python人工智能——机器学习——分类算法-k近邻算法——kaggle案例: Facebook V: Predicting Check Ins
题目及翻译
Facebook and Kaggle are launching a machine learning engineering competition for 2016.
Facebook和Kaggle正在推出2016年的机器学习工程竞赛。
Trail blaze your way to the top of the leaderboard to earn an opportunity at interviewing for one of the 10+ open roles as a software engineer, working on world class machine learning problems.
开拓者通过自己的方式进入排行榜的顶端,为10名作为软件工程师的开放角色中的一位获得面试机会,从而解决世界级的机器学习问题。

The goal of this competition is to predict which place a person would like to check in to.
本次比赛的目的是预测一个人想要登记的地方。
For the purposes of this competition, Facebook created an artificial world consisting of more than 100,000 places located in a 10 km by 10 km square.
为了本次比赛的目的,Facebook创建了一个人工世界,其中包括10多公里10平方公里的100,000多个地方。
For a given set of coordinates, your task is to return a ranked list of the most likely places.
对于给定的坐标集,您的任务是返回最可能位置的排名列表。
Data was fabricated to resemble location signals coming from mobile devices, giving you a flavor of what it takes to work with real data complicated by inaccurate and noisy values.
数据被制作成类似于来自移动设备的位置信号,让您了解如何处理由不准确和嘈杂的值导致的实际数据。
Inconsistent and erroneous location data can disrupt experience for services like Facebook Check In.
不一致和错误的位置数据可能会破坏Facebook Check In等服务的体验。
We highly encourage competitors to be active on Kaggle Scripts.
我们强烈鼓励竞争对手积极参与Kaggle Scripts。
Your work there will be thoughtfully included in the decision making process.
您在那里的工作将被认真地包含在决策过程中。
Please note: You must compete as an individual in recruiting competitions.
请注意:您必须在招募比赛中作为个人参加比赛。
You may only use the data provided to make your predictions.
您只能使用提供的数据进行预测。
数据
In this competition, you are going to predict which business a user is checking into based on their location, accuracy, and timestamp.
在本次竞赛中,您将根据用户的位置,准确性和时间戳预测用户正在检查的业务。
The train and test dataset are split based on time, and the public/private leaderboard in the test data are split randomly.
训练和测试数据集根据时间进行划分,测试数据中的公共/私人排行榜随机拆分。
There is no concept of a person in this dataset.
此数据集中没有人的概念。
All the row_id’s are events, not people.
所有row_id都是事件,而不是人。
Note: Some of the columns, such as time and accuracy, are intentionally left vague in their definitions.
注意:某些列(例如时间和准确性)在其定义中有意留下含糊不清的内容。
Please consider them as part of the challenge.
请将它们视为挑战的一部分。
File descriptions
文件说明
train.csv, test.csv
row_id: id of the check-in event
row_id:签入事件的id
x y: coordinates
xy:坐标
accuracy: location accuracy
准确度:定位精度
time: timestamp
时间:时间戳
place_id: id of the business, this is the target you are predicting
place_id:业务的ID,这是您预测的目标
sample_submission.csv - a sample submission file in the correct format with random predictions
sample_submission.csv - 具有随机预测的正确格式的样本提交文件
数据集下载
分析
特征值:x,y坐标,定位准确性,时间戳。
目标值:入住位置的id。
处理:
0读取数据
data = pd.read_csv("./facebook-v-predicting-check-ins/train.csv")
数据的处理
1、缩小数据集范围 DataFrame.query()
#1.缩小数据,查询数据筛选
data=data.query("x>1.0&x<1.25&y>2.5&y<2.75")
2、处理日期数据 pd.to_datetime、pd.DatetimeIndex
#处理时间的数据
time_value=pd.to_datetime(data['time'],unit='s')
print(time_value)

3、增加分割的日期数据
4、删除没用的日期数据
#把日期格式转换为字典格式
time_value=pd.DatetimeIndex(time_value)
#构造一些特征
data['day']=time_value.day
data['hour']=time_value.hour
data['weekday']=time_value.weekday
#把时间戳特征删除
data=data.drop(['time'],axis=1)
print(data)
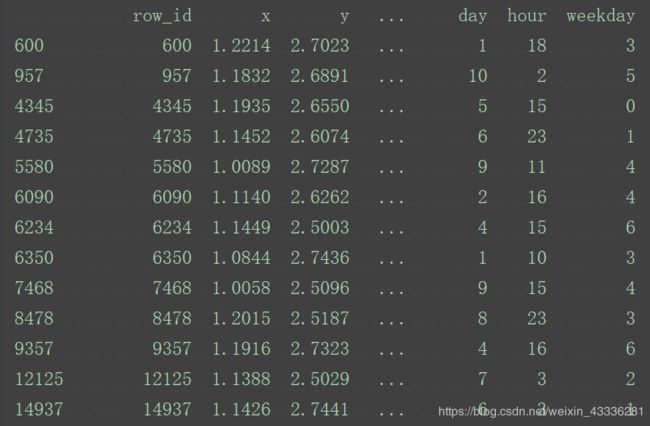

处理完之后,数据规模减少。
5、将签到位置少于n个用户的删除
place_count =data.groupby(‘place_id’).aggregate(np.count_nonzero)
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data[‘place_id’].isin(tf.place_id)]
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
6.标准化
#特征工程(标准化)
std=StandardScaler()
#对测试集和训练集的特征值进行标准化
x_train=std.fit_transform(x_train)
x_test=std.transform(x_test)
预测
# 进行算法流程 # 超参数
knn = KNeighborsClassifier(n_neighbors=5)
#fit() predict() score()
knn.fit(x_train,y_train)
#得出预测结果
y_predict=knn.predict(x_test)
print("预测的目标签到位置为:",y_predict)
#得出准确率
print("预测的准确率:",knn.score(x_test,y_test))
![]()
准确率才刚40%,有点低,再优化一下:
x = data.drop(['row_id'], axis=1)
![]()
行吧,,孬好及格了。
完整代码
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
def knncls():
"""
K-近邻预测用户签到位置
:return:None
"""
# 读取数据
data = pd.read_csv("./facebook-v-predicting-check-ins/train.csv")
# print(data.head(10))
#处理数据
#1.缩小数据,查询数据筛选
data=data.query("x>1.0&x<1.25&y>2.5&y<2.75")
#处理时间的数据
time_value=pd.to_datetime(data['time'],unit='s')
# print(time_value)
#把日期格式转换为字典格式
time_value=pd.DatetimeIndex(time_value)
#构造一些特征
data['day']=time_value.day
data['hour']=time_value.hour
data['weekday']=time_value.weekday
#把时间戳特征删除
data=data.drop(['time'],axis=1)
# print(data)
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
x = data.drop(['row_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
#特征工程(标准化)
std=StandardScaler()
#对测试集和训练集的特征值进行标准化
x_train=std.fit_transform(x_train)
x_test=std.transform(x_test)
# 进行算法流程 # 超参数
knn = KNeighborsClassifier(n_neighbors=5)
#fit() predict() score()
knn.fit(x_train,y_train)
#得出预测结果
y_predict=knn.predict(x_test)
print("预测的目标签到位置为:",y_predict)
#得出准确率
print("预测的准确率:",knn.score(x_test,y_test))
return None
if __name__ == "__main__":
knncls()
流程分析
1、数据集的处理
2、分割数据集
3、对数据集进行标准化
4、estimator流程进行分类预测
——————————————————————————————————————————
2019-7-17更新
好多人都要数据集,现在直接放在这了,直接拿吧。
链接:https://pan.baidu.com/s/1ZT39BIG8LjJ3F6GYfcbfPw
提取码:hoxm
复制这段内容后打开百度网盘手机App,操作更方便哦