python爬虫数据采集使用的三种匹配方式:正则re,xpath,beautifulsoup4
一般情况下三种方式都是可以匹配到结果的,只是复杂程度不一致,根据情况进行选择re/xpath/bs4
- 先进行简单的比较:
- 一、正则re的使用
- 二、lxml
- 三、bs4 的使用
先进行简单的比较:
| 抓取工具 | 速度 | 使用难度 | 安装 |
|---|---|---|---|
| 正则re | 最快 | 一般 | 内置 |
| xpath | 快 | 简单 | 简单 |
| bs4 | 慢 | 最简单 | 简单 |
注:xpath 一般与lxml 一起使用
简单来说:
正则re 是通过html str进行匹配的
xpath 是通过html节点 进行匹配
bs4 则通过css的选择器进行匹配
一、正则re的使用
re的方法
pattern = re.compile('^\d+$')
str = 'abc123'
# 表示重头匹配 result有可能报错
result = pattern.match(str)
# 表示任意位置匹配
result = pattern.match(str)
# 爬虫最常用的的findall
result = pattern.findall(str)
# sub 替换
one = 'chuan_zhi_hei_ma'
sub_pattern = re.compile('_')
result = sub_pattern.sub('', one)
# 调换顺序
two = "hello world,fsd,;fds;gds,A B"
sub_pattern = re.compile('(\w+) (\w+)')
result = sub_pattern.sub(r'\2 \1', two)
# split 分割
thre = "a,b,,,,c;;;d ,f e"
split_pattern = re.compile('[,; ]+')
result = split_pattern.split(thre)
# 汉字--unicode字符 [u4e00-u9fa5]
china_str = "小明老王是一家人is not"
china_pattern = re.compile('[\u4e00-\u9fa5]+')
china_pattern = re.compile('[^\u4e00-\u9fa5]+')
result = china_pattern.findall(china_str)
re 正则findall中的参数
# 1. . 点 匹配任意字符 除了\n ; 但是在DOTALL 可以匹配
one = """
assffddsfb
MMMMMMMMMM
NNNNNNNNNB
"""
# 1. 正则表达式
pattern = re.compile('a(.*)b')
# 可以匹配的\n 12行13行等价
pattern = re.compile('a(.*)b', re.DOTALL)
pattern = re.compile('a(.*)b', re.S)
# 可以匹配 不区分大小写
pattern = re.compile('a(.*)b', re.S | re.IGNORECASE)
pattern = re.compile('a(.*)b', re.S | re.I)
# 2. 调用findall---list
result = pattern.findall(one)
注:在python3中 匹配\w 会匹配到中文字符
所以经常使用的
pattern = re.compile(r’[1-9a-zA-Z_]’)
二、lxml
- lxml库的安装: pip install lxml
- lxml的导包:from lxml import etree;
- lxml转换解析类型的方法:etree.HTML(text)
- lxml解析数据的方法:data.xpath("//div/text()")
- 需要注意lxml提取完毕数据的数据类型都是列表类型
- 如果数据比较复杂:先提取大节点, 在遍历小节点操作
- 把转化后的element对象转化为字符串,返回bytes类型结果 etree.tostring(element)
返回的是element对象,可以继续使用xpath方法,对此我们可以在后面的数据提取过程中:先根据某个标签进行分组,分组之后再进行数据的提取
发现结果是一个element对象,这个对象能够继续使用xpath方法:要注意的是 xpath的语法就变成了在此element的路径进行下一步的匹配 使用 ./ (点斜杠) 表示当前路径
下面是:xpath的语法
xpath的概述XPath (XML Path Language),解析查找提取信息的语言
xml是和服务器交互的数据格式和json的作用一致
html是浏览器解析标签数据显示给用户
xpath的节点关系:根节点,子节点,父节点,兄弟节点,子节点,后代节点
xpath的重点语法获取任意节点://
xpath的重点语法根据属性获取节点:标签[@属性 = ‘值’]
xpath的获取节点属性值:@属性值
xpath的获取节点文本值:text()
xpath的使用方法: 如果没有取到想要的结果,再去看他的父元素,一直往上找。



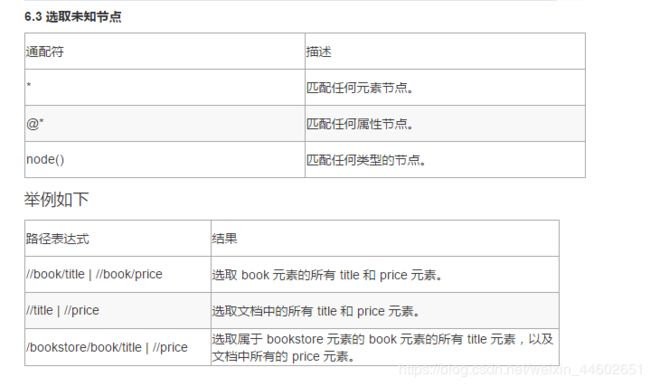
三、bs4 的使用
- 使用 pip 安装即可: pip install beautifulsoup4
- beautifulsoup导包: from bs4 import BeautifulSoup
- find 方法返回一个解析完毕的对象
- findall 方法返回的是解析列表list
- select 方法返回的是解析列表list
- 获取属性的方法: get(‘属性名字’)
- 和获取文本的方法: get_text()
需要知道使用bs4时,需要指明解析器 一般是lxml
#创建 Beautiful Soup 对象
# soup = BeautifulSoup(html)
#打开本地 HTML 文件的方式来创建对象
#soup = BeautifulSoup(open('index.html'))
soup = BeautifulSoup(html_str, 'lxml') # 常用的方式
#格式化输出 soup 对象的内容
result = soup.prettify()
常用的方法如下
2.1
find_all(name, attrs, recursive, text, **kwargs)
2.3 CSS选择器
(1)通过标签选择器查找
print soup.select('title')
#[The Dormouse's story ]
(2)通过类选择器查找
print soup.select('.sister')
#[, Lacie, Tillie]
(3)通过 id 选择器查找
print soup.select('#link1')
#[]
(4)层级选择器 查找
print soup.select('p #link1')
#[]
(5)通过属性选择器查找
print soup.select('a[href="http://example.com/elsie"]')
#[]
(6) 获取文本内容 get_text()
soup = BeautifulSoup(html, 'lxml')
print type(soup.select('title'))
print soup.select('title')[0].get_text()
for title in soup.select('title'):
print title.get_text()
(7) 获取属性 get('属性的名字')
soup = BeautifulSoup(html, 'lxml')
print type(soup.select('a'))
print soup.select('a')[0].get('href')
举例如下
# pip install beautifulsoup4
from bs4 import BeautifulSoup
import re
if __name__ == '__main__':
html_str = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
# 1. 转类型
soup = BeautifulSoup(html_str, 'lxml')
# 2.3 select 选择器--list
# 标签选择器
# 类选择器
# ID选择器
# 层级选择器 后代选择器
# 组选择器
# 属性选择器
result = soup.select('a')
result = soup.select('.sister')
result = soup.select('head title')
result = soup.select('#link3,#link1')
result = soup.select('p[name="dromouse"]')
result = soup.select('#link3')
# 标签包裹的内容
# result = result[0].get_text()
# 标签的属性
result = result[0].get('href')
print(result)
# 2.解析数据
# 2.1 find--获取符合条件 第一个
result = soup.find()
result = soup.find(attrs={
"id": "link2"
})
pattern = re.compile('^b')
result = soup.find(pattern)
result = soup.find(text="...")
# 2.2 find_all ---list
result = soup.find_all('a')