Python网络爬虫之股票数据Scrapy爬虫实例介绍,实现与优化!(未成功生成要爬取的内容!)
结果TXT文本里面竟然没有内容!cry~


编写程序:
步骤:
1. 建立工程和Spider模板
2. 编写Spider
3. 编写ITEM Pipelines

代码:成功创建
D:\>cd pycodes
D:\pycodes>scrapy startproject BaiduStocks
New Scrapy project 'BaiduStocks', using template directory 'c:\\users\\hwp\\appdata\\local\\programs\\python\\python37\\lib\\site-packages\\scrapy\\templates\\project', created in:
D:\pycodes\BaiduStocks
You can start your first spider with:
cd BaiduStocks
scrapy genspider example example.com
D:\pycodes>
成功创建:


scrapy genspider stocks baidu.com代码:
D:\pycodes>dir
驱动器 D 中的卷是 大宝宝
卷的序列号是 6EE8-9B4D
D:\pycodes 的目录
2018/11/25 16:06 .
2018/11/25 16:06 ..
2018/11/25 16:06 BaiduStocks
2018/11/25 14:26 python123demo
0 个文件 0 字节
4 个目录 21,907,013,632 可用字节
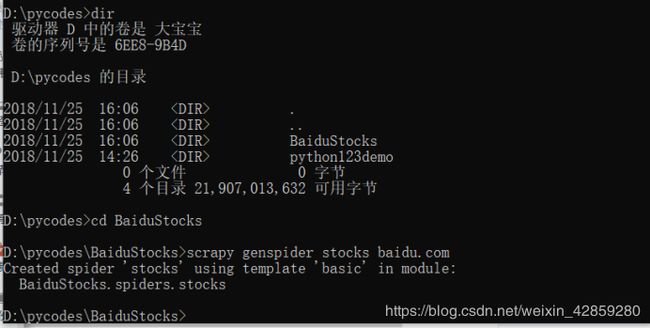
D:\pycodes>cd BaiduStocks
D:\pycodes\BaiduStocks>scrapy genspider stocks baidu.com
Created spider 'stocks' using template 'basic' in module:
BaiduStocks.spiders.stocks
D:\pycodes\BaiduStocks>
然后打开.py文件。


步骤二的代码:
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
#allowed_domains = ['baidu.com']
start_urls = ['http://quote.eastmoney.com/stocklist.html']
def parse(self, response):
for href in responce.css('a::attr(href)').expect():
try:
stock = re.findall(r"[s][hz]\d{6}",href)[0]
url = 'https://gupiao.baidu.com/stock/' + stock + 'html'
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
def paese_stock(self, response):
infoDict = {}
stockInfo = request.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*',keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*',valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key]=val
infoDict.update(
{'股票名称':re.findall('\s.*\(',name)[0].split()[0] + \re.findall('\>.*<', name)[0][1:-1]})
yield infoDict
pass

编写这个文件!

修改后代码:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksInfoPipeline(object):
def open_spider(self, spider):
self.f = open('BaidustockInfo.txt', 'w')
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item

然后修改setting.py配置文件。

修改圈起来的地方
修改之后:

功能:
-
从东方财富网获得股票的列表!
-
针对股票列表生成百度链接。
-
然后爬取。
-
再提取关键信息。
-
再后续处理!
CMD:
D:\pycodes\BaiduStocks>scrapy crawl stocks

OK!
D:\pycodes\BaiduStocks>scrapy genspider stocks baidu.com
Created spider 'stocks' using template 'basic' in module:
BaiduStocks.spiders.stocks
D:\pycodes\BaiduStocks>scrapy crawl stocks
2018-11-25 16:51:08 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: BaiduStocks)
2018-11-25 16:51:08 [scrapy.utils.log] INFO: Versions: lxml 4.2.5.0, libxml2 2.9.5, cssselect 1.0.3, parsel 1.5.1, w3lib 1.19.0, Twisted 18.9.0, Python 3.7.1 (v3.7.1:260ec2c36a, Oct 20 2018, 14:57:15) [MSC v.1915 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0j 20 Nov 2018), cryptography 2.4.2, Platform Windows-10-10.0.17134-SP0
2018-11-25 16:51:08 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'BaiduStocks', 'NEWSPIDER_MODULE': 'BaiduStocks.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['BaiduStocks.spiders']}
2018-11-25 16:51:08 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2018-11-25 16:51:09 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-11-25 16:51:09 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-11-25 16:51:09 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-11-25 16:51:09 [scrapy.core.engine] INFO: Spider opened
2018-11-25 16:51:09 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-11-25 16:51:09 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-11-25 16:51:09 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2018-11-25 16:51:09 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: 优化!
提高爬取速度!
改变并发数量来改变速度。变慢或者变快!
虽然有文本生成,但是文本是空空的! cry!
源代码:

stocks.py:
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = "stocks"
start_urls = ['https://quote.eastmoney.com/stocklist.html']
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"[s][hz]\d{6}", href)[0]
url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
def parse_stock(self, response):
infoDict = {}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*', keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*', valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key]=val
infoDict.update(
{'股票名称': re.findall('\s.*\(',name)[0].split()[0] + \
re.findall('\>.*\<', name)[0][1:-1]})
yield infoDict

pipelines.py:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksInfoPipeline(object):
def open_spider(self, spider):
self.f = open('BaiduStockInfo.txt', 'w')
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
settings.py文件中被修改的区域:
# Configure item pipelines
# See https://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
}

课程地址:https://www.icourse163.org/learn/BIT-1001870001?tid=1003245012&from=study#/learn/content?type=detail&id=1004574454&cid=1005754082
MOOC课!