深蓝学院从零开始手写VIO(三)——滑动窗口理论
深蓝学院从零开始手写VIO(三)——滑动窗口理论
- SLAM问题的概率建模
- 最大后验估计与加权最小二乘
- 一个简单的例子
- 舒尔补、条件概率与边缘概率
- 滑动窗口算法
- FEJ算法
声明:本专栏文章为深蓝学院《从零开始手写VIO》课程个人学习笔记,更多学习资源请咨询深蓝学院相关课程。
SLAM问题的概率建模
最大后验估计与加权最小二乘
SLAM问题可以建模为一个贝叶斯估计问题(关于贝叶斯估计的相关内容可参见另一篇文章——贝叶斯滤波)。对于SLAM问题来说,记待估计变量为 X = { x 1 , x 2 , ⋯ , x m } \bm{\mathcal{X}}=\{\bm{x}_1,\bm{x}_2,\cdots,\bm{x}_m\} X={x1,x2,⋯,xm},观测量为 Z = { z 1 , z 2 , ⋯ , z n } \bm{\mathcal{Z}}=\{\bm{z}_1,\bm{z}_2,\cdots,\bm{z}_n\} Z={z1,z2,⋯,zn},那么根据贝叶斯法则有:
p ( X ∣ Z ) = p ( Z ∣ X ) p ( X ) p ( Z ) p(\bm{\mathcal{X}}|\bm{\mathcal{Z}})=\frac{p(\bm{\mathcal{Z}}|\bm{\mathcal{X}})p(\bm{\mathcal{X}})}{p(\bm{\mathcal{Z}})} p(X∣Z)=p(Z)p(Z∣X)p(X)
式中称为先验概率,称为似然概率,称为后验概率。SLAM状态估计的本质就是寻找到一个状态变量 X ∗ \bm{\mathcal{X}}^\ast X∗使得后验概率最大,即求解最大后验(maximum a posterior,MAP)的过程:
X ∗ = arg max X ( p ( X ∣ Z ) ) = arg max X p ( Z ∣ X ) p ( X ) p ( Z ) \begin{aligned} \bm{\mathcal{X}}^\ast&=\arg\max\limits_{\bm{\mathcal{X}}}(p(\bm{\mathcal{X}}|\bm{\mathcal{Z}}))\\ &=\arg\max\limits_{\bm{\mathcal{X}}}\frac{p(\bm{\mathcal{Z}}|\bm{\mathcal{X}})p(\bm{\mathcal{X}})}{p(\bm{\mathcal{Z}})} \end{aligned} X∗=argXmax(p(X∣Z))=argXmaxp(Z)p(Z∣X)p(X)
略去与 X \bm{\mathcal{X}} X无关的 p ( Z ) p(\bm{\mathcal{Z}}) p(Z)并将上式展开有:
X ∗ = arg max X ∏ i = 1 n p ( z i ∣ X ) p ( X ) \bm{\mathcal{X}}^\ast=\arg\max\limits_{\bm{\mathcal{X}}}\prod\limits_{i=1}^n p(\bm{z}_i|\bm{\mathcal{X}})p(\bm{\mathcal{X}}) X∗=argXmaxi=1∏np(zi∣X)p(X)
上式的求解需要明确式中各概率分布的具体形式,与贝叶斯滤波类似我们同样先来看符合高斯分布的情况。在高斯分布下,对上式求解 − log -\log −log将求解最大值( arg max \arg\max argmax)转变为求解最小值( arg min \arg\min argmin)有:
X ∗ = arg min X ∑ i = 1 n − log ( p ( z i ∣ X ) ) − l o g ( p ( X ) ) \bm{\mathcal{X}}^\ast=\arg\min\limits_{\bm{\mathcal{X}}}\sum\limits_{i=1}^n -\log(p(\bm{z}_i|\bm{\mathcal{X}}))-log(p(\bm{\mathcal{X}})) X∗=argXmini=1∑n−log(p(zi∣X))−log(p(X))
假设 p ( z i ∣ X ) ∼ N ( μ i , Σ i ) p(\bm{z}_i|\bm{\mathcal{X}})\sim N(\bm{\mu}_i,\bm{\Sigma}_i) p(zi∣X)∼N(μi,Σi), p ( X ) ∼ N ( μ X , Σ X ) p(\bm{\mathcal{X}})\sim N(\bm{\mu}_\bm{\mathcal{X}},\bm{\Sigma}_\bm{\mathcal{X}}) p(X)∼N(μX,ΣX),将其概率分布带入上式有:
X ∗ = arg min X ∑ i = 1 n ( z i − μ i ) T Σ i − 1 ( z i − μ i ) + ( X − μ X ) T Σ X − 1 ( X − μ X ) \bm{\mathcal{X}}^\ast=\arg\min\limits_{\bm{\mathcal{X}}}\sum\limits_{i=1}^n (\bm{z}_i-\bm{\mu}_i)^T\bm{\Sigma}_i^{-1}(\bm{z}_i-\bm{\mu}_i)+(\bm{\mathcal{X}}-\bm{\mu}_\bm{\mathcal{X}})^T\bm{\Sigma}_\bm{\mathcal{X}}^{-1}(\bm{\mathcal{X}}-\bm{\mu}_\bm{\mathcal{X}}) X∗=argXmini=1∑n(zi−μi)TΣi−1(zi−μi)+(X−μX)TΣX−1(X−μX)
可以看到,在高斯分布下,求解MAP问题就等价于求解一个加权最小二乘问题,这里的加权矩阵是协方差矩阵的逆 Σ − 1 \bm{\Sigma}^{-1} Σ−1,由于其表征了不同误差权重的信息量,因此其也称为信息矩阵 Λ = Σ − 1 \bm{\Lambda}=\bm{\Sigma}^{-1} Λ=Σ−1。
一个简单的例子
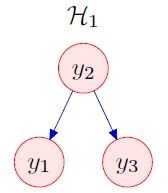
对于上图所示的贝叶斯网络(原图及更多例子参见文献:Preamble to ‘The Humble Gaussian Distribution’. David MacKay),假设各变量之间的关系(这里出于习惯问题,使用 x x x代替图中的 y y y)如下:
{ x 2 = v 2 , v 2 ∼ N ( 0 , σ 2 2 ) x 1 = w 1 x 2 + v 1 , v 1 ∼ N ( 0 , σ 1 2 ) x 3 = w 3 x 2 + v 3 , v 3 ∼ N ( 0 , σ 3 2 ) \left\{\begin{aligned} x_2&=v_2,\quad v_2\sim N(0,\sigma_2^2)\\ x_1&=w_1x_2+v_1,\quad v_1\sim N(0,\sigma_1^2)\\ x_3&=w_3x_2+v_3,\quad v_3\sim N(0,\sigma_3^2) \end{aligned}\right. ⎩⎪⎨⎪⎧x2x1x3=v2,v2∼N(0,σ22)=w1x2+v1,v1∼N(0,σ12)=w3x2+v3,v3∼N(0,σ32)
这里由于三个变量均值均为0,因此其协方差矩阵为(式中 x = [ x 1 , x 2 , x 3 ] T \bm{x}=[x_1,x_2,x_3]^T x=[x1,x2,x3]T):
Σ = E ( x x T ) − E ( x ) 2 = E ( x x T ) = E ( [ x 1 x 1 x 1 x 2 x 1 x 3 x 2 x 1 x 2 x 2 x 2 x 3 x 3 x 1 x 3 x 2 x 3 x 3 ] ) = [ E ( x 1 x 1 ) E ( x 1 x 2 ) E ( x 1 x 3 ) E ( x 2 x 1 ) E ( x 2 x 2 ) E ( x 2 x 3 ) E ( x 3 x 1 ) E ( x 3 x 2 ) E ( x 3 x 3 ) ] \begin{aligned} \bm{\Sigma}&=E(\bm{x}\bm{x}^T)-E(\bm{x})^2=E(\bm{x}\bm{x}^T)\\ &=E\left(\begin{bmatrix} x_1x_1 & x_1x_2 & x_1x_3\\ x_2x_1 & x_2x_2 & x_2x_3\\ x_3x_1 & x_3x_2 & x_3x_3\\ \end{bmatrix}\right)\\ &=\begin{bmatrix} E(x_1x_1) & E(x_1x_2) & E(x_1x_3)\\ E(x_2x_1) & E(x_2x_2) & E(x_2x_3)\\ E(x_3x_1) & E(x_3x_2) & E(x_3x_3)\\ \end{bmatrix} \end{aligned} Σ=E(xxT)−E(x)2=E(xxT)=E⎝⎛⎣⎡x1x1x2x1x3x1x1x2x2x2x3x2x1x3x2x3x3x3⎦⎤⎠⎞=⎣⎡E(x1x1)E(x2x1)E(x3x1)E(x1x2)E(x2x2)E(x3x2)E(x1x3)E(x2x3)E(x3x3)⎦⎤
协方差矩阵中的各元素都可以通过对应的变换求出,这里给个例子,其余项可以按照同样方法计算:
E ( x 1 x 3 ) = E ( ( w 1 x 2 + v 1 ) ( w 3 x 2 + v 3 ) ) = E ( w 1 w 3 x 2 2 + w 1 x 2 v 3 + w 3 v 1 x 2 + v 1 v 3 ) = w 1 w 3 E ( x 2 2 ) = x 1 x 3 σ 2 2 \begin{aligned} E(x_1x_3)&=E((w_1x_2+v1)(w_3x_2+v_3))\\ &=E(w_1w_3x_2^2+w_1x_2v_3+w_3v_1x_2+v_1v_3)\\ &=w_1w_3E(x_2^2)=x_1x_3\sigma_2^2 \end{aligned} E(x1x3)=E((w1x2+v1)(w3x2+v3))=E(w1w3x22+w1x2v3+w3v1x2+v1v3)=w1w3E(x22)=x1x3σ22
最终的协方差矩阵为:
Σ = [ w 1 2 σ 2 2 + σ 1 2 w 1 σ 2 2 w 1 w 3 σ 2 2 w 1 σ 2 2 σ 2 2 w 3 σ 2 2 w 1 w 3 σ 2 2 + σ 1 2 w 3 σ 2 2 w 3 σ 2 2 + σ 3 2 ] \bm{\Sigma}=\begin{bmatrix} w_1^2\sigma_2^2+\sigma_1^2 & w_1\sigma_2^2 & w_1w_3\sigma_2^2 \\ w_1\sigma_2^2 & \sigma_2^2 & w_3\sigma_2^2 \\ w_1w_3\sigma_2^2+\sigma_1^2 & w_3\sigma_2^2 & w_3\sigma_2^2+\sigma_3^2 \\ \end{bmatrix} Σ=⎣⎡w12σ22+σ12w1σ22w1w3σ22+σ12w1σ22σ22w3σ22w1w3σ22w3σ22w3σ22+σ32⎦⎤
在获取了协方差矩阵 Σ \bm{\Sigma} Σ后,如果我们直接通过求逆的方式求解信息矩阵 Λ \bm{\Lambda} Λ无疑是较为复杂的。另一方面,在高斯分布的概率密度函数的指数项中,天然存在着信息矩阵和变量的乘积形式 x T Λ x \bm{x}^T\bm{\Lambda}\bm{x} xTΛx,因此如果我们能求解出 x \bm{x} x的概率密度函数即可从中分解出信息矩阵 Σ \bm{\Sigma} Σ。
对于本例,根据其对应的贝叶斯网络模型有:
p ( x 1 , x 2 , x 3 ) = p ( x 2 ) p ( x 1 ∣ x 2 ) p ( x 3 ∣ x 2 ) = 1 Z 2 exp ( − x 2 2 2 σ 2 2 ) 1 Z 1 exp ( − ( x 1 − w 1 x 2 ) 2 2 σ 1 2 ) 1 Z 3 exp ( − ( x 3 − w 3 x 2 ) 2 2 σ 2 2 ) = 1 Z 2 Z 1 Z 3 exp ( − x 2 2 2 σ 2 2 − ( x 1 − w 1 x 2 ) 2 2 σ 1 2 − ( x 3 − w 3 x 2 ) 2 2 σ 2 2 ) = 1 Z 2 Z 1 Z 3 exp ( − x 2 2 [ 1 2 σ 2 2 + w 1 2 2 σ 1 2 + w 3 2 2 σ 3 2 ] − x 1 2 1 2 σ 1 2 + 2 x 1 x 2 w 1 2 σ 1 2 − x 3 2 1 2 σ 3 2 + 2 x 2 x 3 w 3 2 σ 3 2 ) = 1 Z 2 Z 1 Z 3 exp ( − 1 2 [ x 1 x 2 x 3 ] [ 1 σ 1 2 − w 1 σ 1 2 0 − w 1 σ 1 2 [ 1 σ 2 2 + w 1 2 σ 1 2 + w 3 2 σ 3 2 ] − w 3 σ 3 2 0 − w 3 σ 3 2 1 σ 3 2 ] [ x 1 x 2 x 3 ] ) \begin{aligned} p(x_1,x_2,x_3)&=p(x_2)p(x_1|x_2)p(x_3|x_2)\\ &=\frac{1}{Z_2}\exp(-\frac{x_2^2}{2\sigma_2^2})\frac{1}{Z_1}\exp(-\frac{(x_1-w_1x_2)^2}{2\sigma_1^2})\frac{1}{Z_3}\exp(-\frac{(x_3-w_3x_2)^2}{2\sigma_2^2})\\ &=\frac{1}{Z_2Z_1Z_3}\exp\left(-\frac{x_2^2}{2\sigma_2^2}-\frac{(x_1-w_1x_2)^2}{2\sigma_1^2}-\frac{(x_3-w_3x_2)^2}{2\sigma_2^2}\right)\\ &=\frac{1}{Z_2Z_1Z_3}\exp\left(-x_2^2\left[\frac{1}{2\sigma_2^2}+\frac{w_1^2}{2\sigma_1^2}+\frac{w_3^2}{2\sigma_3^2}\right]-x_1^2\frac{1}{2\sigma_1^2}+2x_1x_2\frac{w_1}{2\sigma_1^2}-x_3^2\frac{1}{2\sigma_3^2}+2x_2x_3\frac{w_3}{2\sigma_3^2}\right)\\ &=\frac{1}{Z_2Z_1Z_3}\exp\left(-\frac{1}{2}\left[\begin{array}{ccc}x_1 & x_2 & x_3\end{array}\right]\begin{bmatrix} \frac{1}{\sigma_1^2} & -\frac{w_1}{\sigma_1^2} & 0\\ -\frac{w_1}{\sigma_1^2} & \left[\frac{1}{\sigma_2^2}+\frac{w_1^2}{\sigma_1^2}+\frac{w_3^2}{\sigma_3^2}\right] & -\frac{w_3}{\sigma_3^2}\\ 0 & -\frac{w_3}{\sigma_3^2} & \frac{1}{\sigma_3^2} \end{bmatrix}\left[\begin{array}{c}x_1 \\ x_2 \\ x_3\end{array}\right]\right) \end{aligned} p(x1,x2,x3)=p(x2)p(x1∣x2)p(x3∣x2)=Z21exp(−2σ22x22)Z11exp(−2σ12(x1−w1x2)2)Z31exp(−2σ22(x3−w3x2)2)=Z2Z1Z31exp(−2σ22x22−2σ12(x1−w1x2)2−2σ22(x3−w3x2)2)=Z2Z1Z31exp(−x22[2σ221+2σ12w12+2σ32w32]−x122σ121+2x1x22σ12w1−x322σ321+2x2x32σ32w3)=Z2Z1Z31exp⎝⎜⎜⎛−21[x1x2x3]⎣⎢⎢⎡σ121−σ12w10−σ12w1[σ221+σ12w12+σ32w32]−σ32w30−σ32w3σ321⎦⎥⎥⎤⎣⎡x1x2x3⎦⎤⎠⎟⎟⎞
注意这里虽然 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3各自的边缘分布都是零均值的,但条件分布并不是。这里给出信息矩阵的几条性质:
- 信息矩阵中的0项表示对应变量在给定其他标量的条件下,互相独立;
- 信息矩阵中的系数大于零,则两个变量之间负相关;系数小于零,则两个变量之间正相关;
在本例的信息矩阵中, Λ 13 = Λ 31 = 0 \Lambda_{13}=\Lambda_{31}=0 Λ13=Λ31=0,这意味着变量 x 1 x_1 x1和 x 3 x_3 x3在给定条件 x 2 x_2 x2的条件下是互相独立的,而初始的协方差矩阵二者的对象项并不为零,表示两者的边缘分布并不是独立的。
舒尔补、条件概率与边缘概率
在高斯分布下,由联合分布求解条件分布中的协方差传递过程,本质上是求解分块矩阵舒尔补的过程(具体参见滤波估计理论(二)——卡尔曼滤波)。但在求解加权最小二乘问题中,我们需要进行操作的往往是信息矩阵而非协方差矩阵,在进一步讨论钱,这里我们首先引入一个重要的定理。
定理1:舒尔补求逆定理。对于分块矩阵 M = [ A B C D ] \bm{M}=\begin{bmatrix}\bm{A} & \bm{B} \\ \bm{C} & \bm{D}\bm{}\end{bmatrix} M=[ACBD],其可以化为如下的形式,其中 Δ A \Delta_\bm{A} ΔA为矩阵 A \bm{A} A相对于矩阵 M \bm{M} M的舒尔补:
[ A B C D ] = [ I 0 C A − 1 I ] [ A 0 0 Δ A ] [ I A − 1 B 0 I ] \begin{bmatrix} \bm{A} & \bm{B}\\ \bm{C} & \bm{D} \end{bmatrix}=\begin{bmatrix} \bm{I} & \bm{0}\\ \bm{C}\bm{A}^{-1} & \bm{I} \end{bmatrix}\begin{bmatrix} \bm{A} & \bm{0}\\ \bm{0} & \Delta_\bm{A} \end{bmatrix}\begin{bmatrix} \bm{I} & \bm{A}^{-1}\bm{B}\\ \bm{0} & \bm{I} \end{bmatrix} [ACBD]=[ICA−10I][A00ΔA][I0A−1BI]
那么矩阵 M \bm{M} M的逆可以写为:
[ A B C D ] − 1 = [ I − A − 1 B 0 I ] [ A 0 0 Δ A ] [ I 0 − C A − 1 I ] \begin{bmatrix} \bm{A} & \bm{B}\\ \bm{C} & \bm{D} \end{bmatrix}^{-1}=\begin{bmatrix} \bm{I} & -\bm{A}^{-1}\bm{B}\\ \bm{0} & \bm{I} \end{bmatrix}\begin{bmatrix} \bm{A} & \bm{0}\\ \bm{0} & \Delta_\bm{A} \end{bmatrix}\begin{bmatrix} \bm{I} & \bm{0}\\ -\bm{C}\bm{A}^{-1} & \bm{I} \end{bmatrix} [ACBD]−1=[I0−A−1BI][A00ΔA][I−CA−10I]
在了解这一定理之后,我们来看一个简单的例子。假设存在多元高斯分布 x = [ a , b ] , a ∼ N ( 0 , A ) , b ∼ N ( 0 , B ) \bm{x}=[a,b],a\sim N(0,A),b\sim N(0,B) x=[a,b],a∼N(0,A),b∼N(0,B),则 x \bm{x} x的协方差矩阵和对应的信息矩阵为:
Σ = [ A C T C B ] Λ = Σ − 1 = [ I − A − 1 C T 0 I ] [ A − 1 0 0 Δ A − 1 ] [ I 0 − C A − 1 I ] = [ I − A − 1 C T 0 I ] [ A − 1 0 − Δ A − 1 C A − 1 Δ A − 1 ] = [ A − 1 + A − 1 C T Δ A − 1 C A − 1 − A − 1 C T Δ A − 1 − Δ A − 1 C A − 1 Δ A − 1 ] = [ Λ 11 Λ 12 Λ 21 Λ 22 ] \begin{aligned} \bm{\Sigma}&=\begin{bmatrix} \bm{A} & \bm{C}^T \\ \bm{C} & \bm{B} \end{bmatrix}\\ \bm{\Lambda}=\bm{\Sigma}^{-1}&=\begin{bmatrix} \bm{I} & -\bm{A}^{-1}\bm{C}^T\\ \bm{0} & \bm{I} \end{bmatrix}\begin{bmatrix} \bm{A}^{-1} & \bm{0}\\ \bm{0} & \Delta_\bm{A}^{-1} \end{bmatrix}\begin{bmatrix} \bm{I} & \bm{0}\\ -\bm{C}\bm{A}^{-1} & \bm{I} \end{bmatrix}\\ &=\begin{bmatrix} \bm{I} & -\bm{A}^{-1}\bm{C}^T\\ \bm{0} & \bm{I} \end{bmatrix}\begin{bmatrix} \bm{A}^{-1} & \bm{0}\\ -\Delta_\bm{A}^{-1}\bm{C}\bm{A}^{-1} & \Delta\bm{A}^{-1} \end{bmatrix}\\ &=\begin{bmatrix} \bm{A}^{-1}+\bm{A}^{-1}\bm{C}^T\Delta_\bm{A}^{-1}\bm{C}\bm{A}^{-1} & -\bm{A}^{-1}\bm{C}^T\Delta_\bm{A}^{-1}\\ -\Delta_\bm{A}^{-1}\bm{C}\bm{A}^{-1} & \Delta_\bm{A}^{-1} \end{bmatrix}\\ &=\begin{bmatrix} \Lambda_{11} & \Lambda_{12}\\ \Lambda_{21} & \Lambda_{22}\\ \end{bmatrix} \end{aligned} ΣΛ=Σ−1=[ACCTB]=[I0−A−1CTI][A−100ΔA−1][I−CA−10I]=[I0−A−1CTI][A−1−ΔA−1CA−10ΔA−1]=[A−1+A−1CTΔA−1CA−1−ΔA−1CA−1−A−1CTΔA−1ΔA−1]=[Λ11Λ21Λ12Λ22]
从联合分布的信息矩阵中,我们可以分解出边缘分布的信息矩阵为:
Λ A = A − 1 = ( A − 1 + A − 1 C T Δ A − 1 C A − 1 ) − ( A − 1 C T Δ A − 1 ) ( Δ A ) ( Δ A − 1 C A − 1 ) = Λ 11 − Λ 12 Λ 22 − 1 Λ 21 \begin{aligned} \bm{\Lambda}_A=\bm{A}^{-1}&=(\bm{A}^{-1}+\bm{A}^{-1}\bm{C}^T\Delta_\bm{A}^{-1}\bm{C}\bm{A}^{-1}) - (\bm{A}^{-1}\bm{C}^T\Delta_\bm{A}^{-1})(\Delta_\bm{A})(\Delta_\bm{A}^{-1}\bm{C}\bm{A}^{-1})\\ &=\Lambda_{11}-\Lambda_{12}\Lambda_{22}^{-1}\Lambda_{21} \end{aligned} ΛA=A−1=(A−1+A−1CTΔA−1CA−1)−(A−1CTΔA−1)(ΔA)(ΔA−1CA−1)=Λ11−Λ12Λ22−1Λ21
即我们从概率分布 p ( a , b ) p(a,b) p(a,b)中获得了边缘化变量 b b b后的边缘概率 p ( a ) p(a) p(a)对应的信息矩阵。
滑动窗口算法
对于加权最小二乘问题,其具有如下形式的正则方程:
J T Σ − 1 J δ X = − J T Σ − 1 r \bm{J}^T\bm{\Sigma}^{-1}\bm{J}\delta\bm{\mathcal{X}}=-\bm{J}^T\bm{\Sigma}^{-1}\bm{r} JTΣ−1JδX=−JTΣ−1r
为了方便,我们通常也会记 Λ = J T Σ − 1 J \bm{\Lambda}=\bm{J}^T\bm{\Sigma}^{-1}\bm{J} Λ=JTΣ−1J,也称其为信息矩阵。
 在滑窗算法中,每当新的状态量进入窗口时,由于窗口的尺寸是一定的,我们需要去除旧的状态量并添加新的状态量。那么我们能否直接抛弃旧的状态量呢?答案是并不可以,例如在上图所示的模型中,在新的状态量 x 7 x_7 x7来临时,我们如果直接删除最老的状态量 x 1 x_1 x1,那么变量 x 2 − x 5 x_2-x_5 x2−x5将相互独立,这将破坏状态量之间的约束关系。从概率的角度来看,滑动窗口可以视为一个联合概率密度函数 p ( x 1 , x 2 , x 3 , x 4 , x 5 , x 6 ) p(x_1,x_2,x_3,x_4,x_5,x_6) p(x1,x2,x3,x4,x5,x6)移除老状态量的过程,就相当于我们需要从该联合概率密度函数中求解边缘分布 p ( x 2 , x 3 , x 4 , x 5 , x 6 ) p(x_2,x_3,x_4,x_5,x_6) p(x2,x3,x4,x5,x6),而在大多数情况下, p ( x 1 , x 2 , x 3 , x 4 , x 5 , x 6 ) ≠ p ( x 2 , x 3 , x 4 , x 5 , x 6 ) p ( x 1 ) p(x_1,x_2,x_3,x_4,x_5,x_6)\neq p(x_2,x_3,x_4,x_5,x_6)p(x_1) p(x1,x2,x3,x4,x5,x6)=p(x2,x3,x4,x5,x6)p(x1),因此我们需要采用另一种策略去处理旧变量,获得边缘分布,即旧变量的边缘化(marginalization)过程(上图中c所示)。
在滑窗算法中,每当新的状态量进入窗口时,由于窗口的尺寸是一定的,我们需要去除旧的状态量并添加新的状态量。那么我们能否直接抛弃旧的状态量呢?答案是并不可以,例如在上图所示的模型中,在新的状态量 x 7 x_7 x7来临时,我们如果直接删除最老的状态量 x 1 x_1 x1,那么变量 x 2 − x 5 x_2-x_5 x2−x5将相互独立,这将破坏状态量之间的约束关系。从概率的角度来看,滑动窗口可以视为一个联合概率密度函数 p ( x 1 , x 2 , x 3 , x 4 , x 5 , x 6 ) p(x_1,x_2,x_3,x_4,x_5,x_6) p(x1,x2,x3,x4,x5,x6)移除老状态量的过程,就相当于我们需要从该联合概率密度函数中求解边缘分布 p ( x 2 , x 3 , x 4 , x 5 , x 6 ) p(x_2,x_3,x_4,x_5,x_6) p(x2,x3,x4,x5,x6),而在大多数情况下, p ( x 1 , x 2 , x 3 , x 4 , x 5 , x 6 ) ≠ p ( x 2 , x 3 , x 4 , x 5 , x 6 ) p ( x 1 ) p(x_1,x_2,x_3,x_4,x_5,x_6)\neq p(x_2,x_3,x_4,x_5,x_6)p(x_1) p(x1,x2,x3,x4,x5,x6)=p(x2,x3,x4,x5,x6)p(x1),因此我们需要采用另一种策略去处理旧变量,获得边缘分布,即旧变量的边缘化(marginalization)过程(上图中c所示)。
可以看出,边缘化之后,剩余的变量之间并非完全独立的,而是依旧存在依赖关系。而我们知道,信息矩阵中的非零项表征了各状态量之间的条件独立性,下图给出了从联合分布的信息矩阵中边缘化掉(边缘化过程参见上面的舒尔补求逆定理) x 1 x_1 x1过程中信息矩阵的变化过程。如果我们从信息矩阵 Λ \bm{\Lambda} Λ中直接去掉 x 1 x_1 x1,得到的信息矩阵为 Λ a a \bm{\Lambda}_{aa} Λaa;而边缘化 x 1 x_1 x1之后得到的信息矩阵为 Λ a a − Λ a b Λ b b − 1 Λ b a \Lambda_{aa}-\Lambda_{ab}\Lambda_{bb}^{-1}\Lambda_{ba} Λaa−ΛabΛbb−1Λba,相比于 Λ a a \bm{\Lambda}_{aa} Λaa,其填充了(fill-in)了许多的非零项,这与上图中的边正是一一对应的。

FEJ算法
记需要边缘化的变量为 x m \bm{x}_m xm,剩余变量为 x r \bm{x}_r xr,对应的的marginalization过程为:
[ Λ m m Λ m r Λ r m Λ r r ] [ x m x r ] = − [ b m m b m r ] [ Λ m m Λ m r 0 Λ r r − Λ r m Λ m m − 1 Λ m r ] [ x m x r ] = − [ b m m b m r − Λ r m Λ m m − 1 b m m ] \begin{aligned} \begin{bmatrix} \bm{\Lambda}_{mm} & \bm{\Lambda}_{mr}\\ \bm{\Lambda}_{rm} & \bm{\Lambda}_{rr} \end{bmatrix}\left[\begin{array}{c}\bm{x}_m \\ \bm{x}_r\end{array}\right]&=-\left[\begin{array}{c}\bm{b}_{mm} \\ \bm{b}_{mr}\end{array}\right]\\ \begin{bmatrix} \bm{\Lambda}_{mm} & \bm{\Lambda}_{mr}\\ \bm{0} & \bm{\Lambda}_{rr}-\bm{\Lambda}_{rm}\bm{\Lambda}_{mm}^{-1}\bm{\Lambda}_{mr} \end{bmatrix}\left[\begin{array}{c}\bm{x}_m \\ \bm{x}_r\end{array}\right]&=-\left[\begin{array}{c}\bm{b}_{mm} \\ \bm{b}_{mr}-\bm{\Lambda}_{rm}\bm{\Lambda}_{mm}^{-1}\bm{b}_{mm}\end{array}\right]\\ \end{aligned} [ΛmmΛrmΛmrΛrr][xmxr][Λmm0ΛmrΛrr−ΛrmΛmm−1Λmr][xmxr]=−[bmmbmr]=−[bmmbmr−ΛrmΛmm−1bmm]
我们记 Λ p = Λ r r − Λ r m Λ m m − 1 Λ m r \bm{\Lambda}_p=\bm{\Lambda}_{rr}-\bm{\Lambda}_{rm}\bm{\Lambda}_{mm}^{-1}\bm{\Lambda}_{mr} Λp=Λrr−ΛrmΛmm−1Λmr, b p = b m r − Λ r m Λ m m − 1 b m m \bm{b}_p=\bm{b}_{mr}-\bm{\Lambda}_{rm}\bm{\Lambda}_{mm}^{-1}\bm{b}_{mm} bp=bmr−ΛrmΛmm−1bmm,称之为先验信息矩阵和先验残差。
在新的变量添加到窗口后,新构建最小二乘问题的信息矩阵和残差变为(下标a表示新添加变量):
Λ = Λ p + J a T Σ a − 1 J a b = b p + J a T Σ a − 1 r \begin{aligned} \bm{\Lambda}&=\bm{\Lambda}_p+\bm{J}_a^T\bm{\Sigma}^{-1}_a\bm{J}_a\\ \bm{b}&=\bm{b}_p+\bm{J}^T_a\bm{\Sigma}^{-1}_a\bm{r} \end{aligned} Λb=Λp+JaTΣa−1Ja=bp+JaTΣa−1r
为了更好的理解这一过程,我们继续看上面的例子。假设在从滑窗中删除了旧变量 x 1 x_1 x1后,接下来我们需要向滑窗中添加新的变量 x 7 x_7 x7,那么新的信息矩阵构成过程如下图所示。我们发现,在左上角 x 2 x_2 x2对应的子矩阵是由第 k k k步求得的先验信息矩阵(蓝色)和第 k + 1 k+1 k+1步求得的信息矩阵(粉色)叠加而来的,而这个信息矩阵在求解的时候,其线性化点是不同的,而这会使得求解的零空间发生变化。
 为解决这一问题,在进行滑窗算法时,我们需要使用First Estimated Jacobian(FEJ)算法,将两次求解Jacobian矩阵时的线性化点保持一致。
为解决这一问题,在进行滑窗算法时,我们需要使用First Estimated Jacobian(FEJ)算法,将两次求解Jacobian矩阵时的线性化点保持一致。