Adaptive Cross-Modal Few-shot Learning
论文
资料1
基于度量的元学习(metric-based meta-learning)如今已成为少样本学习研究过程中被广泛应用的一个范式。这篇文章提出利用交叉模态信息(cross-modal information)来进一步加强现有的度量元学习分类算法。
在本文中,交叉模态是指视觉和语言的信息;结构定义上来说视觉信息和语义信息有截然不同的特征空间,然而在识别任务上二者往往能够相互辅助,某些情况下视觉信息比起语义文字信息更加直观,也更加丰富,利于分类识别,而另一些情况下则恰恰相反,比如可获得的视觉信息受限,那么语义表达自然是能够提供强大的先验知识和背景补充来帮助学习提升。
参考少样本学习时可能会遇到的困难样本如下图:左边示例的每对图片在视觉信息上非常类似,然而他们实际上归属语义相差很大的不同类别,右边示例的每对图片视觉信息差异较大,然而所属的语义类别都是同一个。这两组例子很好证明了当视觉信息或语义信息之一缺失的情况下,少样本分类学习由于样本数目的匮乏,提供到的信息很可能是有噪声同时偏局部的,很难区分类似的困难样本。

image
根据如上的场景假设,文章提出一个自适应交叉混合的机制(Adaptive Modality Mixture Mechanism,AM3):针对将要被学习的图像类别,自适应地结合它存在于视觉和语义上的信息,从而大幅提升少样本场景下的分类任务性能。具体来说,自适应的 AM3 方法并没有直接将两个信息模块对齐起来然后提供辅助,也没有通过迁移学习转化语义信息作为视觉特征辅助(类似视觉问答 VQA 任务那样),而是提出更优的方式为,在少样本学习的测试阶段独立地处理两个知识模块,同时根据不同场景区分适应性地利用两个模块信息。
比如根据图像所属的种类,让 AM3 能够采用一种自适应的凸结合(adaptive convex combination)方式糅合两个表征空间并且调整模型关注侧重点,从而完成更精确的少样本分类任务。对于困难样本,在上图左边不同类别视觉相似度高的情况下,AM3 侧重语义信息(Semantic modality)从而获得泛化的背景知识来区分不同类别;而上图右边同类别图片视觉差距大的情况下,AM3 模型侧重于视觉信息(Visual modality)丰富的局部特征从而更好捕捉同类图片存在的共性。
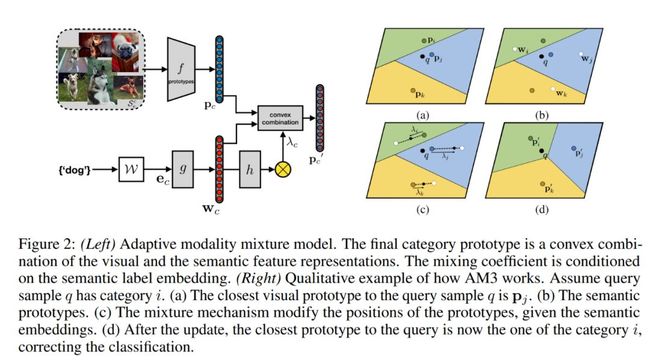
在对整个算法有初步印象之后,我们结合 AM3 模型示意图来观察更多细节:
image
首先少样本分类采用的学习方式仍然是 K-way N-shot 的节点学习(episodic training)过程,一方面是来自 N 个类别的 K 张训练图片 S 用作支撑集(Support Set),另一方面是来自同样 N 个类别的测试图片作为查询集 Q(Query Set),并根据分类问题损失定义得到如下参数化的方程为优化目标:

image
在基础模型网络方面,AM3 采用了一个比较简洁的 Prototypical Network 作为例子,但也可以延伸到其他网络使用:利用支撑集为每个类别计算一个类似于聚类一样的中心聚点(centroids),之后对应的查询集样本只需与每个中心点计算距离就可以得到所属类别。对于每一个节点 e(episode)都可以根据平均每个类别所属支撑样本的嵌入特征得到嵌入原型 Pc(embedding prototype)以及分布的函数 p:

image
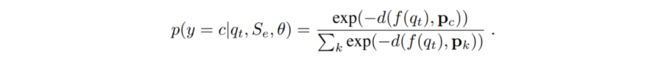
image
在 AM3 模型里,为了如之前说到的更灵活地捕捉语义空间的信息,文章在 Prototypical Network 的基础上进一步增加了一个预训练过的词嵌入模型 W(word embedding),包含了所有类别的标签词向量,同时修改了原 Prototypical Network 的类别表征,改为同时考虑视觉表达与语义标签表达的结合。而新模型 AM3 的嵌入原型 P』c 同学习函数,用类似正则项的更新方式得到为:
其中, 转存失败重新上传取消是自适应系数,定义为下式,其中 h 作为自适应混合函数(adaptive mixing network),令两个模态混合起来如 Fig 2(a) 所示
转存失败重新上传取消是自适应系数,定义为下式,其中 h 作为自适应混合函数(adaptive mixing network),令两个模态混合起来如 Fig 2(a) 所示
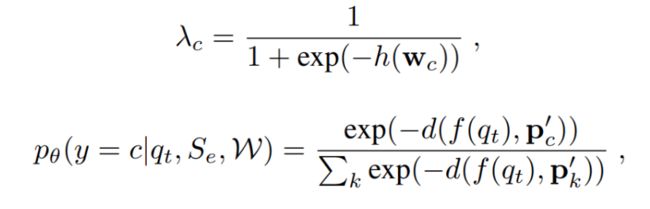
image
上式 p(y=c|q,S,Ɵ)是作为该节点在 N 个类别上由模型学习到的分布,整体来说是根据查询样本 q 的嵌入表达到嵌入原型直接的距离 d,最终做了一个 softmax 操作得到的。距离 d 在文章中简单地采用了欧氏距离,模型通过梯度下降算法(SGD)最小化学习目标损失 L(Ɵ)的同时,也不停地更新迭代相关参数集合。
基于并不复杂的模型,文章在少样本数据集 miniImageNet,tieredImageNet 以及零样本学习数据集上都验证了自己的方法,均取得了非常好的成绩

image

image
总的来看 AM3 这个工作也提出了一个非常有意思的少样本学习切入点,即多个空间的信息互相补足与制约,AM3 网络优越性体现在结构的简洁和理论的完整性,目前该工作的代码也已经开源,感兴趣的读者可以进一步探索:除了 Prototypical Network 以外,更复杂的网络以及包含更多的模态信息。
Paper: https://papers.nips.cc/paper/8731-adaptive-cross-modal-few-shot-learning.pdf
Code: https://github.com/ElementAI/am3
资料2
1、introduction
这篇文章提出了一种将语义与视觉知识相结合的自适应的cross-modal。视觉和语义特征空间根据定义具有不同的结构。对于某些概念,视觉特征可能比文本特征更丰富,更具辨别力。但当视觉信息在图像分类中受到限制时,语义表示(从无监督的文本语料库中学习)可以提供强大的先验知识和上下文以帮助学习。此文就是基于此开展研究的,提出了Adaptive Modality Mixture Mechanism(AM3),an approach that adaptively and selectively combines information from two modalities, visual and semantic, for few-shot learning。AM3在基于度量的元学习方法上形成的,通过比较在已学习的度量空间中的距离来实现分类。文章在原型网络Prototypical Networks for Few-shot Learning的思想基础上,加入了文本信息(即语义表达)。
2、algorithm
在AM3中,文章增加了基于度量的FSL方法,以结合由词嵌入模型W学习的语言结构(pre-trained on unsupervised large text corpora),在所有类别中包含了label embeddings。由于考虑到了label embeddings,AM3对每个类修改了原型表达(prototype representation)。有上图(左)就可以看出AM3将视觉和语义特征表达的凸组合形成最终的类原型(category prototype),参数化表示为:
其中:
对于每一个episode(片段)e,类c的嵌入原型(即support set的均值,这里与原型网络设计一致)。
few-shot learning分类的训练是通过在给定的support set来最小化在query set中样本的预测损失。
训练时和原始的原型网络相似,但是这里距离度量改变了,AM3加入了语义信息,此时d为query point与cross-modal 原型的距离。上图(右)现实了AM3的work过程;假设query 样本q是属于类别i的,但是在视觉信息上与q最相近的是(a),(b)显示了每个类的语义原型;在加入了语义嵌入时,AM3修改了原型的位置(c);通过更新,离q最近的原型为类i。
算法流程为:
3、experiments
文章分别在miniImageNet、tieredImageNet(few-shot learning)和CUB-200(zero-shot learning)上进行实验,结果表明AM3性能表现最好,模型简单且易扩展。实验中发现在ZSL领域中的方法扩展到基于度量的方法(FSL)性能都提升了。其余详细的内容见原文。
总结:
看完整片文章,AM3的亮点就是在原型网络的基础上将语义信息与视觉信息相结合,形成一种自适应的模型,即当样本较少时,此时较小,文本信息占主要地位,当较大时,视觉信息占主要地位。
————————————————
版权声明:本文为CSDN博主「warm_in_spring」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/warm_in_spring/article/details/98520385