28.7 增强的聚合 Cube和Grouping 和Rollup
28.7.1 GROUPING SETS
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL。
GROUPING SETS作为GROUP BY的子句,允许开发人员在GROUP BY语句后面指定多个统计选项,可以简单理解为多条group by语句通过union all把查询结果聚合起来结合起来。
其中的GROUPING__ID,表示结果属于哪一个分组集合。
例1:
select
user_type,
sales,
count(user_id) as pv,
GROUPING__ID
from
order_detail
group by
user_type,sales
GROUPING SETS(user_type,sales)
ORDER BY
GROUPING__ID;
结果:

例2:
select
user_type,
sales,
count(user_id) as pv,
GROUPING__ID
from
order_detail
group by
user_type,sales
GROUPING SETS(user_type,sales,(user_type,sales))
ORDER BY
GROUPING__ID;结果:

例3:
select device_id,os_id,app_id,count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id
grouping sets((device_id),(os_id),(device_id,os_id),())等价于:
SELECT device_id,null,null,count(user_id)
FROM test_xinyan_reg group by device_id
UNION ALL
SELECT null,os_id,null,count(user_id)
FROM test_xinyan_reg group by os_id
UNION ALL
SELECT device_id,os_id,null,count(user_id)
FROM test_xinyan_reg group by device_id,os_id
UNION ALL
SELECT null,null,null,count(user_id)
FROM test_xinyan_reg28.7.2 CUBE
根据GROUP BY的维度的所有组合进行聚合。cube简称数据魔方,可以实现hive多个任意维度的查询,cube(a,b,c)则首先会对(a,b,c)进行group by,然后依次是(a,b),(a,c),(a),(b,c),(b),(c),最后在对全表进行group by,他会统计所选列中值的所有组合的聚合
select
user_type,
sales,
count(user_id) as pv,
GROUPING__ID
from
order_detail
group by
user_type,sales
WITH CUBE
ORDER BY
GROUPING__ID;
结果:

28.7.3 ROLLUP
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。实现从右到左递减多级的统计,显示统计某一层次结构的聚合。
例1:
select
user_type,
sales,
count(user_id) as pv,
GROUPING__ID
from
order_detail
group by
user_type,sales
WITH ROLLUP
ORDER BY
GROUPING__ID;结果:

例2:
select device_id,os_id,app_id,client_version,from_id,count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id,client_version,from_id with rollup;
等价于:
select device_id,os_id,app_id,client_version,from_id,count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id,client_version,from_id
grouping sets ((device_id,os_id,app_id,client_version,from_id),
(device_id,os_id,app_id,client_version),(device_id,os_id,app_id),
(device_id,os_id),(device_id),());
28.8 nulls first、nulls last
Nulls first和nulls last是Oracle Order by支持的语法
如果Order by 中指定了表达式Nulls first则表示null值的记录将排在最前(不管是asc 还是 desc)
如果Order by 中指定了表达式Nulls last则表示null值的记录将排在最后 (不管是asc 还是 desc)
使用语法如下:
--将nulls始终放在最前
select * from zl_cbqc order by cb_ld nulls first
--将nulls始终放在最后
select * from zl_cbqc order by cb_ld desc nulls last
29 with as 、子查询部分
当我们书写一些结构相对复杂的SQL语句时,可能某个子查询在多个层级多个地方存在重复使用的情况,这个时候我们可以使用 with as 语句将其独立出来。
(1)介绍
with as 也叫做子查询部分,首先定义一个sql片段,该sql片段会被整个sql语句所用到,为了让sql语句的可读性更高些,作为提供数据的部分,也常常用在union等集合操作中。
with as就类似于一个视图或临时表,可以用来存储一部分的sql语句作为别名,不同的是with as 属于一次性的,而且必须要和其他sql一起使用才可以!
其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,这可以大大的简化SQL;更重要的是:一次分析,多次使用,这也是为什么会提供性能的地方,达到了“少读”的目标。
WITH t1 AS (
SELECT *
FROM carinfo
),
t2 AS (
SELECT *
FROM car_blacklist
)
SELECT *
FROM t1, t2(2) 注意
1 with子句必须在引用的select语句之前定义,同级with关键字只能使用一次,多个只能用逗号分割;最后一个with 子句与下面的查询之间不能有逗号,只通过右括号分割,with 子句的查询必须用括号括起来.
2 如果定义了with子句,但其后没有跟select查询,则会报错!
3 前面的with子句定义的查询在后面的with子句中可以使用。但是一个with子句内部不能嵌套with子句!
例如:
with t1 as (select * from carinfo),
t2 as (select t1.id from t1)
select * from t2