python爬虫入门 ✦ 下载QQ音乐
此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
项目案例目标:通过爬虫获取QQ音乐的数据从而进行下载。
秉承着拿来主义,各位直接复制黏贴即可使用。
代码如题,支持输入歌手或歌曲来查询,从而进行下载歌曲。
里面有两个版本,相信有点基础没有基础的看过后都可以理解并运用了。
写在前面: 整篇文章主要是围绕获取 songmid 和 vkey。整个下来可能会有些啰嗦 + 繁琐 + 冗余,但是重点就是要获取 songmid和vkey。
整篇文章看下来,包懂!!包懂!!包懂!!
爬虫的四个步骤:1.请求网页 2.获取网页响应 3.解析网页 4.保存数据
1.该程序由逆向分析开始,分析了音乐下载链接后,得出下载链接的常量与变量
2.但是爬虫代码的实现需从请求网页开始!!
3.开始寻找变量,最终确定变量为 songmid 和 vkey
4.自己动手操作一番,你也可以成功操作出来的哦
-
1.分析网页
- 首先,我们需要QQ音乐的url,即网址 QQ音乐。
先去QQ音乐的首页看看,了解哪些信息是我们所需要的。
- 在首页的搜索框输入张学友,然后点击歌曲,进入播放页面

- 在播放页面,因为音乐是媒体文件,所以这里打开 Network-Media,稍等音乐文件加载完成后,可以看到一个比较大的文件,大的不正常,令人怀疑就是音乐的源文件。不要犹豫,直接点击它

- 可以看到有一个很长的Request URL,并且它的请求方式是get的,将这个url复制去浏览器打开看一看,到底是何方神圣。
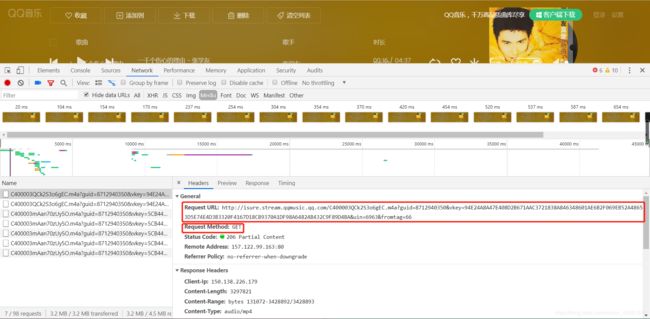
- perfect,这个链接就是我们需要的音乐下载链接。接下来我们分析几个歌曲的下载链接,尝试着找一下他们的规律。
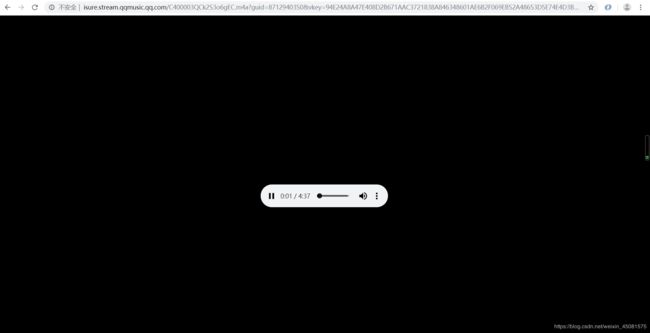
- 这里选择了另外一首音乐,将他的Request URL提取出来具体去分析一下。

- 首先,我们需要QQ音乐的url,即网址 QQ音乐。
-
http://isure.stream.qqmusic.qq.com/C400003QCk2S3o6gEC.m4a?guid=8712940350&vkey=94E24A8A47E408D2B671AAC3721838A846348601AE6B2F069EB52A48653D5E74E4D3B3320F4167D18CB9370A1DF98A64824B432C9F89D4BA&uin=6963&fromtag=66
-
http://isure.stream.qqmusic.qq.com/C4000033oxAn0LGrQy.m4a?guid=8712940350&vkey=75E481864E323B4C67BF70A41BE892C0E8D327673E4D8AED326A927CC219E291BFFDE221AD1413262D3F5FA540B508AE649C586F1985F98C&uin=6963&fromtag=66
- 这两个音乐下载链接,直接用requests请求下载就可以了。
- 本文完。
- 开个玩笑哈
- 分析上面两个音乐的下载链接,可以观察得到 C400003QCk2S3o6gEC.m4a和vkey的值这两部分是不一样的,其他的部分都一样。所以接下来就是去找出这两个下载链接的组成部分。
-
2.分析请求
- 经过大半个小时的寻找网页,终于在这个页面找到了歌曲的 songMID,仔细观看下面两张图片,这个songMID在前面加上C400就是上面的需要寻找的参数!!!接下来我们去寻找另外一个vkey。

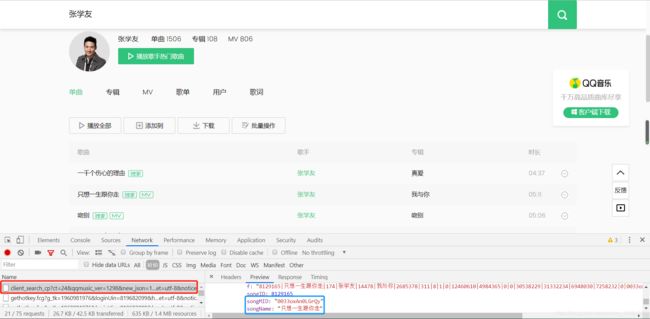
- 再次通过将近一个小时的查找,找到了以下的这个图,通过多个歌曲的验证,终于终于确认了这个使我找到眼睛都快干了的vkey!!!
- 从搜索页面一直到播放页面,怎么找到找不出来。最后想一下有可能是异步加载的,clear了加载的数据,然后点击音乐播放,最后搜索关键字就出来了。但是关键字搜索出来的还是一大堆,这个还得自己慢慢查看。。
- 谨记!!vkey是在音乐播放页面搜索出来的。

- 经过大半个小时的寻找网页,终于在这个页面找到了歌曲的 songMID,仔细观看下面两张图片,这个songMID在前面加上C400就是上面的需要寻找的参数!!!接下来我们去寻找另外一个vkey。
-
3.请求代码
-
现在我们知道了音乐下载链接的构成,知道了下载链接的数据如何去获取,那接下来就是我们去获取请求页面的时候了。待会我们就是需要从这个url去获取songmid。说三遍!!!
-
https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=66745724577374381&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%BC%A0%E5%AD%A6%E5%8F%8B&g_tk=1960981976&loginUin=(你的QQ号)&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0
-
上面这个是张学友的搜索页面url,通过分析,测试。最终得出了精简版的url。待会我们就是需要从这个url去获取songmid。说三遍!!!
-
https://c.y.qq.com/soso/fcgi-bin/client_search_cp?&p=1&n=10&w=张学友&format=json
-
再进一步分析,得知p=1的1为搜索的页面数,w=张学友的张学友为搜索的歌手或歌曲。待会我们就是需要从这个url去获取songmid。说三遍!!!
-
下面这串代码是音乐下载链接需要的 songmid 的代码,将请求的页面和搜索的歌曲或歌手设为传参,方便下载不同的音乐
-
*获取songmid,下载链接必须之一
-
# 请求songmid
import json,requests
name = input("输入你要下载的歌曲或歌手名字:")
num = input(str("输入下载的数量,默认为1:"))
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?&p=1&n=%s&w=%s&format=json' % (num, name)
result = requests.get(url)
# 将请求到的网页转换为字典
html = result.text
js = json.loads(html)
# 定位到具体的songmid位置(可翻看上面的图)
songlist = js['data']['song']['list']
all_songmid = []
for song in songlist:
name = song['songname']
songmid = song['songmid']
all_songmid.append((name, songmid))
print(all_songmid)
-
现在我们去获取音乐下载链接的第二个关键参数,vkey。待会我们就是需要从这个url去获取vkey。说三遍!!!
-
https://u.y.qq.com/cgi-bin/musicu.fcg?-=getplaysongvkey7569735704205274&g_tk=1960981976&loginUin=(你的QQ号)&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0&data={“req”:{“module”:“CDN.SrfCdnDispatchServer”,“method”:“GetCdnDispatch”,“param”:{“guid”:“8712940350”,“calltype”:0,“userip”:""}},“req_0”:{“module”:“vkey.GetVkeyServer”,“method”:“CgiGetVkey”,“param”:{“guid”:“8712940350”,“songmid”:[“0033oxAn0LGrQy”],“songtype”:[0],“uin”:"(你的QQ号)",“loginflag”:1,“platform”:“20”}},“comm”:{“uin”(你的QQ号),“format”:“json”,“ct”:24,“cv”:0}}
- 上面这个是音乐播放的获取vkey的url,通过分析,测试。最终得出了精简版的url。待会我们就是需要从这个url去获取vkey。说三遍!!!
-
https://u.y.qq.com/cgi-bin/musicu.fcg?&data={“req”:{“param”:{“guid”:“123456”}},“req_0”:{“module”:“vkey.GetVkeyServer”,“method”:“CgiGetVkey”,“param”:{“guid”:“123456”,“songmid”:[“0033oxAn0LGrQy”],“uin”:“123456”}},“comm”:{“uin”:123456}}
- 上面的这个就是获取vkey的url,主要传输几个guid,uin,songmid。带电脑上播放音乐就需要你登录,所以guid和uin这两个也就会有了。也可以随便填写,不会影响结果,但不能不填写。songmid就需要填写正确的,不然就无法获取到歌曲的vkey。
-
获取vkey,下载链接必须之二
# 获取vkey的代码
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?&data={"req":{"param":{"guid":"1"}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"1","songmid":["003QCk2S3o6gEC"],"uin":"12"}},"comm":{"uin":12}}'
html = requests.get(url)
# # 请求网页状态为200,则进行编码和转换为字典
if html.status_code == 200:
html.encoding = 'utf-8'
html = html.text
html = json.loads(html)
song_url = []
# 获取vkey的位置
vkey = html['req_0']['data']['midurlinfo'][0]['purl']
url_head = 'http://ws.stream.qqmusic.qq.com/'
Final_url = url_head + vkey
song_url.append(Final_url)
print("请耐心等待。。")
print(song_url)
-
4.完整代码
# author sunrisecai
# 1.程序分析音乐下载链接开始,得出下载链接的常量与变量
# 2.开始寻找变量,最终确定变量为 songmid 和 vkey
# 3.自己动手操作一番,你也可以成功操作出来的哦
import json
import time
import requests
class QQ_Music_Spider():
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64;Trident/7.0;rv:11.0) like Gecko'}
self.all_songmid = [] # 存放所有songmid
self.all_download_link = [] # 存放所有音乐下载链接
def get_page(self, url, headers):
html = requests.get(url, headers=self.headers, verify=False)
# 如果请求网页正常,则继续后面的操作
if html.status_code == 200:
html.encoding = 'utf-8'
return html
return None
def music_number(self):
try:
print("==请输入1-60的数字,不在此范围或不输入默认为1==")
num = int(input("请输入下载歌曲的数目(最大为60,回车默认为1):"))
if 0 < int(num) < 60:
return num
except:
num = 1
return num
def get_songmid(self, num, name):
# 这个url是搜索页
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?&p=1&n=%s&w=%s&format=json' % (num, name)
res = self.get_page(url, headers=self.headers).text
html = json.loads(res)
for i in range(len(html['data']['song']['list'])):
songmid = html['data']['song']['list'][i]['songmid']
songname = html['data']['song']['list'][i]['songname']
self.all_songmid.append((songname, songmid))
def get_mid_vkey(self):
# 遍历所有的songmid,拼凑成获取vkey的url
for mid in self.all_songmid:
name = mid[0]
songmid = mid[1]
# 这个url是获取vkey的url,取结果拼凑成music下载链接
vkey_url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?&data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"8712940350","songmid":["%s"],"uin":"123"}},"comm":{"uin":123}}' % songmid
res = self.get_page(vkey_url, headers=self.headers)
res.encoding = 'utf-8'
result = res.text
html = json.loads(result)
vkey = html['req_0']['data']['midurlinfo'][0]['purl']
# 拼凑music下载链接
music_link = 'http://ws.stream.qqmusic.qq.com/' + vkey
# 将music下载链接添加到列表
self.all_download_link.append((name, music_link))
def download(self):
# 遍历music下载链接列表
for url in self.all_download_link:
music_name = url[0]
url = url[1]
time.sleep(1)
# 请求网页
res = self.get_page(url, headers=self.headers)
res.encoding = 'utf-8'
result = res.content
# 开始下载,二进制格式
with open('%s.mp3' % music_name, 'wb') as f:
f.write(result)
print('%s下载成功.mp3' % music_name)
def main(self):
num = self.music_number()
name = input("请输入歌手或歌曲名字:")
self.get_songmid(num, name)
self.get_mid_vkey()
self.download()
# 执行主函数
if __name__ == '__main__':
spider = QQ_Music_Spider()
spider.main()
写了这篇文章希望能够帮到有需要的小伙伴。手动复制黏贴即可使用哦。有什么疑问欢迎一起交流,也恳请大家指正我的错误之处哦。
好了,本次的分享到这里结束。
有任何疑问欢迎在下方留言哦。