python2.7 入门第一天
一、思考
1.1 时间管理与人生目标
《番茄时间管理法》、
要事优先(工作第一、学习第二),每天学习一小时
1.2 知识积累
1 做笔记(有索引、代码是可以运行的)
2 音频
3 视频
1.3 程序组成
程序的组成?
- 数据结构:存储数据的格式或模型
- 算法:解决问题的步骤
二、python的入门
2.1 python的安装与配置
Python的下载地址:www.python.org 推荐使用2.7
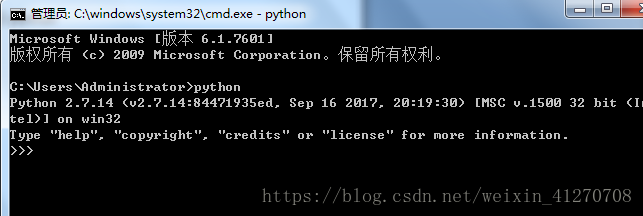
安装后配置环境变量,然后在cmd中运行 python,检查是否配置成功
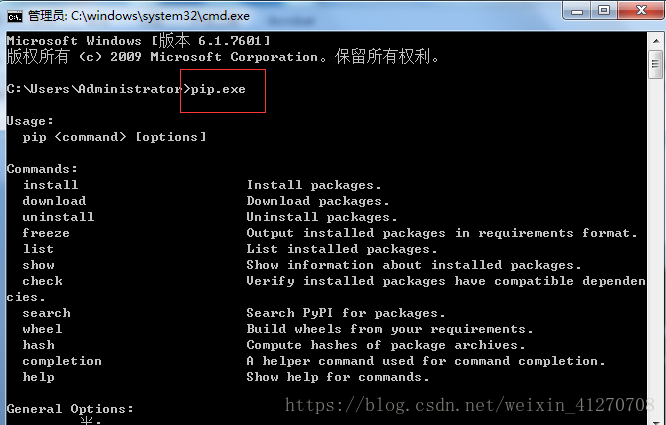
用exit()或者ctrl +z 退出,然后输入pip 或者pip.exe,检查pip是否可以使用
2.2 pip的使用
Pip 是什么?
安装和管理包的工具
Pip的常用命令:
pip list
pip install nose
pip show nose
pip uninstall nose
pip install nose==1.3.7
py -2 –m pip install chardet
py -3 –m pip install chardet
2.3 Python的基本语法
2.3.1 断言的使用
a=1
b=2
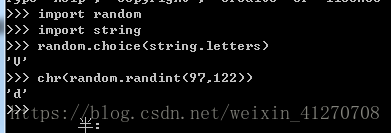
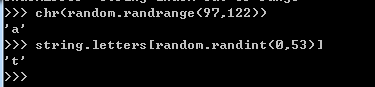
assert a 1) 数字类型 a=1 type(a) int b=1L type(b) long c=1.3 type(c) float d=1+3j type(d) complex 备注:python 3中没有long 型 2) 字符串类型 S=”abcd” type(S) S1=u”abcd” type(S1) type(S1.encode(“gbk”)) type(S1.encode(“gbk”).decode(“gbk”)) 3) 列表类型 a=[1,2,3,”abcd”] type(a) list 4) 元组类型 b=(1,2,”abc”) type(b) tuple 5) 字典类型 c={“name”:”wxg”,”age”:19,”color”:”red”} type(c) dict 6) 类和实例 class p(object): pass #占位符 p1=p() #类的实例化 type(p1) type(p) 备注:列表、字典是可以改变的,元组不可变 a=’abc’ isinstance(a,(str,int)) b=1+2j isinstance(b,complex) c={“name”:”wxg”,”age”:17} isinstance(c,dict) 小练习: 声明所有类型的变量,并且使用函数判断类型的结果都是true 将给定参数转换为布尔类型,如果没有参数,返回false 备注:当对bool不太熟悉时,可以使用dir(bool) 查看方法, 1) 算术运算符 a=1 b=2 print a/b 0 原因a,b都是整形,返回结果也是整形 print float(a)/b 0.5 print b*b*b 8 print b**b**b 16 print pow(2,3) 8 print 5%2 1 2) 逻辑运算符 a=1 b=2 if isinstance(a,int) and isinstance(b,int): else: print(“类型不匹配”) 备注:代码中推荐使用4个空格 第一个bug,垃圾数据没有被清理,导致的系统运行异常。当时是一个审批流程,总共需要5级审批,上级审批提交5分钟后下一级才可以处理;为了测试方便,让开发改为审批提交后立即生效,多做了几条,上午一切ok,到了下午发现流程异常。经过排查,是之前提交的脏数据所致,脏数据越来越多,没有被清理,最后导致运行异常,清理过数据之后,系统恢复正常。本次测试是基于经验的测试,加快审批流程并且考虑异常的操作,使用了场景法设计该用例。 第二个bug,是一个注册手机号的测试。用滴滴打车软件,注册最新的号段166,结果发现无法注册成功,提示输入的手机号无效,后来和客服沟通并且提交反馈意见,3天后成功解决。滴滴打车软件注册数据库中只匹配了常用的号段,对于最新的或者未来可能会出现的号段没有做预留和评估,导致部分用户没法正常使用。本次测试是基于经验的测试,使用了等级类的测试方法,不仅使用常用的手机号,也使用最新的或者未来可能使用的新手机号。 第三个bug,是一个app退出后重新登陆的测试。先使用一个有数据的账号登陆,然后退出,再次登陆时使用一个刚注册的账号,结果发现登陆进去之后有数据,和上个账号看到的信息一样;和开发沟通后发现,第一个账号退出时没有清理缓存数据,导致第二个账号登陆后可以直接看到信息。本次测试是基于经验的测试,使用错误探测法,对可能出现问题的地方进行测试,避免了用户信息的泄漏。 小数转化为整数 int(float(1.3)) round(1.4) int(1.3) 工厂函数 str(1) 使用str 、int、float对数据做类型转换 备注:range(1,10) 其中右边是开区间,不包括10 eg:while 循环三次,并打印输入结果 a=[] a.append(1) a.append(2) a.append(3) 在尾部插入 a.insert(1,2) 基于坐标的插入 练习:构造一个list,从1到100,使用循环 方法一:range(1,101) 方法二: c=[] for i in range(1,101): c.append(i) a[1] print a[1] len(a) print a[len(a)-1] 最后一个 a[-1] a[-2] dir(__builtins__) 内置函数 a=[1,1,2,2,3,3,1,1] a[1]=2 a[-1]="abc" a=[1,1,2,2,3,3,1,1] del a[3] del a 什么是遍历? 从头查到尾 遍历的作用? 显示所有元素;找到需要的元素 练习:a=[1,1,2,2,3,3,1,1],统计a中有多少个1 算法: 1 遍历 2 当遍历时,找到一个1,我就去改变1的数量 3 遍历完就解决这个问题 程序: count=0 for i in a: if i==1: count=count+1 print count 备注: for x in 序列(某个类实例实现了__iter__): do sth 序列包括:list tuple str s=['a','b','c'] " ".join(s) " ".join(s).split() "a*b*c".split() a=["x",1,2,3,4] result="" for i in a: result=result+str(i) print result 或者 元组转换为字符串 (1,2) type((1,2)) str((1,2)) '(1, 2)' type(str((1,2))) b=(1,2,[1]) b[2].append(3) b 遍历元组中的元素 b= (1, 2, [1, 3]) for i in b: print i 备注: 不可变类型:整数、小数、复数、字符串、元组 可变:集合、列表、字典 定义一个字典,并且遍历该字典中的元素 d={1: 'abcd', 2: '22'} for i,j in d.items(): print i,j 或者 d={1: 'abcd', 2: '22'} d.has_key(1) d.has_key(2) d.has_key(3) if d.has_key(2): print d[2] d={1: 'abcd', 2: '22'} d[3]=99 #如果没有新增 d[2]=123 d[2]=12345 #如果存在就修改 练习: a=[1, 1, 1, 1, 2, 2, 2, 3],按照字典的方式统计有多少不一样的值 算法: 1声明一个空字典对象 d={} 2 逐一读取每一个list的值,让每个值作为字典的key,然后随便赋值一个value for i in a: d[i]="good" 3 将字典的全部key读出,并存在一个变量里 new_list=d.keys() 完成以上三步就完成了列表内容的排重 print new_list 备注: 字典不是序列 序列包括:列表、元组、字符串(序列是可以顺序访问) 练习: 从序列和字典中查找一个值,谁快?(10000个) 字典不用遍历,所以快;序列需要逐一遍历 哈希:有书目,大纲每一个小节都对应一个页数 书目:字符串操作的章节 存的时候都会有key和value,hash函数(key)--->地址:value 查找 hash函数(key)---->>内存地址 备注1(关于索引): a=[1,2,3,4] a[0] #索引只是表示在列表中的位置 a[1] 备注2(如何问问题): 1 代码要简化 2 所有的报错发给,翻译 3 你尝试了哪些做法来发现(算法写出来,每个算法的步骤期望值、实际值,期望和实际值的差异在哪里) 4 你想不通的地方是哪里? 1 文件保存为utf-8 2 文件头加编码声明 #--coding:utf-8-- 3 所有中文前加u,例如:u"我" 实例:生成一个随机的字母 方法一: import random import string random.choice(string.letters) 方法二: chr(random.randint(97,122)) random.sample([1,2,3,4],2) #随机取出其中的两个数字 chr(random.randrange(97,122)) string.letters[random.randint(0,52)]2.3.2 变量的基本类型
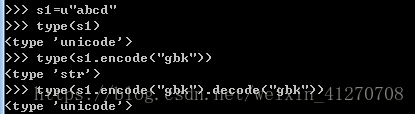
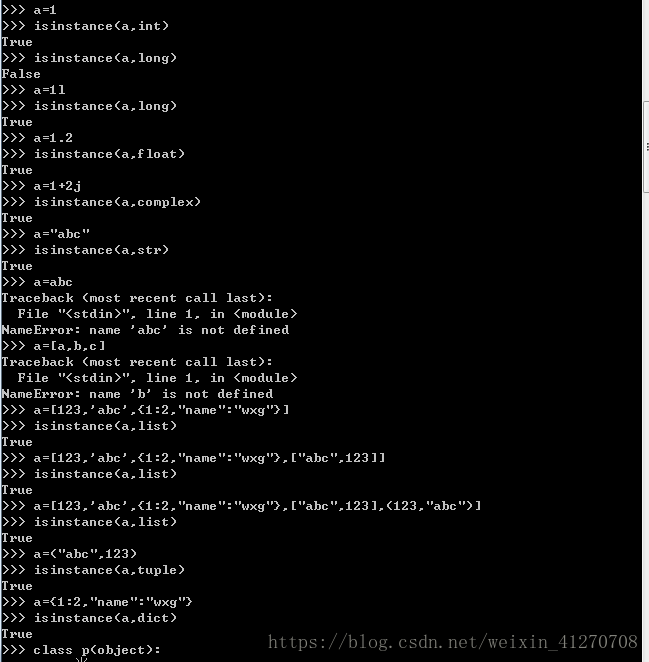
2.3.3 isinstance的使用
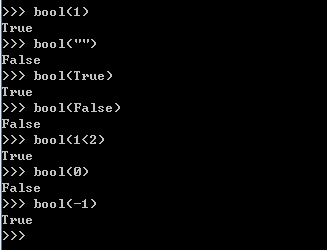
2.3.4 bool的使用
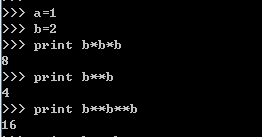
2.3.5 常用运算符
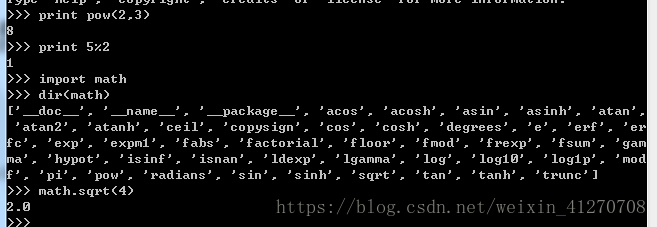
print a+b2.3.6 骄傲的bug
2.3.7 类型转换

2.3.8 while循环

2.4 列表的增删改查
2.4.1 列表的增
2.4.2 列表的查
2.4.3 列表的改
2.4.4 列表的删
2.4.5 遍历算法的使用
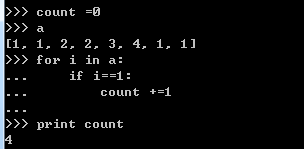
2.4.6 join函数与split 函数
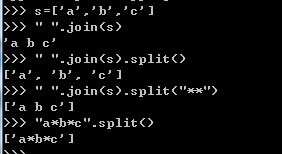
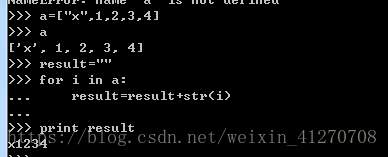
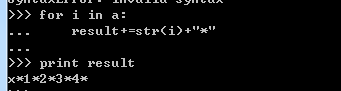
2.4.7 类型转换
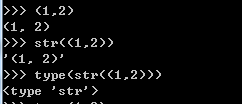
2.5 元组的操作

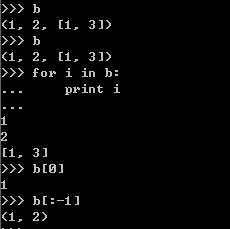
2.6 字典的使用
2.6.1 字典的遍历
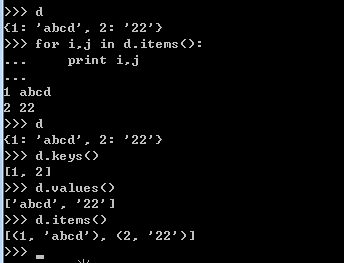
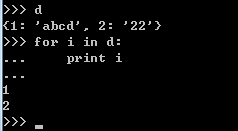
2.6.2 字典has_key()的使用
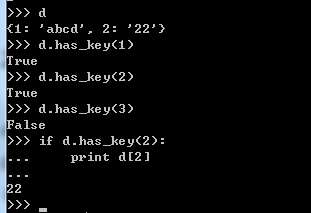
2.6.3 字典的修改
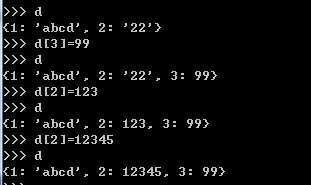
2.6.4 字典的排重
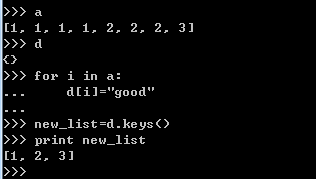
2.6.5 序列和字典查询比较
2.6.6 文件中文正常显示三步曲
2.7 choice的使用
import random