ML/DL补充

目录
ML相关:偏差方差、先验后验、生成判别、流程、信息论、SVM、决策树
DL相关:激活函数、正则化、范数、optimizer、CNN、RNN、TCN、seq2seq
about:mobilenet、CRNN、无人驾驶、cuda
scatter:散件
ML相关
偏差Bias和方差Variance
偏差与方差分别是用于衡量一个模型泛化误差的两个方面,在监督学习中,模型的
泛化误差可分解为偏差、方差与噪声(Bias方)之和。
模型的偏差,指的是模型预测的期望值与真实值之间的差,用于描述模型的拟合能力
模型的方差,指的是模型预测的期望值与预测值之间的差平方和,用于描述模型的稳定性
导致原因:
偏差:错误假设、模型复杂度不够,欠拟合
方差:模型的复杂度相对于训练集过高,过拟合
神经网络的拟合能力非常强,因此它的训练误差(偏差)通常较小,但容易过拟合.较大方差,所以一般用正则化防止过拟合
先验概率和后验概率
条件概率(似然概率):P(x|y),表示y发生的条件下x发生的概率
先验概率:P(A)、P(B),事件发生前的预判概率,一般是单独事件
后验概率:基于先验概率求得的反向条件概率,形式上与条件概率相同(若 P(X|Y) 为正向,则 P(Y|X) 为反向)
贝叶斯公式:P(Y|X)=P(X|Y)P(Y)/P(X)
生成模型和判别模型
监督学习的任务是学习一个模型,对给定的输入预测相应的输出
这个模型的一般形式为一个决策函数或一个条件概率分布(后验概率):Y=f(X) or P(Y|X)
决策函数:输入 X 返回 Y;其中 Y 与一个阈值比较,然后根据比较结果判定 X 的类别
条件概率分布:输入 X 返回 X 属于每个类别的概率;将其中概率最大的作为 X 所属的类别
监督学习模型可分为生成模型与判别模型
生成模型学习的是联合概率分布P(X,Y),然后根据条件概率公式计算 P(Y|X),P(Y|X)=P(X,Y)/P(X)
判别模型直接学习决策函数或者条件概率分布,判别模型学习的是类别之间的最优分隔面,反映的是不同类数据之间的差异
由生成模型可以得到判别模型,但由判别模型得不到生成模型,当存在“隐变量”时,只能使用生成模型
优缺点
生成:学习收敛速度快,但学习计算过程复杂
判别:直接面对预测,学习准确率高,抽象使用特征.简化学习过程,但不能反应数据本身的特性
常见
生成:朴素贝叶斯NBM、隐马尔可夫模型HMM、混合高斯模型GMM、贝叶斯网络、马尔可夫随机场MRF
判别:knn、感知机(神经网络)、决策树、逻辑斯蒂回归、最大熵模型、SVM、提升方法boosting、条件随机场CRF
模型度量指标
True Positive(TP):将正类预测为正类的数量.
True Negative(TN):将负类预测为负类的数量.
False Positive(FP):将负类预测为正类数
False Negative(FN):将正类预测为负类数
准确率(accuracy):预测正确/总
精确率(precision):正类预测正确/预测正类总
召回率(recall):正类预测正确/本来正类总
F1值(精确率和召回率的调和均值):各分之一和分之2
处理缺失值
可以去掉或填充
当缺失值多时,直接舍弃该特征,否则会带来较大噪声
当缺失值少时,可以用0或均值、相邻数据等方式填充
一个完整的机器学习项目流程
数学抽象-数据获取-预处理和特征选择-模型训练与调优-模型诊断-模型融合.集成-上线运行
数学抽象:得先明确问题,ML训练是耗时的事情,所以需要明确任务目标,是分类、回归还是聚类…
数据获取:数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。
数据需要有代表性,对于分类问题,数据偏斜不能过于严重(平衡),不同类别的数据数量不要有数个数量级的差距。
预处理与特征选择:良好的数据要能够提取出良好的特征才能真正发挥效力。
预处理/数据清洗是很关键的步骤,归一化、降维、缺失值处理等,数据挖掘过程中很多时间就花在它们上面。
需要反复理解业务,筛选出显著特征、摒弃非显著特征,这对很多结果有决定性的影响。
特征选择好了,算法实现事半功倍,简单的算法也能得到好的效果。
这需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。

模型训练与调优:调参.超参数,这需要我们对算法的原理有深入的理解,理解优缺点、和业务关联调优。
模型诊断:交叉验证,绘制学习曲线等,检测过拟合欠拟合的问题,还有误差分析
过拟合就增加数据量、降低模型复杂度,欠拟合就提高特征数量和质量、增加模型复杂度。
通过观察误差样本,全面分析误差产生误差的原因:是参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题…
诊断后的模型需要进行调优,调优后的新模型需要重新进行诊断,这是一个反复迭代不断逼近的过程,需要不断地尝试,进而达到最优状态。
模型融合.集成:一般来说,模型融合后都能使得效果有一定提升,而且效果很好。
上线运行:产品化,以结果导向的工程,模型在线上运行的效果直接决定模型的成败。
不单纯包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性是否可接受。
信息论
信息论的基本想法是:一件不太可能的事发生,要比一件非常可能的事发生,提供更多的信息。
非常可能发生的事件信息量要比较少,并且极端情况下,一定能够发生的事件应该没有信息量。
独立事件应具有增量的信息。例如,投掷的硬币两次正面朝上传递的信息量,应该是投掷一次硬币正面朝上的信息量的两倍。
一条信息的信息量和他的不确定性有直接的关系,我们要清楚一个非常不确定的事就需要了解大量信息,如果我们对一个事已经了解很多,那就不需要太多的信息就能把他搞懂——信息量就等于不确定性的多少
信息熵H(X)=E(I(x))=sum(P(x)logP(x))
交叉熵Hp(Q)=ElogQ(x)=sum(P(x)logQ(x))
SVM
支持向量机是一种二分类模型,求其在特征空间上间隔最大的线性分类器,使用核方法也可以变成了非线性分类器
SVM 的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题
SVM 的最优化算法是求解凸二次规划的最优化算法。
训练数据集中与分离超平面距离最近的样本点的实例称为支持向量
当训练数据线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机,又称硬间隔支持向量机。
当训练数据接近线性可分时,通过软间隔最大化,学习一个线性分类器,即线性支持向量机,又称软间隔支持向量机。
当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
核函数表示将输入从输入空间映射到特征空间后得到的特征向量之间的内积
线性 SVM 的推导分为两部分
如何根据间隔最大化的目标导出 SVM 的标准问题,拉格朗日乘子法对偶问题的求解过程
最大化几何间隔得到问题:min ||w||^2/2 s.t. yi(wTxi+b)>=1 i=1,n
凸二次优化问题,然后通过拉格朗日函数和对偶性一步步求解二次规划问题
集成学习
分为bagging(并行)和boosting(串行)
一般都使用决策树作为基学习器,因为决策树是不稳定(数据的变动会对结果造成较大影响)学习器
基学习器为不稳定的好处就是他容易受到样本分布的影响(方差大),具有随机性,这有助于集成学习中提升模型的泛化能力
为了更好的引入随机性,有时会随机选择一个属性子集中的最优分裂属性,而不是全局最优(随机森林RF)
决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。(通过信息熵.信息增益来选择拆分)
CART 决策树
CART 算法是在给定输入随机变量 X 条件下输出随机变量 Y 的条件概率分布的学习方法。
CART 算法假设决策树是二叉树,内部节点特征的取值为“是”和“否”。
这样的决策树等价于递归地二分每个特征,将输入空间/特征空间划分为有限个单元,然后在这些单元上确定在输入给定的条件下输出的条件概率分布。
CART 决策树既可以用于分类,也可以用于回归;
对回归树 CART 算法用平方误差最小化准则来选择特征,对分类树用基尼指数最小化准则选择特征
GBDT 梯度提升决策树
梯度提升是梯度下降的近似方法,其关键是利用损失函数的负梯度作为残差的近似值,来拟合下一个决策树。
DL相关
过拟合与欠拟合
欠拟合指模型不能在训练集上获得足够低的训练误差;
过拟合指模型的训练误差与测试误差(泛化误差)之间差距过大;
反映在评价指标上,就是模型在训练集上表现良好,但是在测试集和新数据上表现一般(泛化能力差)
降低过拟合方法
数据扩充(图像变换.Gan生成.MT生成等)
降低模型复杂度(神经网络减少层数.神经元个数.决策树剪枝等)
权值约束(L1L2等)
集成学习(dropout、RF、GBDT等)
提前终止
降低欠拟合方法
加入新特征(因子分解机FM、Deep-Crossing、自编码器)
增加模型复杂度(神经网络增加层数.神经元个数)
减少或去掉正则化(添加正则化项是为了限制模型的学习能力,减小正则化项的系数则可以放宽这个限制;模型通常更倾向于更大的权重,更大的权重可以使模型更好的拟合数据)
反向传播
梯度下降法中需要利用损失函数对所有参数的梯度来寻找局部最小值点;
而反向传播算法就是用于计算该梯度的具体方法,其本质是利用链式法则对每个参数求偏导。
z=wx+b,a=sigm(z) ,最后算出dz=A-Y ,z为上一层激活值
激活函数
为什么逻辑回归要套一层比如sigm的非线性激活函数,用线性回归不好么?
使用激活函数的目的是为了向网络中加入非线性因素
加强网络的表示能力,解决线性模型无法解决的问题
神经网络的万能近似定理认为主要神经网络具有至少一个非线性隐藏层,那么只要给予网络足够数量的隐藏单元,它就可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的函数
使得神经网络具有的拟合非线性函数的能力,使得其具有强大的表达能力(只用线性约束分类空间太蠢了,即便加多少层还是线性组合,就永远画不成一个圆)
不过部分层纯线性是可以接受的,这可以减少网络中的参数
激活函数:
整流线性单元ReLU、渗漏整流线性单元Leaky ReLU(x为负梯度为0.01)、maxout 单元(ReLU扩展,可学习的k段函数)、sigmoid、tanh
线性:softmax(多分类输出层,概率分布z/sum(z))、径向基函数RBF(很老.也存在问题:不易优化,基本不用,式子也难写)、softplus(ReLU平滑版本log(1+exp(z)))、硬双曲正切函数(hard tanh,max(-1,min(1,a)))
其中
sigm函数在x过大过小容易发生梯度消失,所以基本不在训练层用
ReLU在负半区输出为0,造成了网络的稀疏性.稀疏激活,可以缓解过拟合问题
ReLU的求导不涉及浮点运算,所以模型计算速度更快
虽然从数学的角度看ReLU在0点不可导,因为它的左导数和右导数不相等,但在实现时通常会返回左导数或右导数的其中一个,而不是报告一个导数不存在的错误,从而避免了这个问题
正则化
批标准化Batch Normalization
训练的本质是学习数据分布。如果训练数据与测试数据的分布不同会降低模型的泛化能力。因此,应该在开始训练前对所有输入数据做归一化处理。
而在神经网络中,因为每个隐层的参数不同,会使下一层的输入发生变化,从而导致每一批数据的分布也发生改变;致使网络在每次迭代中都需要拟合不同的数据分布,增大了网络的训练难度与过拟合的风险。
BN方法会针对每一批数据,在网络的每一层输入之前增加归一化处理,使输入的均值为0,标准差为1,目的是将数据限制在统一的分布下,然后作为该神经元的激活值
BN可以看作在各层之间加入了一个新的计算层,对数据分布进行额外的约束,从而增强模型的泛化能力,也同时降低了模型的拟合能力.破坏了之前的特征分布(防止过拟合)
L1L2
他们都可以限制模型的学习能力——通过限制参数的规模,使模型偏好于权值较小的目标函数,防止过拟合。
他们会使模型偏好于更小的权值,限制了参数的分布,从而降低了模型的复杂度。
L1 正则化可以产生稀疏权值,而 L2 不会
因为L1范数约束会得到稀疏解,但L2俗称岭回归,是权重衰减,并没有稀疏的作用
L1

L2

范数
L0:非零元素的个数
L1:sum(|x|)
L2:所有元素平方和开方
Lp:所有元素p方和开p方
L无穷:最大元素的绝对值,也称最大范数
Frobenius 范数:矩阵化的 L2 范数
范数的作用:正则化——权重衰减/参数范数惩罚
权重衰减的目的:限制模型的学习能力,通过限制参数θ的规模(主要是权重w的规模,偏置b不参与惩罚),使模型偏好于权值较小的目标函数,防止过拟合。
dropout
Dropout策略相当于集成了包括所有从基础网络除去部分单元后形成的子网络。
一般来说隐藏层的采样为0.5,输入采样0.8
在集成学习Bagging下,所有模型都是独立的;而在Dropout下,所有模型共享参数,其中每个模型继承父神经网络参数的不同子集

指数加权平均(指数衰减平均)
Vt=βVt-1+(1-β)θt
递归式子里越久前的记录其权重呈指数衰减,因此指数加权平均也称指数衰减平均
指数加权平均在前期会存在较大的误差,当t较小时,与希望的加权平均结果差距较大
可以引入一个偏差修正,Vt/1-β^t
偏差修正只对前期的有修正效果,后期当t逐渐增大时1-β^t -> 1,将不再影响 Vt,与期望相符
优化算法
梯度下降:通过迭代的方式寻找模型的最优参数
当目标函数是凸函数时,梯度下降的解是全局最优解;但在一般情况下,梯度下降无法保证全局最优。
随机梯度下降(SGD):每次使用单个样本的损失来近似平均损失
放弃了梯度的准确性,仅采用一部分样本来估计当前的梯度;因此 SGD 对梯度的估计常常出现偏差,造成目标函数收敛不稳定,甚至不收敛的情况

小批量随机梯度下降(MSGD):可以降低随机梯度的方差,使模型迭代更加稳定
还有一个目的就是可以进行矩阵化运算和并行计算
较大的批能得到更精确的梯度估计,较小的批能带来更好的泛化误差
无论是经典的梯度下降还是随机梯度下降,都可能陷入局部极值点;除此之外,SGD 还可能遇到“峡谷”和“鞍点”两种情况
峡谷类似一个带有坡度的狭长小道,左右两侧是“峭壁”;在峡谷中,准确的梯度方向应该沿着坡的方向向下,但粗糙的梯度估计使其稍有偏离就撞向两侧的峭壁,然后在两个峭壁间来回震荡。
鞍点的形状类似一个马鞍,一个方向两头翘,一个方向两头垂,而中间区域近似平地;一旦优化的过程中不慎落入鞍点,优化很可能就会停滞下来。
动量(Momentum)算法:带动量的 SGD
引入动量(Momentum)方法一方面是为了解决“峡谷”和“鞍点”问题;一方面也可以用于SGD 加速,特别是针对高曲率、小幅但是方向一致的梯度。
动量方法以一种廉价的方式模拟了二阶梯度(牛顿法)

NAG 算法(Nesterov 动量)
NAG 把梯度计算放在对参数施加当前速度之后

自适应学习率的优化算法:
AdaGrad:独立地适应模型的每个参数:具有较大偏导的参数相应有一个较大的学习率,而具有小偏导的参数则对应一个较小的学习率(每个参数的学习率会缩放各参数反比于其历史梯度平方值总和的平方根)

RMSProp:是为了解决 AdaGrad 方法中学习率过度衰减的问题,使用指数衰减平均(递归定义)以丢弃遥远的历史,还加入了一个超参数β来控制衰减速率

AdaDelta:和RMSProp差不多,只是他已经不需要设置全局学习率了
Adam:除了加入历史梯度平方的指数衰减平均(r)外,还保留了历史梯度的指数衰减平均(s),相当于动量。

AdaMax:Adam 的一个变种,对梯度平方的处理由指数衰减平均改为指数衰减求最大值
Nadam:Nesterov 动量版本的 Adam

优化算法在损失面上的表现

优化算法在鞍点的表现

CNN
特点:稀疏连接、参数共享、平移等变性(怎么平移都会检测出相同的特征)
好处:通过相对小的卷积核检测特征,用卷积核来代替BP全连接,减少参数数量、加速计算、减少内存需求、提高效率

卷积的正向传播实际就是矩阵相乘,所以反向传播和一般的全连接网络是类似的
转置卷积又称反卷积,是为了重建先前的空间分辨率的卷积,但其内部实际上执行的是常规的卷积操作
虽然转置卷积并不能还原数值,但是用于编码器-解码器结构中,效果仍然很好
这样,转置卷积可以同时实现图像的粗粒化和卷积操作,而不是通过两个单独过程来完成
空洞卷积又称扩张卷积.膨胀卷积,他能够捕捉更远的信息,获得更大的感受野,同时不增加参数的数量,也不影响训练的速度

RNN
RNN本质上是一个递推函数
一般的前馈网络,通常就是固定的输入输出,一次性接收输入,忽略了序列中的顺序信息;CNN在处理变长序列时,可以用华东窗口学习,但也难学习到序列间的长距离依赖
RNN优势:
适合处理序列数据,特别是带有时序关系的序列,比如文本数据
把每一个时间步中的信息编码到状态变量中,使网络具有一定的记忆能力,从而更好的理解序列信息
具有对序列中时序信息的刻画能力,因此在处理序列数据时往往能得到更准确的结果
普通的前馈网络就像火车的一节车厢,只有一个入口,一个出口;而RNN相当于一列火车,有多节车厢接收当前时间步的输入信息并输出编码后的状态信息(包括当前的状态和之前的所有状态)。
RNN常用激活函数为tanh而不是ReLU、sigm等,因为tanh值域为[-1,1],这与多数场景下特征分布以0为中心相吻合,也可以防止数值上溢问题

LSTM 在传统 RNN 的基础上加入了门控机制来限制信息的流动
主要通过遗忘门和输入门来实现长短期记忆:如果当前时间点没有重要信息,遗忘门接近为1,输入门0,此时过去的记忆将会被保存,从而实现长期记忆,反之亦然.短期记忆,如果当前和以前的记忆都重要,则遗忘门f->1,输入门i->1
在 LSTM 中,所有控制门都使用 sigmoid 作为激活函数
sigmoid 的值域为 (0,1),符合门控的定义
在计算候选记忆或隐藏状态时,使用tanh 作为激活函数

GRU和LSTM的不同:
GRU把遗忘门和输入门合并为更新门z,并使用重置门r代替输出门;
合并了记忆状态C和隐藏状态 h
更新门 z用于控制前一时刻的状态信息被融合到当前状态中的程度
重置门 r用于控制忽略前一时刻的状态信息的程度
为什么一般使用CNN代替RNN
训练RNN和LSTM非常困难,因为计算能力受到内存和带宽等的约束
每个LSTM单元需要四个仿射变换,且每一个时间步都需要运行一次,这样的仿射变换会要求非常多的内存带宽
添加更多的计算单元很容易,但添加更多的内存带宽却很难,这与目前的硬件加速技术不匹配
并且RNN容易发生梯度消失,虽然LSTM的门控,或者加入注意力机制模块,在一定程度上解决了这个问题,但实际上使模型更复杂了
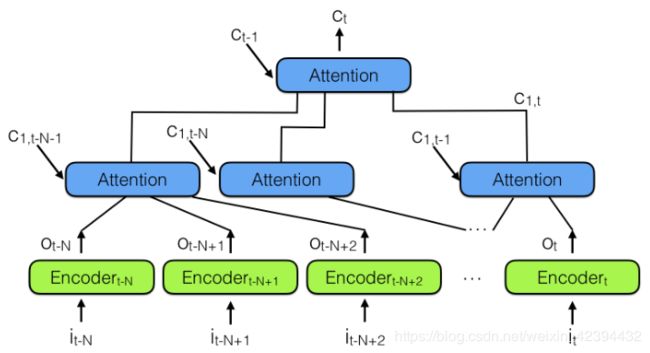
从任务角度考虑,差不多也是CNN更有利,LSTM因为能记忆比较长的信息,所以在推断方面有不错的表现
但是在事实类问答中,并不需要复杂的推断,答案往往藏在一个n-gram短语中,而CNN能很好的对n-gram建模
TCN时间卷积网络
使用CNN,只是最后一层一个加了attention,一个一个预测出来,而CNN是全部一起预测出来的
有人说时间卷积网络(TCN)将取代RNN成为NLP或者时序预测领域的王者。
RNN耗时太长,由于网络一次只读取、解析输入文本中的一个单词(或字符),深度神经网络必须等前一个单词处理完,才能进行下一个单词的处理。这意味着 RNN 不能像 CNN 那样进行大规模并行处理。
TCN是用来解决时间序列预测的算法,涉及到了一维卷积、扩张卷积、因果卷积、残差卷积的跳层连接等算法
扩张卷积的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息
因果卷积的理解可以认为是:不管是自然语言处理领域中的预测还是时序预测,都要求对时刻t 的预测yt只能通过t时刻之前的输入x1到xt-1来判别。这种思想有点类似于马尔科夫链。
残差卷积的跳层连接,防止梯度消失
CNN序列建模
一般认为 CNN 擅长处理网格结构的数据,比如图像(二维像素网络)
卷积层试图将神经网络中的每一小块进行更加深入的分析,从而得出抽象程度更高的特征。
一般来说通过卷积层处理的神经元结点矩阵会变得更深,即神经元的组织在第三个维度上会增加。
时序数据同样可以认为是在时间轴上有规律地采样而形成的一维网格
seq2seq
大部分自然语言问题都可以使用 Seq2Seq 模型解决,万物皆 Seq2Seq
seq2seq的核心思想是把一个输出序列,通过编码(Encode)和解码(Decode)两个过程映射到一个新的输出序列,一般都使用 RNN 进行建模
Seq2Seq 之所以流行,是因为它为不同的问题提供了一套端到端(End to End)的解决方案,免去了繁琐的中间步骤,从输入直接得到结果
比如机器翻译、机器问答、文本摘要、语音识别、图像描述等
有3种解码方法:贪心、Beam Search、维特比算法
贪心每到达一个节点,只选择当前状态的最优结果,其他都忽略,直到最后一个节点,贪心法只能得到某个局部最优解
Beam Search 会在每个节点保存当前最优的 k 个结果(排序后),其他结果将被“剪枝”,因为每次都有 k 个分支进入下一个状态。Beam Search 也不能保证全局最优,但能以较大的概率得到全局最优解。
维特比算法利用动态规划的方法可以保证得到全局最优解,但是当候选状态极大时,需要消耗大量的时间和空间搜索和保存状态,因此维特比算法只适合状态集比较小的情况
Beam Search集束搜索
该方法会保存前 beam_size 个最佳状态,每次解码时会根据所有保存的状态进行下一步扩展和排序,依然只保留前 beam_size 个最佳状态;循环迭代至最后一步,保存最佳选择。
当 beam_size = 1 时,Beam Search 即为贪心搜索
维特比(Viterbi)算法核心思想:利用动态规划可以求解任何图中的最短路径问题
其他最短路径算法:
Dijkstra 算法(迪杰斯特拉算法):基于贪心,用于求解某个顶点到其他所有顶点之间的最短路径,时间复杂度n2,适用范围广,可用于求解大部分图结构中的最短路径。
Floyd 算法(弗洛伊德算法):求解的是每一对顶点之间的最短路径,时间复杂度n3。
加速训练方法
CNN比RNN更适合并行架构
可以用optimizer:动量、自适应学习率
减少参数(比如用GRU代替LSTM)
参数初始化(BN)
外部方法:GPU加速.集群、CPU集群、数据并行.模型并行以及混合并行
about
MobileNet
近些年来,CNN由于其出色的表现,渐渐成为了图像领域中主流的算法框架。
CNN的表现如此突出主要是因为CNN模型有大量的可学习参数,使得CNN模型具备很强的学习能力和表达能力,然而,也正因为这些大量的参数使得在硬件平台上部署CNN模型时有较大困难,尤其是在一些计算资源非常受限的平台上,如移动设备、嵌入式设备等。
基于对CNN模型进行加速的要求,可以从快速网络结构设计的角度出发设计设计一些小而精的模型,比如mobile net等
他致力于打造一个轻量化的深度神经网络,以便应用于手机或者tesla电动汽车进行多对象识别
DDM 的卷积分成了 DD1 和 11M,前者叫深度空间分离卷积层(depthwise separable convolutions我就瞎翻译了),后者叫点空间卷积层(pointwise convolution)。
MobileNet大大减少了计算量(少了90%),但精度只下降了1%
cuda
NVIDIA的cpu并行计算架构
配置cuDNN可以进行神经网络的加速
相比标准的cuda,它在一些常用的神经网络操作上进行了性能的优化,比如卷积、pooling、归一化、激活层等等
使用
在编译caffe(或者其他深度学习库)时,只需要在make的配置文件Makefile.config中将USE_CUDNN取消注释即可
无人驾驶、图像处理
无人驾驶的等级:l0非自动化、l1辅助驾驶、l2部分自动化、l3有条件的自动驾驶、l4高度自动化、l5全自动
无人驾驶包括三个单元:感知(主要是传感器和智能感知算法)、决策(控制电路,软硬件)、控制单元(控制接口)

在自动驾驶领域中,许多任务同样可被抽象为图像分类、图像分割、目标检测三个基础问题
无人驾驶感知视觉算法:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD算法
R-CNN是候选区域region的CNN目标检测

fast RCNN
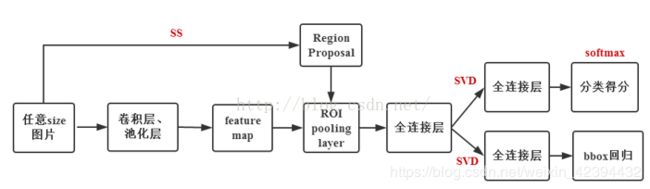
faster RCNN

学习资源:
cv视觉网:http://www.cvvision.cn/ 有一些图像处理、无人驾驶的教程
公众号:Apollo开发者社区 无人车相关信息、Udacity的学习视频
opencv的官方文档
CRNN
卷积循环神经网络CRNN=DCNN+RNN
CRNN的网络架构由三部分组成,包括卷积层,循环层和转录层
通过采用标准CNN模型(去除全连接层)中的卷积层和最大池化层来构造卷积层的组件做特征序列提取
一个深度双向循环神经网络是建立在卷积层的顶部,作为循环层做序列标注
转录是将RNN所做的每帧预测转换成标签序列的过程。数学上,转录是根据每帧预测找到具有最高概率的标签序列。在实践中,存在两种转录模式,即无词典转录和基于词典的转录。词典是一组标签序列,预测受拼写检查字典约束。在无词典模式中,预测时没有任何词典。在基于词典的模式中,通过选择具有最高概率的标签序列进行预测
CRNN与传统神经网络模型相比具有一些独特的优点:
1)可以直接从序列标签(例如单词)学习,不需要详细的标注(例如字符);
2)直接从图像数据学习信息表示时具有与DCNN相同的性质,既不需要手工特征也不需要预处理步骤,包括二值化/分割,组件定位等;
3)具有与RNN相同的性质,能够产生一系列标签;
4)对类序列对象的长度无约束,只需要在训练阶段和测试阶段对高度进行归一化
5)与现有技术相比,它在场景文本(字识别)上获得更好或更具竞争力的表现
6)它比标准DCNN模型包含的参数要少得多,占用更少的存储空间
线性回归和逻辑回归
在统计学中,线性回归是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析
他求最优解的方法有最小二乘法和梯度下降法
线性回归主要用来解决连续值预测的问题,逻辑回归用来解决分类的问题,输出的属于某个类别的概率
在SVM、GBDT、AdaBoost算法中都有涉及逻辑回归
线性回归使用拟合函数、最小二乘,逻辑回归使用预测函数、最大似然估计
线性回归的值域为无穷,逻辑回归值域为(0,1),构建分类问题
线性回归的问题:拟合程度不好,最好用一条平滑的曲线来拟合
在线性回归的预测函数外套一层sigmod函数,做二元分类
线性回归:y=wx+b,一般的最小二乘,多个未知数(特征)是y=a1x1+a2x2+b=AX+b(b叫做偏移量或误差项)
误差项是真实值和误差值之间的一个差距。那么肯定我们希望误差项越小越好
损失函数L=half(sumM((y^ -y)2))),(M是样本数),通过梯度下降法求损失函数最小值
scatter
pooling的好处有:减少特征计算量,防止过拟合,缩小图像规模,提升计算速度
opencv的灰度图就是R=G=B=原来的RGB相加/3,二值化就是让图像的像素点矩阵中的每个像素点的灰度值为0(黑色)或者255(白色)
常用的图片滤波器有均值滤波、高斯滤波、中值滤波、双边滤波、Sobel算子、Laplacian算子等
BP和CNN的区别:BP每层单元都是全连接的,而CNN他是连接到卷积核
卷积网络其实就是在全连接网络的基础上,把全连接改为部分连接,然后再利用权值共享的技巧大量减少网络需要修改的权值数量
RNN的梯度爆炸可以通过LSTM门控解决
False Positive:把合法的判断成非法的,误报,假阳性
False Negative:把非法的判断成合法的,漏报,假阴性
tensor张量、flow流图
tensorboard 神经网络计算图可视化
Keras是基于Theano和TensorFlow的深度学习库,由纯python编写
keras具有高度模块化,极简,和可扩充特性
他支持CNN和RNN,或二者的结合,无缝CPU和GPU切换
为什么要用softmax交叉熵做损失函数,平方误差函数也能做梯度下降啊?
熵考察的是单个的信息(分布)的期望,交叉熵考察的是两个的信息(分布)的期望
为了解决参数更新效率下降这一问题,我们使用交叉熵代价函数替换传统的平方误差函数
数学建模中关于数据分布的一个最基础的假设是什么?
数据分训练测试集.来自同一分布
DL和一般的图像识别的区别:一个是精确计算,一个是模糊计算(预测)
把一个str倒置,str[::-1]
协同过滤不是ML算法,而是推荐算法
二叉树遍历:层次.先序.中序.后序,先中后的区别就是return的三个值:根左右、左根右、左右根,递归的取左右子树得到遍历结果
我们只能够通过已知先序中序求后序或已知中序后序求先序,而不能够已知先序和后序求中序
Augmentor 数据扩充 argparse 程序命令行
OpenSSL 安全通信,SSL密码库工具
