Python: 运用selenium爬取下拉框数据 《中国省市县地区代码表》
最近看李永乐老师的一期视频,讲解中国身份证号每个数字的含义。
得知身份证的前六位数字,分别代表省-市-县/区。
由此想找一份 中国省市县地区代码表,发现一个网址自动生成身份证号,内含代码表。
下拉框数据没有爬取过,便尝试并学习下。
中国城乡代码格式详解
第1-2位表示省(自治区、直辖市、特别行政区)。
第3-4位表示市(地级市、自治州、盟及国家直辖市所属市辖区和县的汇总码)。其中,01-20,51-70表示省直辖市;21-50表示地区(自治州、盟)。
第5-6位表示县(市辖区、县级市、旗)。01-18表示市辖区或地区(自治州、盟)辖县级市;21-80表示县(旗);81-99表示省直辖县级市。
- 网页分析。地址选择有 省--province;市/州--city;县/区--country。
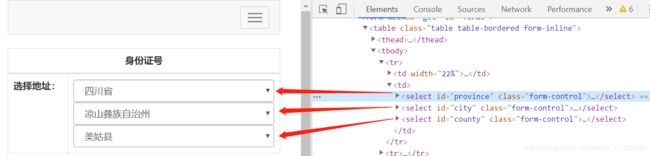
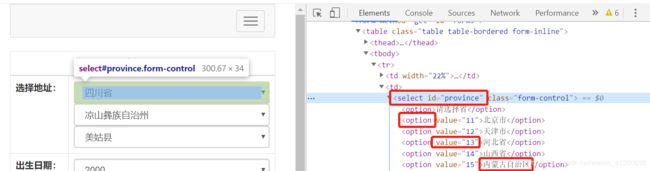
都包含在 'select' 下,每一个option都有对应的 value值 和 选择项内容。
以下为主程序。首先使用selenium模拟启动chrome浏览器,打开网页,再模拟点击选择动作,每获取一条省-市-区的数据,存入DataFrame中。其中选择顺序为,先选省再选市最后选区县,该市管辖的区县选完再换市,当该省管辖的市选广域完再换省。
selenium 怎么定位 select 框,选择 select 里的选项
s1 = Select(browser.find_element_by_id('province')) # 实例化Select
s1.select_by_index(2) # 选择第2项选项
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support.select import Select
from selenium.webdriver.support import expected_conditions as EC
import urllib3
urllib3.disable_warnings()
def main():
# 创建dataframe
chain_ID = pd.DataFrame(columns=['province_code', 'province',
'city_code', 'city',
'county_code', 'county'])
print('模拟打开浏览器')
browser = brower()
# 省
print('获取 ‘省’ 信息')
s_province = Select(browser.find_element_by_id('province')) # 实例化Select
for i in range(1, len(s_province.options)):
province_code, province_name = get_text(browser, i, s_province, 'province')
# 城市
print('获取 ‘市’ 信息')
s_city = Select(browser.find_element_by_id('city'))
for j in range(1, len(s_city.options)):
city_code, city_name = get_text(browser, j, s_city, 'city')
# 县/区
print('获取 ‘县/区’ 信息')
s_county = Select(browser.find_element_by_id('county'))
for k in range(1, len(s_county.options)):
county_code, county_name = get_text(browser, k, s_county, 'county')
data_save = [province_code, province_name, city_code, city_name, county_code, county_name]
n = (i-1)*50 + (j-1)*500 + k
chain_ID.loc[n] = data_save
chain_ID.to_csv('2019年中国省市县地区代码.CSV', index=0, encoding='utf_8_sig')
下拉框点击动作必须由 selenium来执行,设置无界面模式。
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
def brower():
# 设置chrome浏览器
chrome_options = Options()
# 设置chrome浏览器无界面模式
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
# 打开网页
start_url = 'https://www.tiebazhushou.com/index/id.html'
# 'http://www.ip33.com/area_code.html'
browser.get(start_url)
return browser定位 select 框选项, 并获取当前选择的 省名/市名/区县名 及对应代码。
def get_text(browser, i, s_area, area_str):
s_area.select_by_index(i) # 选择第i项选项
area_value = get_value(browser, area_str)
area = []
for select in s_area.options:
area.append(select.text)
return area_value, area[i]
获取当前选择框的 value值。
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
def get_value(browser, region):
wait = WebDriverWait(browser, 3)
option = wait.until(EC.presence_of_element_located((By.ID, region)))
option_value = option.get_attribute('value')
return option_value爬取完毕,再次网上搜索代码表时, 却发现 2019年中国省市县地区代码 这个网址整整齐齐的罗列我想要的数据。