ELK 开源实时日志分析平台
一、基础环境:
操作系统:Centos7.4
关闭防火墙、selinux
主机名解析:192.168.122.83 elk-node1(master机器) 192.168.122.175 elk-node2(slave机器)
二、Elasticsearch 部署(master和slave都要安装)
1. 下载并安装GPG Key
# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch2. 添加yum仓库
# vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-2.x]
name=Elasticsearch repository for 2.x packages
baseurl=http://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=13. 安装elasticsearch
# yum install -y elasticsearch4. 安装相关测试软件
下载安装epel源:epel-release-latest-7.noarch.rpm
# wget http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
# rpm -ivh epel-release-latest-7.noarch.rpm5. 安装java环境
# yum install -y java
# java -version
openjdk version "1.8.0_102"
OpenJDK Runtime Environment (build 1.8.0_102-b14)
OpenJDK 64-Bit Server VM (build 25.102-b14, mixed mode)6. 修改配置文件(master 和 slave 都配置完后进行启动测试)
master机器
1、创建搜集日志数据目录:
# mkdir -p /data/es-data
2、修改配置文件:
# vim /etc/elasticsearch/elasticsearch.yml //添加内容如下
cluster.name: wingcluster # 组名(同一个组,组名必须一致)
node.name: elk-node1 # 节点名称,建议和主机名一致
path.data: /data/es-data # 数据存放的路径
path.logs: /var/log/elasticsearch/ # 日志存放的路径
bootstrap.mlockall: true # 锁住内存,不被使用到交换分区去
network.host: 0.0.0.0 # 网络设置
http.port: 9200 # 端口
3、修改属组属主
# chown -R elasticsearch.elasticsearch /data/slave机器
1、创建搜集日志数据目录:
# mkdir -p /data/es-data
2、修改配置文件:
# cat /etc/elasticsearch/elasticsearch.yml
cluster.name: wingcluster
node.name: elk-node2 # 与master不同
path.data: /data/es-data
path.logs: /var/log/elasticsearch/
bootstrap.mlockall: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.multicast.enabled: false # 增加项目
discovery.zen.ping.unicast.hosts: ["172.16.113.155", "172.16.113.156"] # 增加项目
3、修改属组属主
# chown -R elasticsearch.elasticsearch /data/7、启动测试(web测试/命令测试)
# systemctl start elasticsearch
# ss -anpt |egrep "9200|9300"
LISTEN 0 50 :::9200 :::* users:(("java",pid=1088,fd=92))
LISTEN 0 50 :::9300 :::* users:(("java",pid=1088,fd=81))
TIME-WAIT 0 0 ::1:55236 ::1:9300
TIME-WAIT 0 0 ::ffff:127.0.0.1:47752 ::ffff:127.0.0.1:9300 web测试: http://192.168.122.83:9200
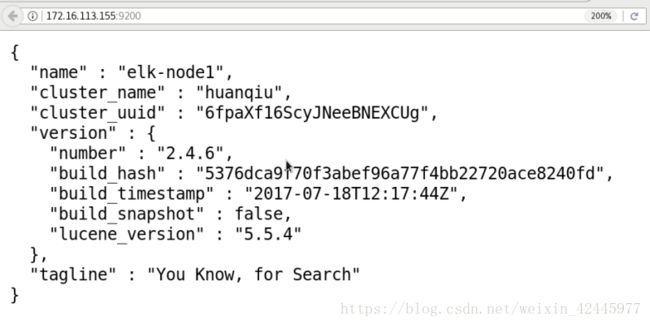
命令测试
# curl -i -XGET 'http://192.168.122.83:9200/_count?pretty' -d '{"query":{"match_all":{}}}'
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 99
{
"count" : 118,
"_shards" : {
"total" : 16,
"successful" : 16,
"failed" : 0
}
}
8.上述步骤安装测试完成,可选择安装页面测试插件,用来提供web方式的数据查看(head)和服务器监控(kopf)。
安装 head 插件
# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head
# chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/plugins
# systemctl restart elasticsearch
安装 kopf 监控插件
# /usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf
# chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/plugins
# systemctl restart elasticsearch通过插件访问测试格式(实验IP):
http://192.168.122.83:9200/_plugin/head/
http://192.168.122.83:9200/_plugin/kopf/#!/cluster
三、Logstash安装(安装在客户机,本实验安装在master和slave上,服务器充当客户机)
客户端安装logstash,收集到的数据写入到elasticsearch里,就可以登陆logstash界面查看
1. 下载并安装GPG Key
# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch2. 添加yum仓库
# vim /etc/yum.repos.d/logstash.repo
[logstash-2.1]
name=Logstash repository for 2.1.x packages
baseurl=http://packages.elastic.co/logstash/2.1/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=13.安装启动 logstash
# yum install -y logstash
# systemctl restart elasticsearch4. 数据搜集测试(ctrl +D 退出)
# /opt/logstash/bin/logstash -e 'input { stdin{} } output { stdout{} }'
Settings: Default filter workers: 1
Logstash startup completed
hello #输入这个
2016-11-11T06:41:07.690Z elk-node1 hello #输出这个5. logstash 的配置和文件的编写(简单例子,可以有其他格式)
# vim /etc/logstash/conf.d/first.conf # 编写配置文件
input {
file {
path => "/var/log/messages" # 指定分析的日志文件
type => "system"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.122.83:9200"] # 指定elasticsearch服务器
index => "system-%{+YYYY.MM.dd}"
}
}四、Kibana安装配置
1.安装 kibana
# cd /usr/local/src
# wget https://download.elastic.co/kibana/kibana/kibana-4.3.1-linux-x64.tar.gz
# tar zxf kibana-4.3.1-linux-x64.tar.gz
# mv kibana-4.3.1-linux-x64 /usr/local/
# ln -s /usr/local/kibana-4.3.1-linux-x64/ /usr/local/kibana2. 修改配置文件
# pwd
/usr/local/kibana/config
# cp kibana.yml kibana.yml.bak
# vim kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://192.168.122.83:9200"
kibana.index: ".kibana"3. 访问kibana
# /usr/local/kibana/bin/kibana # 启动kibana(终端中持续运行)http://172.168.122.83:5601/
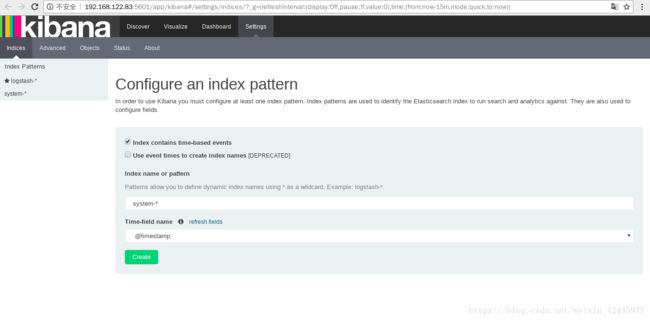
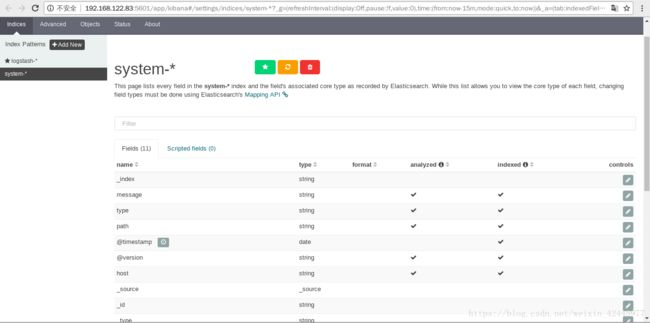
五、理论补充
1. ELK由ElasticSearch、Logstash和Kibana三个开源工具组成:
ElasticSearch
一个基于Lucene的开源分布式搜索服务器。
特点:
分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源, 自动搜索负载等。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
在elasticsearch中,所有节点的数据是均等的。
Logstash
可以对你的日志进行收集、过滤、分析,并将其存储供以后使用(如,搜索),logstash带有一个web界面,搜索和展示所有日志。
Kibana
一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮你汇总、分析和搜索重要数据日志。
2.master-slave模式:
master收集到日志后,会把一部分数据碎片到slave上(随机的一部分数据);
同时,master和slave又都会各自做副本,并把副本放到对方机器上,这样就保证了数据不会丢失。
如果master宕机了,那么客户端在日志采集配置中将elasticsearch主机指向改为slave,就可以保证ELK日志的正常采集和web展示。
3. 以下理论转发源链接:博主:蜷缩的蜗牛
A. Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
B. Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(如,搜索)。
C. Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
Filebeat、topbeat、packetbeat用于收集各应用、服务器等日志信息:
A. Filebeat:自定义需要收集的日志信息;
B. Topbeat:主要收集主机CPU、Mem、Disk、Process、Load等信息, 周期性的发送指标到elasticsearch。可以通过kibana创建自定义仪表盘如系统负载、服务器概述、内存或cpu使用情况、top进程、每个进程占用cpu或内存比例、磁盘使用情况等等。
C. Packetbeat:是分布式的,实时的嗅探每个事务的请求与响应,并将相关数据插入到elasticsearch中。packetbeat被动的嗅探网络流量,因此不会干扰应用程序。