用于单眼深度估计的深度序数回归网络(论文 2018)
Deep Ordinal Regression Network for Monocular Depth Estimation
原文下载:http://openaccess.thecvf.com/content_cvpr_2018/papers/Fu_Deep_Ordinal_Regression_CVPR_2018_paper.pdf
寻找大佬交流,
1
1
1
1
作者:Huan Fu、 Mingming Gong 、Chaohui Wang 、Kayhan Batmanghelich 、Dacheng Tao
摘要:
单目景深估计是一个不适定问题,在理解三维场景几何中起着至关重要的作用。近年来,通过从深卷积神经网络(DCNNs)中挖掘图像层次信息和层次特征的方法得到了显著的改进。这些方法将深度估计建模为一个回归问题,并通过最小化均方误差来训练回归网络,该网络收敛速度慢,局部解不理想。此外,现有的深度估计网络采用重复的空间汇集操作,导致不期望的低分辨率特征映射。为了获得高分辨率的深度图,需要使用跳跃连接或多层反褶积网络,这使得网络训练复杂化,计算量大为增加。为了消除或至少在很大程度上减少这些问题,我们引入了间隔递增离散化(SID)策略,将深度离散化并将深度网络学习作为一个有序回归问题进行重构。通过使用普通的回归损失对网络进行训练,我们的方法获得了更高的精度和更快的同步收敛速度。此外,我们采用多尺度网络结构,避免了不必要的空间池,并并行捕获多尺度信息。所提出的深度有序回归网络(DORN)在三个具有挑战性的基准上实现了最新的结果,即KITTI [16] 、MAK3D [49]和NYU Depth V2 [41],并且大大优于现有的方法。

一、介绍
从2D图像中估计深度是场景重建和理解任务(如3D目标识别、分割和检测)的关键步骤。本文研究了单目深度估计问题(以下简称MDE)。
与已有重大进展的立体图像或视频序列的深度估计[19、29、26、44]相比,该方法进展缓慢。MDE是一个不适定问题:单个2D图像可以由无限多个不同的3D场景生成。为了克服这种内在的模糊性,典型的方法是利用统计上有意义的单眼线索或特征,例如透视和纹理信息、对象大小、对象位置和遮挡[49、24、32、48、26]。
最近,一些作品通过使用基于DCNN的模型[38、55、46、9、28、31、33、3]显著提高了MDE的性能,这表明深度功能优于手工制作的功能。这些方法通过学习DCNN来估计连续深度图来解决MDE问题。由于该问题是标准回归问题,通常采用对数空间中的均方误差(MSE)或其变量作为损失函数。虽然优化回归网络可以实现合理的解决方案,但我们发现收敛速度相当缓慢,最终解决方案还远远不能令人满意。
此外,现有的深度估计网络 [9,15,31,33,38,57] 通常采用标准DCNNs,最初以完全卷积的方式作为特征提取器进行图像分类。在这些网络中,重复的空间池快速降低了特征图的空间分辨率(通常为32步),这对于深度估计是不可取的,尽管可以通过多层反褶积网络 [33,15,31] 、多尺度网络[38,9] 或跳跃连接[57]合并高分辨率特征图来获得高分辨率深度图,但这样的处理不仅需要额外的计算和存储成本,同时也使网络结构和训练过程复杂化。
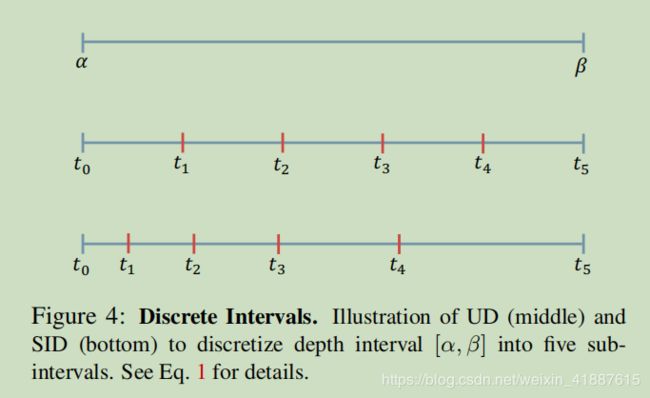
与MDE的现有发展相比,我们提出将连续深度离散为多个区间,并将深度网络学习作为有序回归问题,并提出如何通过DCNNs将有序回归包含到密集预测任务中。更具体的说,我们提出使用间隔增加离散化(SID)策略而不是均匀离散化(UD)策略来执行离散化,其动机是深度预测的不确定性随着潜在的地面真实深度而增加,这表明,在预测较大深度值时,最好允许相对较大的误差,以避免大深度值对训练过程的过度强化影响。在得到离散深度值后,我们通过考虑离散深度值排序的有序回归损失来训练网络。
为了简化网络训练和节省计算成本,我们还提出了一种避免不必要的子采样的网络结构,并以简单的方式捕获多尺度信息,而不是跳过连接。受场景分析的最新进展 [60,4,62] 的启发,我们首先去除最后几个池化层中的子采样,并应用扩展卷积来获得大的接收场。然后,利用具有多个扩张率的扩张卷积从最后一个池化层中提取多尺度信息。最后,我们开发了一个完整的图像编码器,它以显著低于完全连接的完整图像编码器的内存成本高效地捕获图像级信息[2,10,8,35,28] 。整个网络以端到端的方式进行训练,无需阶段性训练或者迭代求法。在KITTI [16]、Make3D [49,48]和NYU Depth V2 [41]这三个具有挑战性的基准上的实验表明,该方法达到了最新的结果,并且在很大程度上优于最近的算法。
本文的其余部分安排如下。在第2节简要回顾相关文献后。第3节我们讲述详细介绍了所提出的方法。第4节除了在这些基准上的定性和定量表现外,我们还评估了所提出方法的多个基本实例,以分析这些核心因素的影响。最后,第5节我们对全文进行了总结。
二、相关工作
深度估计对于从二维图像中理解场景的三维结构至关重要。早期的工作集中在通过开发基于几何的算法(50、12、11)从立体图像中估计深度,这些算法依赖于图像和三角剖分之间的点对应来估计深度。在一部开创性的著作[48]中,Saxena等人通过有监督学习从二维图像的单眼线索中学习深度。从那时起,人们提出了各种方法来利用使用手工制作的表示的单眼线索[49、24、32、36、7、30、1、53、45、14、20、59]。由于手工制作的特征只能捕捉局部信息,因此通常基于这些特征构建马尔可夫随机场(MRFs)等概率图形模型,以合并远程和全局线索[49、63、39]。利用全局线索的另一个成功方法是深度传递方法[26],该方法使用GIST全局场景特征[43]从包含RGBD图像的数据库中搜索与输入图像“相似”的候选图像。
鉴于DCNNs在图像理解方面的成功,近年来提出了许多深度估计网络[18,61,35,40,52,56,46,38,27]。由于来自强大的非常深的网络(例如VGG[54]和ResNet[22])的多层次上下文和结构信息,深度估计被提升到了一个新的精度水平[9、15、31、33、57]。主要的障碍是这些深层特征抽取器中的重复池操作会快速降低特征地图的空间分辨率(通常是32步)。Eigen等人[10,9]应用了多尺度网络,该网络通过独立网络将估计深度图从低空间分辨率逐步明智地细化到高空间分辨率。谢等[57]采用跳跃连接策略,将深层低空间分辨率深度图与深层高空间分辨率深度图融合。最近的工作[15,31,33]应用多层反褶积网络来恢复粗到细的深度。一些方法不仅依赖于深度网络,还结合了条件随机场,以进一步提高估计深度图的质量[55,38]。为了提高训练效率,Roy和Todorovic[46]提出了神经回归森林方法,该方法允许对“浅层”CNNs进行并行训练。
最近,无监督或半监督学习被引入到深度估计网络的学习中[15,31]。这些方法通过重建损失来估计视差图。此外,还提出了一些考虑对位信息的弱监督方法,以粗略估计和比较深度[64,6]。
序数回归[23,21]旨在学习从序数尺度预测标签的规则。大多数文献对已有的分类算法进行了改进,以解决序贯回归算法。例如,Shashua和Levin[51]通过开发一种新的支持向量机来处理多个阈值。Cammer和Singer[8]将多阈值在线感知器算法推广到序贯回归中。另一种方法是将序贯回归表示为一组二元分类子问题。例如,Frank和Hall[13]应用了一些决策树作为序数回归的二元分类器。在计算机视觉中,序数回归与DCNNs相结合来解决年龄估计问题[42]。
三、方法
本节首先介绍了我们的深度序贯回归网络的体系结构,然后介绍了将连续深度值划分为离散值的SID策略,最后详细介绍了如何在序贯回归框架中学习网络参数。
3.1 网络体系结构
如图2所示,分割网络由两部分组成,即密集特征提取模块和场景理解模块,并输出给定图像的多通道密集有序标签。
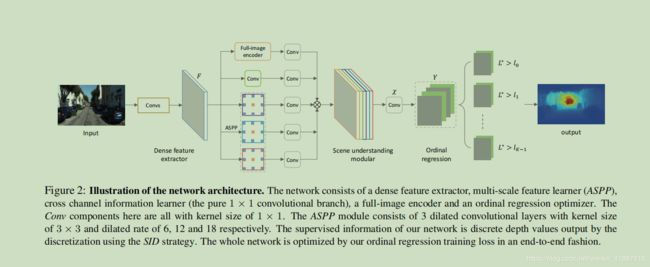
3.1.1 密集特征提取器
以前的深度估计网络[9,15,31,33,38,57]通常使用最初设计用于图像识别的标准DCNNs作为特征提取器。然而,最大池和跨距的重复组合显著降低了特征地图的空间分辨率。此外,为了整合多尺度信息并重建高分辨率深度图,可以采用一些局部补救措施,包括阶段细化[10,9]、跳跃连接[57]和多层反褶积网络[15,31,33],但这不仅需要额外的计算和存储成本,同时也使网络结构和训练过程复杂化。在最近的一些场景分析网络[60,4,62]之后,我们主张去除DCNNs的最后几个下采样算子,并在随后的卷积(conv)层中插入孔,称为扩展卷积,以在不降低空间分辨率或增加参数数目的情况下扩大滤波器的视场。
3.1.2场景理解模块
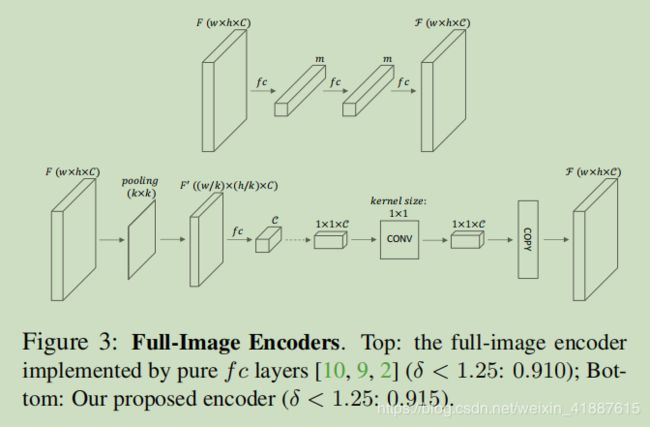
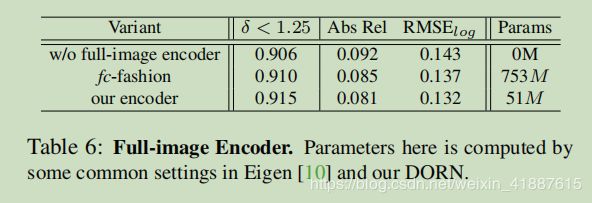
场景理解模块由三个并行组件组成,即atrus空间金字塔池(ASPP)模块[5]、跨通道leaner和全图像编码器。ASPP 用于通过扩张卷积操作从多个大型接收场中提取特征。扩张率分别为6、12和18。纯1x1卷积分支可以学习复杂的跨通道相互作用。全图像编码器捕获全局上下文信息,并能在深度估计中极大地澄清局部混淆[55、10、9、2]。
虽然之前的方法已经包含了全图像编码器,但我们的全图像编码器包含的参数较少。如图3所示,为了从具有维度C x h x w的F中获得具有维度C x h x w的全局特征F,一种常见的fc-fashion方法通过使用完全连接的层来实现这一点,其中F中的每个元素连接到所有图像特征,这意味着对整个图像的全局理解。然而,这种方法包含的参数太多,训练难度大,内存消耗大。相比之下,我们先利用核大小和步长较小的平均池层来降低空间维数,然后利用fc层得到维数为C的特征向量,然后将该特征向量作为空间维数为1x1的特征映射的C通道,再加入核大小为1x1的conv层。作为跨通道参数池结构。最后,我们将特征向量沿空间维度复制到F上,使得F的每个位置对整个图像都有相同的理解。
将从上述组件获得的特征串联起来,以实现对输入图像的全面理解。此外,我们还增加了两个核大小为1x1的卷积层,前者降低特征维数,学习复杂的跨通道交互,而后者将特征转换为多通道密集序数标签。
3.2.间距递增离散化





四、实验
为了证明深度估计的有效性,我们提出了一些实验来验证我们的方法的各个方面。在介绍了实现细节之后,我们在三个具有挑战性的室外数据集上评估我们的方法,即KITTI[16],Make3D[48,49]和NYU Depth v2[41]。评估指标遵循先前的工作[10,38],讨论了一些基于KITTI的融合研究,对 我们的方法进行了更详细的分析。
实现详细:我们实现了基于公共深度学习平台Caffe[25]的深度估计网络。学习策略采用多项式衰减,基于学习率为0.0001,幂为0.9。动量和重量衰减分别设置为0.9和0.0005。KITTI的迭代次数设置为300K,Make3D的迭代次数设置为50K,NYU Depth V2的迭代次数设置为3M,批次大小设置为3。我们发现进一步增加迭代次数只能稍微提高性能。我们采用VGG-15[54]和ResNet-101[22]作为我们特征提取器,通过ILSVRC上的预训练分类模型初始化他们的参数。由于前几层的特征只是包含了一般的底层信息,因此我们在初始化后修改了ResNet中的conv1和conv2块的参数。此外,在训练过程中,ResNet中的批规范化参数直接初始化和固定数据扩充策略如[10]。在测试阶段,我们根据训练阶段的裁剪方法将每个图像分割成一些重叠的窗口,并通过平均预测来获得重叠区域中的预测深度值。
4.1.基准性能
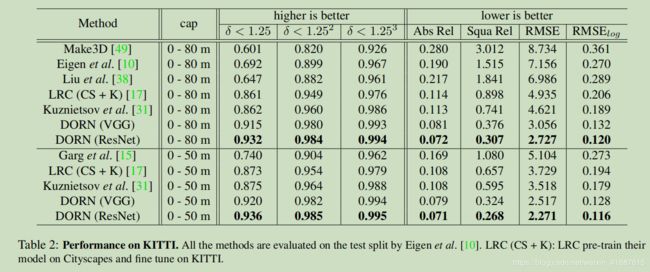
KITTI:KITTI数据集包含了室外场景,分辨率约为3751241,由驾驶汽车的摄像头和深度传感器拍摄的“城市”、“住宅”、“道路”和“校园”的61个场景都被用作我们的训练/测试集。我们对由Eigen等人[10]分割的20个场景中的23488幅图像进行了训练。我们在随机裁剪385513训练我们的模型。对于一些其他细节,我们设置最大序号KITTI为80,并评估我们的结果在一个预定义的中心种植以下[10 ]的深度范围从0M至 80m和0m至50m。请注意,单个模型在全深度范围内进行训练,并在具有不同深度范围的数据上进行测试。
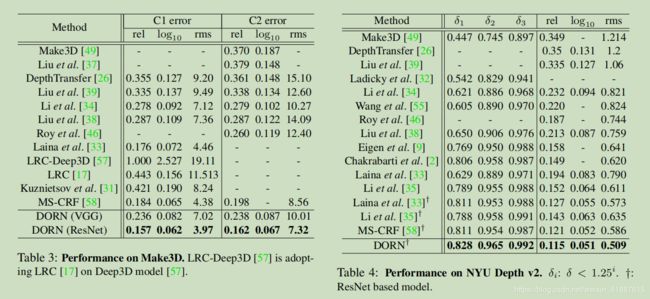
Make3D: Make3D数据集[48,49]包含534幅室外图像,400幅用于训练,134幅用于测试,分辨率为22721704,并提供了55305的地面真实深度图,我们将所有的图像的分辨率降到568426,并在513385大小的随机裁剪上训练我们的模型。在前面的工作之后,我们使用三个常用的评估指标[26,38]在此数据上报告C1(深度范围从0到80米)和C2(深度范围从0到70米)错误。对于VGG模型,我们从零开始在0米到80米的深度范围内训练我们的DORN(ImageNet model),并对C1个C2使用相同的模型评估结果。然而,对于ResNet,我们分别学习C1和C2的两个独立模型。
NYU Depth V2: NYU Depth V2[41]数据集包含464个用微软 Kinect摄像机拍摄的室内视频场景。我们使用249个训练场景中的所有图像(约120K)训练我们的DORN,并在之前的工作之后的694个图像测试集上进行测试。为了加快训练速度,所有的图像分辨率都从480640降低到288384。该模型是在257*353大小的随机裁剪上训练的。我们通过Eigen[10]在预先定义的中心裁剪上报告得分。
性能:表2和表3给出了KITTI和Make3D两个室外数据集的结果,可以看出我们的DORN在所有设置下的精度比以前的工作提高了5% ~ 30%。一些定性结果如图5和图6所示。在表4中,我们的DORN优于在NYU Depth V2上的其他方法,NYU Depth V2是最大的室内基准之一。结果表明,该方法使用与室内外数据。我们还评估了我们的方法在网上KITTI评估服务器、如表1所示,我们的DORN明显优于官方提供的基准线约30% ~ 70%


4.2 消融研究
我们进行了各种消融研究来分析我们的方法的细节。结果显示在表5、表6、图1和图7,并进行了详细讨论。
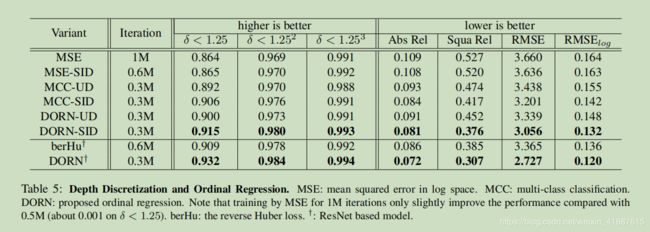

4.2.1深度离散化
深度离散化对于行能改进有着至关重要的作用,因为它允许我们应用分类和序数回归损失来优化网络参数。根据表5的分数,在连续深度上进行回归训练似乎比其他两种方法收敛到更差的解,并且我我们的序数回归网络取得了最好的性能。深度分别由SID和UD离散的方法之间存在明显的差距。此外,当用优势回归损失(即BerHu)代替序数回归损失时,我们的DORN仍然获得更高的分数。因此,我能可以得出结论:(i)与UD相比,SID显的更为重要,并且可以进一步提高性能;(ii)离散化深度和使用多分类损失的训练优于使用回归损失的训练;(iii)探索深度驱动深度估计网络之间的顺序相关性以收敛到更好的解。
此外,我们还使用RMSElog对由SID获得的离散深度值进行网络训练,并在表5显示结果。我们可以看到MSE-SID的性能略优于MSE,这说明量化误差在深度估计中几乎是可以忽略的。通过使用序数回归损失进行离散化的好处远远超过深度离散化的成本。

五、总结
本文提出了一种深度序数回归网络(DORN)用于单目深度估计,该网络由一个干净的CNN结果和一些有效的网络优化策略组成。该方法的动机有:(i)为了获得高分辨率的深度图,以往的深度估计网络需要在复杂的结构中融合多尺度特征和全图像特征,这使得网络训练复杂化,计算量大幅增加;(ii)训练用于深度估计的回归网络存在收敛速度慢和局部解不令人满意的问题。为此,我们首先介绍了一种简单的深度估计网络,它利用扩展卷积技术和一种新的全图像编码器直接获得高分辨率的深度图。同时,将有效的深度离散策略和序数回归训练损失相结合,提高了网络的训练质量,从而大大提高了估计精度。该方法实现了KITTI、Make3D和NYU Depth V2数据集的实时性能。在未来,我们将研究的深度近似,并将我们的框架扩展到其他稠密预测问题。