红楼梦人物出场次数统计及人物出场词云
《红楼梦》是一篇鸿篇巨制,里面出现了几百个各具特色的人物。每次读这本经典作品都会想一个问题,全书这些人物谁出场最多呢?我们来用Python进行回答。
import jieba
f=open("红楼梦.txt","r",encoding="utf-8")
txt=f.read()
f.close()
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(15):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
输出排序前15的单词,输出结果如下:

与英文词频统计类似,需要排除一些与人名无关的词汇,比如“什么”“一个”等等。进一步完善代码。
需要增加排除词库excludes
import jieba
excludes={"什么","一个","我们","那里","你们","如今",\
"说道","知道","老太太","起来","姑娘",\
"这里","出来","他们","众人","自己","一面",\
"太太","只见","怎么","奶奶","两个","没有",\
"不是","不知","这个","听见"}
f=open("红楼梦.txt","r",encoding="utf-8")
txt=f.read()
f.close()
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
for word in excludes:
del(counts[word])
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(5):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
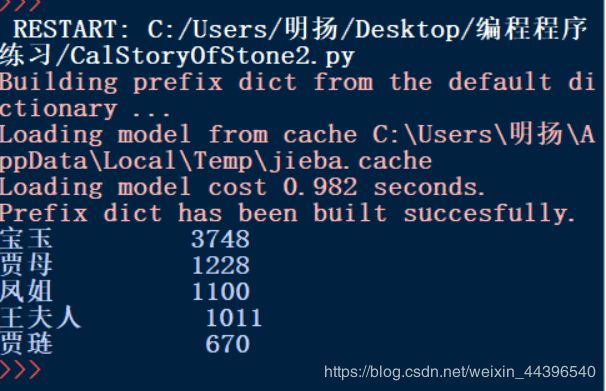
输出结果如下:
人物出场词云
要想使以上输出结果更加生动直观,可以利用wordcloud库,将人物出场统计以词云方式展现出来。
- 首先使用jieba库对“红楼梦.txt”进行分词,分词后的结果以空格重新拼接为文本,并由wordcloud进行处理。
- 无关词汇的排除可以借助wordcloud中的stopwords参数完成。
import jieba
from wordcloud import WordCloud
excludes={"什么","一个","我们","那里","你们","如今",\
"说道","知道","老太太","起来","姑娘",\
"这里","出来","他们","众人","自己","一面",\
"太太","只见","怎么","奶奶","两个","没有",\
"不是","不知","这个","听见"}
f=open("红楼梦.txt","r",encoding="utf-8")
txt=f.read()
f.close()
words=jieba.lcut(txt)
newtxt=" ".join(words)
wordcloud=WordCloud(background_color="white",\
width=800,\
height=600,\
font_path="C:\Windows\Fonts\STHUPO.TTF",\
max_words=200,\
max_font_size=80,\
stopwords=excludes,\
).generate(newtxt)
wordcloud.to_file("石头记词云.png")
输出结果如下图: