Map类源码解析
一、Map接口的架构
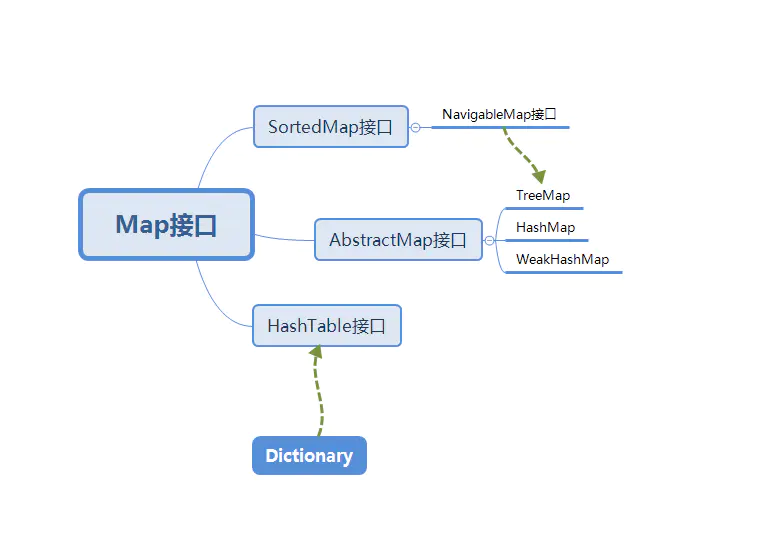
Map接口的架构试图如下:
01.png
①SortedMap接口继承Map接口,NavigableMap接口继承SortedMap接口,TreeMap实现NavigableMap接口;
SortedMap:
public interface SortedMap extends Map {} NavigableMap:
public interface NavigableMap extends SortedMap {} TreeMap:
public class TreeMap extends AbstractMap implements NavigableMap, Cloneable, java.io.Serializable{} ②AbstractMap接口实现了Map接口,TreeMap同时也继承了AbstractMap,HashMap和WeakHashMap继承了AbstractMap;
AbstractMap:
public abstract class AbstractMap implements Map {} HashMap:
public class HashMap extends AbstractMap implements Map, Cloneable, Serializable {} WeakHashMap:
public class WeakHashMap extends AbstractMap implements Map {} ③HashMap继承了Dictionary,并且实现了Map接口:
public class Hashtable extends Dictionary implements Map, Cloneable, java.io.Serializable {} 二、SortedMap、TreeMap、HashMap、HashTable的区别
1、SortedMap:是有序不可重复的,key值不可为空,value值可以为空;底层是TreeMap;线程不安全;
2、TreeMap:无序不可重复,key值不可为空,value值可以为空;底层是红黑树;线程不安全;
3、HashMap:无序不可重复;只有一个Key值可以为空,当key值为null的时候,其hashcode定为0,放在hash表的 第0个bucket中,value值可以为空;底层是Entry数组+链表+红黑树;线程不安全;
以下代码及注释来自java.util.HasMap
public V put(K key, V value) { if (table == EMPTY_TABLE) {
inflateTable(threshold);
} // 当key为null时,调用putForNullKey特殊处理
if (key == null) return putForNullKey(value); // ...}
private V putForNullKey(V value) { // key为null时,放到table[0]也就是第0个bucket中
for (Entry e = table[0]; e != null; e = e.next) { if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this); return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0); return null;
} 4、HashTable:无序不可重复,Key值和Value值不能为空,底层是Entry数组+链表+红黑树;线程安全;
以下代码及注释来自java.util.HashTable
public synchronized V put(K key, V value) {
// 如果value为null,抛出NullPointerException
if (value == null) { throw new NullPointerException();
}
// 如果key为null,在调用key.hashCode()时抛出NullPointerException
// HashTable方法之所以线程安全,是因为在与HashMap相同的方法上都进行了加锁(synchronized)操作;
public synchronized int size() { return count;
} /**
* Tests if this hashtable maps no keys to values.
*
* @return true if this hashtable maps no keys to values;
* false otherwise.
*/
public synchronized boolean isEmpty() { return count == 0;
} /**
* Returns an enumeration of the keys in this hashtable.
*
* @return an enumeration of the keys in this hashtable.
* @see Enumeration
* @see #elements()
* @see #keySet()
* @see Map
*/
public synchronized Enumeration keys() { return this.getEnumeration(KEYS);
}
} 三、HashMap的源码解析
1、基本原理,HashMap的底层是由Entry数组+链表+红黑树构成,这样设计的原理;当添加一个值计算出他的HashCode的时候,如果这个hashcode值已经存在,发生了hash碰撞,我们这里使用拉链法来解决这个问题,即在已经存在的这个值后面拉出一个链表,但是当数据量非常大的时候,这个链表会非常长,当查询一个值的话,会非常耗费时间,时间复杂度为O(n),因此在java1.8版本之后,当链表长度大于8的时候,会自动转换为红黑树,当长度小于6的时候,又会从红黑树转换为链表形态;
下面是添加的方法,同时还是HashSet的添加方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node[] tab; Node p; int n, i; if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); else {
Node e; K k; if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); break;
} if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) break;
p = e;
}
} if (e != null) { // existing mapping for key
V oldValue = e.value; if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); return oldValue;
}
}
++modCount; if (++size > threshold)
resize();
afterNodeInsertion(evict); return null;
}