每天30分钟 一起来学习爬虫——day8(requests库的cookie,ssl认证和代理,实例:人人网模拟登录)
文章目录
- 代理
- ssl 认证
- cookie
- auth认证
代理
代理的相关理论在前面已将说过了,这次直接看用requests 来设置代理
import requests
url = 'https://www.baidu.com/s?wd=ip&ie=UTF-8'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
proxies = {
'http': '117.88.176.252 :3000',
'https': '117.88.176.252:3000',
}
r = requests.get(url, headers=headers, proxies=proxies)
print(r.status_code)
如果返回的200 就说明成功,但是下次访问的时候可能就不成功了,大家如果实验的话,先去 西刺代理 找一个最新的,好用一点
ssl 认证
HTTPs CA证书
没有ssl证书的网站是可以访问的,但是一些主流浏览器打开没有ssl证书的网站也就是类型网站会提示“不安全”等信息。
相信大家都见过这样的界面
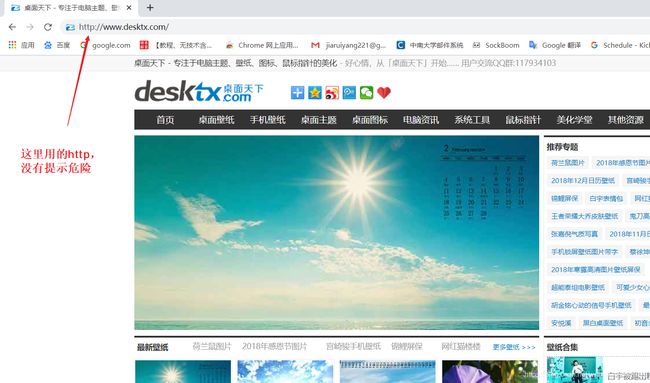
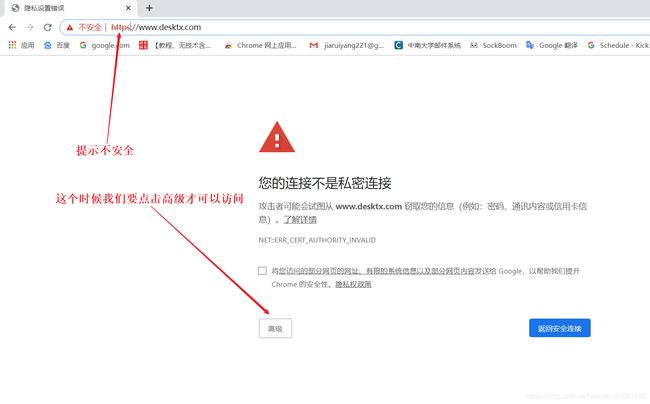
ssl认证大体上如下:
-
服务器向CA机构获取证书(假设这个证书伪造不了),当浏览器首次请求服务器的时候,服务器返回证书给浏览器。(证书包含:公钥+申请者与颁发者的相关信息+签名)
-
浏览器得到证书后,开始验证证书的相关信息,证书有效(没过期等)。(验证过程,比较复杂,详见上文)。
-
验证完证书后,如果证书有效,客户端是生成一个随机数,然后用证书中的公钥进行加密,加密后,发送给服务器,服务器用私钥进行解密,得到随机数。之后双方便开始用该随机数作为钥匙,对要传递的数据进行加密、解密。
更多关于ssl的看这
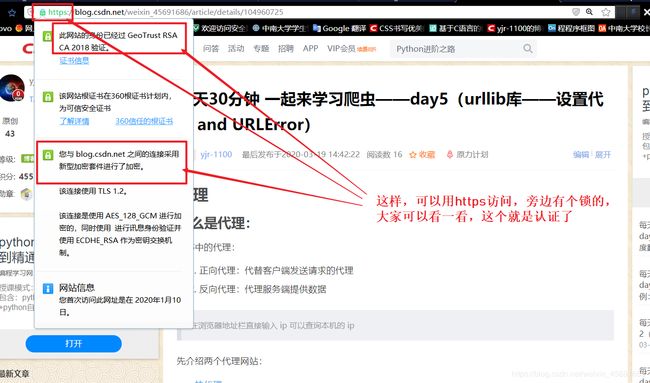
如遇到了没有ssl认证的情况,用户如果不点 高级 那用户也看不到,我们在第一天就说过,爬虫只能爬取用户能访问的页面,现在用户都看不到,爬虫也爬不到了吖
不管怎么样,先按套路爬一下
import requests
url = 'https://www.desktx.com'# 这个是提示危险的网页
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
data= response.content
with open ('ssl_requests.html','wb') as f:
f.write(data)
# 为了更清楚的看到,我把它写入文件中
尴尬了,直接报错,
![]() 错误粘出来看看
错误粘出来看看requests.exceptions.SSLError: HTTPSConnectionPool(host='www.desktx.com', port=443)
压根就连不上啊(哭)
因为 HTTPs 是有第三方的 CA 证书认证的,但是,这个网站,虽然是https, 但没有第三方的 CA 证书,是自己的证书
解决方法 : 直接告诉 web 忽略证书
import requests
url = 'https://www.desktx.com'# 这个是提示危险的网页
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
response = requests.get(url=url,headers=headers,verify=False)
data= response.content
with open ('ssl_requests.html','wb') as f:
f.write(data)
直接在请求时 加上verify=False 就可以了吖
还有一种方法是全局取消证书验证
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
一般用第一种就好了呢~~~
cookie
还记得之前使用 urlllib 库,人人网的模拟登录吗,回忆一下,之前我们有两种方法
- 登录后抓包,直接吧cookie 写在请求头中
- 登录时抓包,获取到提交的表单数据(formdata),创建一个
cookiejar的对象,并通过cookiejar使用HTTPCookieProcessor创建一个handler处理器,之后创建我们自己的openner来发送请求。
这次我们用requests 来实现一下
我们知道,cookie 是有关对话的一个问题,所以我们要先创建一个会话,之后,所有的请求都通过会话发送。
这里就不再演示抓包分析了,于之前的实例一样,忘了的可以 点这里看看
这里就直接看代码吧,
import requests
# 如果碰到会话相关问题,要先创建一个会话
s = requests.Session()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
formdata = {
'rkey': '', # 这里是我们抓包得到的数据,填进去
'password': '',# 这里是我们抓包得到的数据,填进去
'origURL': 'http://www.renren.com/home',
'key_id': '1',
'icode' : '',
'f' : 'http%3A%2F%2Fwww.renren.com%2F823000881',
'email' : ' ', # 这里是我们抓包得到的数据,填进去
'domain': 'renren.com',
'captcha_type': 'web_login',
}
post_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2020159150'
r = s.post(url=post_url, headers=headers, data=formdata)
# 用刚才的会话发送请求
# 这下s里面就保存了cookie,我们这时候访问个人主页就可以成功了
get_url = 'http://sc.renren.com/scores/mycalendar'
ret = s.get(url=get_url, headers=headers)
# with open('renren_r.html', 'wb') as f:
# f.write(ret.text)
print(ret.text)
# 这样用s访问,而不是request 就可以登录成功
同样的,如果使用第一种方法,我们需要做的,只是给get请求传入cookie 参数
import requests
# 直接传入 cookie 的方法
cookie = '' # 这里填自己抓包得到的cookie
# 这个是cookie字符串,但我们要传入的是字典
# 我们先创建一个字典
cookie_dict = {}
# 我们手动转换一下,先从 封号 拆开
cookie_list = cookie.split(';')
for cookie in cookie_list:
# 再从 '=' 拆开
cookie_dict[cookie.split('=')[0]] = cookie.split('=')[1]
# 我们也可以写字典推导式,来生成字典
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
url = ''# 这个是自己要访问的url,
r = requests.get(url=url, headers=headers, cookies=cookie_dict)
with open('renren_r.html', 'wb') as f:
f.write(r.content)
auth认证
这个没有实例演示,就是能简单说一下,如果有公司内网的话,可以试试
import requests
auth = (username, pwd) # 这个是一个元组,访问内网的时候,传进去就好了
response = requests.get(url, headers=headers, auth=auth)
# 这样就可以了
到这里我们requests库就大概学完了,但是大家有没有发现,我们目前都是保存的网页,这并没有什么实际效果,所以接下来我们会学习对爬取的数据的解析,明天 先学习 正则表达式解析
我又来要赞了,如果觉得可以学到些什么的话,点个赞再走吧,欢迎各位路过的大佬评论指正