Elastic-Job学习笔记-定时任务框架的搭建
官方文档:http://elasticjob.io/docs/elastic-job-lite/00-overview/
elastic-job学习(网易乐得技术团队,具体说明) http://tech.lede.com/2017/06/23/rd/server/elasticJob/
1.简介
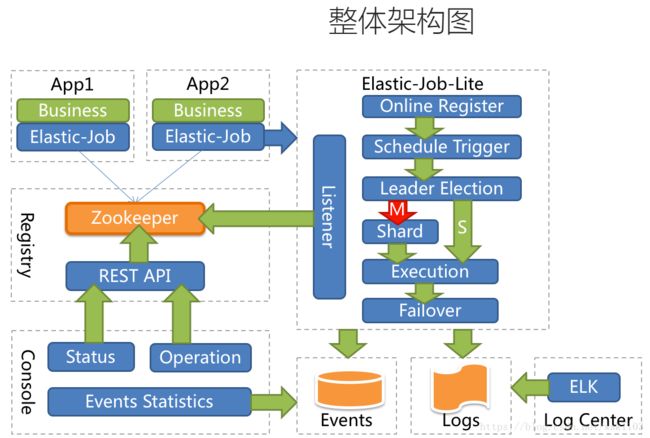
Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供最轻量级的分布式任务的协调服务,外部依赖仅Zookeeper。
使用的时候,只需要在项目中引入相应的maven配置即可。
2.核心理念
2.1 分布式调度
Elastic-Job-Lite并无作业调度中心节点,而是基于部署作业框架的程序在到达相应时间点时各自触发调度。
注册中心仅用于作业注册和监控信息存储。而主作业节点仅用于处理分片和清理等功能。
2.2 作业高可用
Elastic-Job-Lite提供最安全的方式执行作业。将分片总数设置为1,并使用多于1台的服务器执行作业,作业将会以1主n从的方式执行。
一旦执行作业的服务器崩溃,等待执行的服务器将会在下次作业启动时替补执行。开启失效转移功能效果更好,可以保证在本次作业执行时崩溃,备机立即启动替补执行。
2.3 最大限度利用资源
Elastic-Job-Lite也提供最灵活的方式,最大限度的提高执行作业的吞吐量。将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项。
例如:3台服务器,分成10片,则分片项分配结果为服务器A=0,1,2;服务器B=3,4,5;服务器C=6,7,8,9。 如果服务器C崩溃,则分片项分配结果为服务器A=0,1,2,3,4;服务器B=5,6,7,8,9。在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量。
3.整体架构图
4.主要功能

5.作业启动流程图

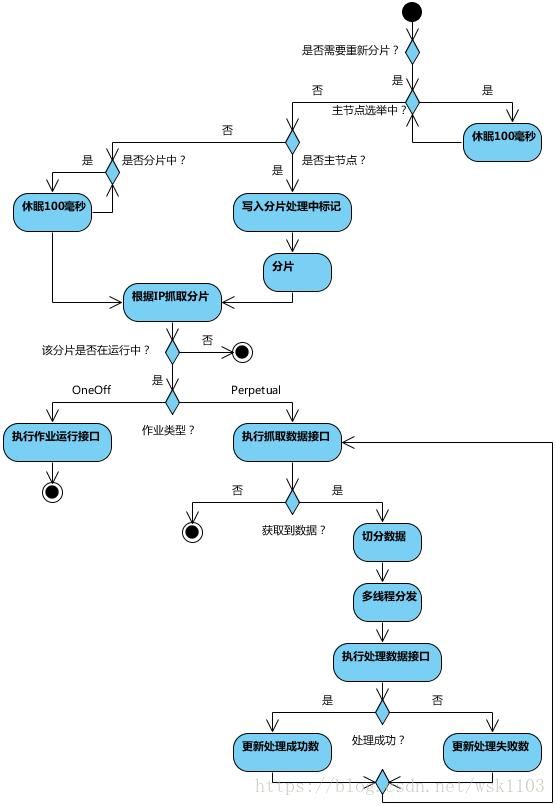
(1)第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
(2)某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态。
(3)主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
(4)定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
(5)通过(4)可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
(6)每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
(7)实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
6.作业执行流程图
7.环境说明
Java 1.7 +
zookeeper 3.4.6 +
maven 3.0.4 +
8.引入MAVEN
elastic-job-lite-core
com.dangdang
${elastic-job.version}
elastic-job-common-core
com.dangdang
${elastic-job.version}
curator-framework
org.apache.curator
2.10.0
curator-recipes
org.apache.curator
2.10.0
curator-framework
org.apache.curator
elastic-job-lite-spring
com.dangdang
${elastic-job.version}
9.作用开发
新建一个类,继承 SimpleJob或者Dataflow
SimpleJob
意为简单实现,未经任何封装的类型。需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,此方法将定时执行。与Quartz原生接口相似,但提供了弹性扩缩容和分片等功能。
Dataflow
Dataflow类型用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。
可通过DataflowJobConfiguration配置是否流式处理。
流式处理数据只有fetchData方法的返回值为null或集合长度为空时,作业才停止抓取,否则作业将一直运行下去; 非流式处理数据则只会在每次作业执行过程中执行一次fetchData方法和processData方法,随即完成本次作业。
如果采用流式作业处理方式,建议processData处理数据后更新其状态,避免fetchData再次抓取到,从而使得作业永不停止。 流式数据处理参照TbSchedule设计,适用于不间歇的数据处理。
在com.wsk.timer.job中创建相应的类。
eg。
import com.alibaba.fastjson.JSON;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Date;
/**
* @DESCRIPTION : 这是一个测试类
* @AUTHOR : WuShukai
* @TIME : 2018/9/18 15:42
*/
public class TestJob implements SimpleJob {
private static final Logger log = LoggerFactory.getLogger(TestJob.class);
@Override
public void execute(ShardingContext shardingContext) {
log.info(JSON.toJSONString(shardingContext, true));
for (int i = 0; i < 5; i++) {
System.out.println("testJob=====>go: " + i +" , " + new Date());
try {
Thread.sleep(1000 * 4);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
10.作业启动配置(目前使用spring配置启动)
corn 表达式网站 http://cron.qqe2.com/
在spring-job.xml中声明job,并配置。
11.注册中心配置
11.1 reg:zookeeper命名空间属性详细说明
| 属性名 | 类型 | 是否必填 | 缺省值 | 描述 |
|---|---|---|---|---|
| id | String | 是 | 注册中心在Spring容器中的主键 | |
| server-lists | String | 是 | 连接Zookeeper服务器的列表,包括IP地址和端口号,多个地址用逗号分隔,如: host1:2181,host2:2181 | |
| namespace | String | 是 | Zookeeper的命名空间 | |
| base-sleep-time-milliseconds | int | 否 | 1000 | 等待重试的间隔时间的初始值,单位:毫秒, |
| max-sleep-time-milliseconds | int | 否 | 3000 | 等待重试的间隔时间的最大值,单位:毫秒 |
| max-retries | int | 否 | 3 | 最大重试次数 |
| session-timeout-milliseconds | int | 否 | 60000 | 会话超时时间,单位:毫秒, |
| connection-timeout-milliseconds | int | 否 | 15000 | 连接超时时间 |
| digest | String | 否 | 连接Zookeeper的权限令牌,缺省为不需要权限验证 |
11.2 job:simple命名空间属性详细说明
| 属性名 | 类型 | 是否必填 | 缺省值 | 描述 |
|---|---|---|---|---|
| id | String | 是 | 作业名称 | |
| class | String | 否 | 作业实现类,需实现ElasticJob接口 | |
| job-ref | String | 否 | 作业关联的beanId,该配置优先级大于class属性配置 | |
| registry-center-ref | String | 是 | 注册中心Bean的引用,需引用reg:zookeeper的声明 | |
| cron | String | 是 | cron表达式,用于控制作业触发时间 | |
| sharding-total-count | int | 是 | 作业分片总数 | |
| sharding-item-parameters String | 否 | 分片序列号和参数用等号分隔,多个键值对用逗号分隔,分片序列号从0开始,不可大于或等于作业分片总数,如:,0=a,1=b,2=c | ||
| job-instance-id | String | 否 | defaultInstance | 作业实例主键,同IP可运行实例主键不同, 但名称相同的多个作业实例 |
| job-parameter | String | 否 | 作业自定义参数,作业自定义参数,可通过传递该参数为作业调度的业务方法传参,用于实现带参数的作业,例:每次获取的数据量、作业实例从数据库读取的主键等 | |
| monitor-execution | boolean | 否 | true | 监控作业运行时状态,每次作业执行时间和间隔时间均非常短的情况,建议不监控作业运行时状态以提升效率。因为是瞬时状态,所以无必要监控。请用户自行增加数据堆积监控。并且不能保证数据重复选取,应在作业中实现幂等性。每次作业执行时间和间隔时间均较长的情况,建议监控作业运行时状态,可保证数据不会重复选取。 |
| monitor-port | int | 否 | -1 | 作业监控端口,建议配置作业监控端口, 方便开发者dump作业信息。,使用方法: echo “dump” |
| max-time-diff-seconds | int | 否 | -1 | 最大允许的本机与注册中心的时间误差秒数,如果时间误差超过配置秒数则作业启动时将抛异常,配置为-1表示不校验时间误差 |
| failover | boolean | 否 | false | 是否开启失效转移 |
| misfire | boolean | 否 | true | 是否开启错过任务重新执行 |
| job-sharding-strategy-class | String | 否 | 作业分片策略实现类全路径,默认使用平均分配策略,详情参见:作业分片策略 | |
| description | String | 否 | 作业描述信息 | |
| disabled | boolean | 否 | false | 作业是否禁止启动,可用于部署作业时,先禁止启动,部署结束后统一启动 |
| overwrite | boolean | 否 | false | 本地配置是否可覆盖注册中心配置,如果可覆盖,每次启动作业都以本地配置为准 |
| job-exception-handler | String | 否 | 扩展异常处理类 | |
| executor-service-handler | String | 否 | 扩展作业处理线程池类 | |
| reconcile-interval-minutes | int | 否 | 10 | 修复作业服务器不一致状态服务调度间隔时间,配置为小于1的任意值表示不执行修复,单位:分钟 |
| event-trace-rdb-data-source | String | 否 | 作业事件追踪的数据源Bean引用 |
11.3 job:dataflow命名空间属性详细说明
| 属性名 | 类型 | 是否必填 | 缺省值 | 描述 |
|---|---|---|---|---|
| streaming-process | boolean | 否 | false | 是否流式处理数据,如果流式处理数据, 则fetchData不返回空结果将持续执行作业,如果非流式处理数据, 则处理数据完成后作业结束 |
12.部署指南
12.1 应用部署
a. 启动Elastic-Job-Lite指定注册中心的Zookeeper。
b. 运行包含Elastic-Job-Lite和业务代码的jar文件。不限与jar或war的启动方式。
12.2 运维平台部署(可选)
a. 编译job-console.tar.gz,可通过mvn install编译获取。
b. 解压缩job-console.tar.gz并执行bin\start.sh。
c. 打开浏览器访问http://localhost:8899/即可访问控制台。8899为默认端口号,可通过启动脚本输入-p自定义端口号。
12.3 运维平台功能
a. 登录安全控制
b. 注册中心、事件追踪数据源管理
c. 快捷修改作业设置
d. 作业和服务器维度状态查看
e. 操作作业禁用\启用、停止和删除等生命周期
f. 事件追踪查询