scrapy爬取京东前后一星期图书价格
scrapy框架
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。;框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
思路分析
大数据可视化需要对不同行业不同种类的数据分析,那么python爬虫与大数据就更加形影不离,本次是对京东图书前后一星期价格进行爬取分析。
1、想要爬取某个网站第一步必须进行该网页数据分析,首先看图书页面信息:
https://search.jd.com/Search?keyword=%E5%9B%BE%E4%B9%A6&wq=%E5%9B%BE%E4%B9%A6&page=1
https://search.jd.com/Search?keyword=%E5%9B%BE%E4%B9%A6&wq=%E5%9B%BE%E4%B9%A6&page=2
对上面连接可知图书列表每次显示30条数据,页面用page变量复制
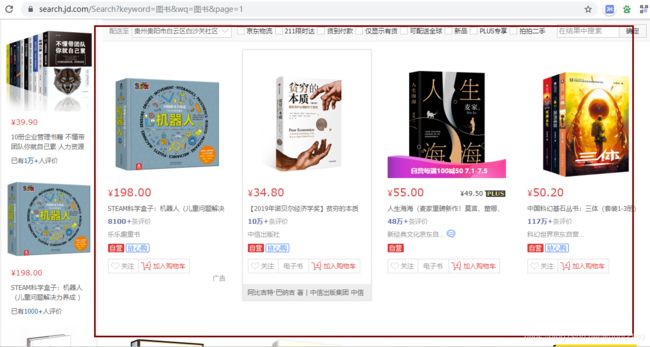
2、对图书列表进行检查:
1)、获取列表xpath路径://[@id=“J_goodsList”]/ul
2)、获取每个图书信息连接(因为图书详情页链接都是以京东主页面连接加上商品编号):

3)、那么想要详细获取商品详情页面就必须进入商品详情页:
xpath://[@id=“J_goodsList”]/ul/li[1]/div/div[3]/a

4)、进入详情,找到指定商品信息并进行获取:
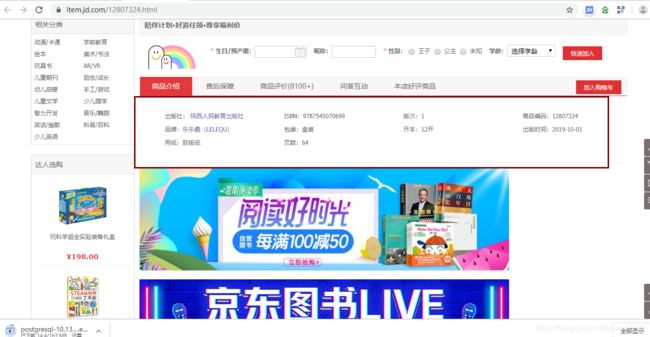
5)、此时你会发现商品信息价格有点获取不了,因为价格和商品名称是动态加载的;一般的爬虫获取不了动态信息,那么我们就开始想办法了,我在检查元素是发现一个有趣的信息:“https://p.3.cn/prices/mgets?skuIds=J_” + 商品id就可以显示商品的价格信息


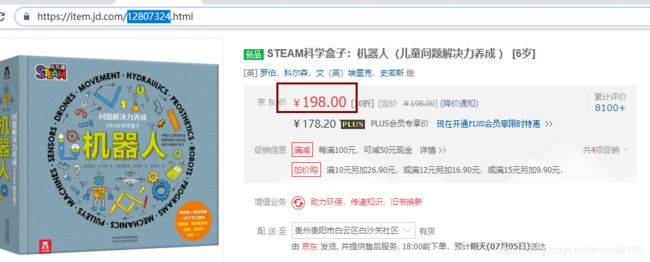
3、那么总的思路:因为要爬取同一件商品不同时间段的价格信息,那么就不只是一次爬取那么简单了;首先第一次爬取商品的详细信息(价格除外)放入一个json文件中,然后根据JSON中的商品ID(利用:“https://p.3.cn/prices/mgets?skuIds=J_” + 商品id)获取价格信息,加上当天爬取的时间段
代码部分
1、创建good.py获取商品详细信息(出价格外)
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
import scrapy
from urllib.parse import quote
from goods.items import GoodsItem
class GoodSpider(scrapy.Spider):
name = 'good'
allowed_domains = ['search.jd.com/Search?keyword=图书']
start_urls = ['https://search.jd.com/Search?keyword=图书&wq=图书&page=1']
def parse(self, response):
print("开始爬虫")
#输入要爬取的页数
keyword = int(input("请输入要爬取的页数:"))
#遍历访问的页数
a_href = []
a = 1
# 关键词中有中文的话,百度就会将其转码为%开始的编码
keyword1 = quote("图书", encoding="utf-8")
print(keyword1)
for a in range(0,keyword):
b = "https://search.jd.com/Search?keyword=%E5%9B%BE%E4%B9%A6&wq=%E5%9B%BE%E4%B9%A6&page="+str(a+1)
a_href.append(b)
a= a+1
print(a_href)
for href in a_href:
print("==" * 40)
print(href)
# 因为请求被去重过滤了,所以才调试不了啊!要加入dont_filter=True才可正常访问
yield scrapy.Request(url=href,callback=self.parse_book_list,dont_filter=True)
def parse_book_list(self, response):
# 进入京东图书详情页
print("进入京东图书详情页")
li_list = response.xpath("//*[@id='J_goodsList']/ul")
print(li_list)
for li in li_list:
item = {}
a_href = li.xpath(".//li/div/div[3]/a/@href").extract()
print(a_href)
if a_href is not None:
a_href = ['https:' + x for x in a_href]
print(len(a_href))
for c_href in a_href:
print("==" * 40)
print(c_href)
yield scrapy.Request(
url=c_href,
callback=self.parse_book_li,
dont_filter=True
)
def parse_book_li(self,response):
item = {}
print("进入详情页")
# 获取书名
item["Title"] = response.xpath("//*[@id='name']/div[1]/text()").extract_first().strip()
print("书名===:",item["Title"])
# 获取作者
item["Author"] = response.xpath("//*[@id='p-author']/a[1]/@data-name").extract_first()
print("作者===:",item["Author"])
li = response.xpath("//*[@id='parameter2']")
b = ':'
# print(li)
for li_book in li:
books=li_book.xpath(".//li/text()").extract()
# print(books)
# 正则表达式替换:之前的字符串
for a in books:
# print(a)
c = a[:a.find(b)]
# print('c=',c)
if c == '出版社':
# 出版社
item["PublishingHouse"] = li.xpath(".//li/a[1]/@title").extract_first()
# print("出版社===:",books["publishing_house"])
elif c == 'ISBN':
# ISBN
item["ISBN"] = a[a.find(b):].replace(":","")
# print("ISBN===:",books["ISBN"])
elif c == '版次':
# 版次
item["Edition"] = a[a.find(b):].replace(":","")
# print("版次===:",books["Edition"])
elif c == '商品编码':
# 商品编号
item["ProductID"] = a[a.find(b):].replace(":","")
# print("商品编号===:",books["ProductID"])
elif c == '包装':
# 包装
item["Packaging"] = a[a.find(b):].replace(":","")
# print("包装===:",books["Packaging"])
elif c == '开本':
# 开本
item["Format"] = a[a.find(b):].replace(":","")
# print("开本===:",books["Format"])
elif c == '出版时间':
# 出版时间
item["PublicationTime"] = a[a.find(b):].replace(":","")
# print("出版时间===:",books["PublicationTime"])
elif c == '用纸类型':
# 用纸类型
item["PaperType"] = a[a.find(b):].replace(":","")
# print("用纸类型===:",books["PaperType"])
elif c == '页数':
# 页数
item["BookNum"] = a[a.find(b):].replace(":","")
# print("页数===:",books["BookNum"])
# else:
# print("格式不正确!")
yield item
# # 出版社
# publishing_house = li.xpath(".//li[1]/[@title='']").extract_first()
# print("出版社:",publishing_house)
# # ISBN
# ISBN = li.xpath(".//li[2]/@title").extract_first()
# print("ISBN:",ISBN)
# # 版次
# edition = li.xpath(".//li[3]/@title").extract_first()
# print("版次:",edition)
# # 商品编号
# product_iD = li.xpath(".//li[4]/@title").extract_first()
# print("商品编号:",product_iD)
# # 品牌
# brand = li.xpath(".//li[5]/@title").extract_first()
# print("品牌:",brand)
# # 包装
# packaging = li.xpath(".//li[6]/@title").extract_first()
# print("包装:",packaging)
# # 开本
# format = li.xpath(".//li[7]/@title").extract_first()
# print("开本:",format)
# # 出版时间
# publication_time = li.xpath(".//li[8]/@title").extract_first()
# print("出版时间:",publication_time)
# # 用纸类型
# paper_type = li.xpath(".//li[9]/@title").extract_first()
# print("用纸类型:",paper_type)
# # 页数
# book_num = li.xpath(".//li[10]/@title").extract_first()
# print("页数:",book_num)
2、创建book_message.py根据上面获取的good.py商品ID获取该商品的当天价格:
# -*- coding: utf-8 -*-
import scrapy
import json
import datetime
import copy
from urllib.parse import quote
from goods.items import GoodsItem
class GoodSpider(scrapy.Spider):
name = 'book_message'
allowed_domains = ['search.jd.com/Search?keyword=图书']
start_urls = ['https://search.jd.com/Search?keyword=图书&wq=图书&page=1']
def parse(self, response):
with open('.//books.json', 'r', encoding='utf-8') as load_f:
strF = load_f.read()
if len(strF) > 0:
datas = json.loads(strF)
a = datas["books"]
print("这是文件中的json数据:")
print(a)
item = {}
for b in a:
#遍历获取的商品信息
#书名
if 'Title' in b:
item["Title"] = b["Title"]
else:
item["Title"] = None
# 获取作者
if 'Author' in b:
item["Author"] = b["Author"]
# 出版社
if 'PublishingHouse' in b:
item["PublishingHouse"] = b["PublishingHouse"]
# ISBN
if 'ISBN' in b:
item["ISBN"] = b["ISBN"]
# 版次
if 'Edition' in b:
item["Edition"] = b["Edition"]
# 商品编号
if 'ProductID' in b:
item["ProductID"] = b["ProductID"]
# 包装
if 'Packaging' in b:
item["Packaging"] = b["Packaging"]
# 开本
if 'Format' in b:
item["Format"] = b["Format"]
# 出版时间
if 'PublicationTime' in b:
item["PublicationTime"] = b["PublicationTime"]
# # 用纸类型
# item["PaperType"] = b["PaperType"]
# 页数
if 'BookNum' in b:
item["BookNum"] = b["BookNum"]
#爬取时间
item["crawlTime"] = datetime.datetime.now().strftime('%Y-%m-%d')
print("time:",item["crawlTime"])
#遍历商品编码
c = b["ProductID"]
print(c)
url = "https://p.3.cn/prices/mgets?skuIds=J_"+c
# print(url)
yield scrapy.Request(
url=url,
callback=self.parse_books,
meta={"item": copy.deepcopy(item)},
dont_filter=True
)
else:
print("这是文件中的json数据为空")
datas = {}
def parse_books(self,response):
item = response.meta["item"]
# 调用body_as_unicode()是为了能处理unicode编码的数据
price_list = json.loads(response.body_as_unicode())
# print sites['k'].split(',')
print("price_list:",price_list)
for li in price_list:
item["ProductPrice"] = li["p"]
#商品价格
print("ProductPrice",item["ProductPrice"])
yield item
3、items部分接收item字典
import scrapy
class GoodsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 书名
Title = scrapy.Field()
# 作者
Author = scrapy.Field()
# 出版社
PublishingHouse = scrapy.Field()
# 书ISBN
ISBN = scrapy.Field()
# 版次
Edition = scrapy.Field()
# 商品编码
ProductID = scrapy.Field()
# 包装
Packaging = scrapy.Field()
# 开本
Format = scrapy.Field()
# 出版时间
PublicationTime = scrapy.Field()
# 用纸类型
PaperType = scrapy.Field()
#页数
BookNum = scrapy.Field()
#爬取时间
crawlTime = scrapy.Field()
#爬取当天价格
ProductPrice = scrapy.Field()
4、setting部分:
# -*- coding: utf-8 -*-
# Scrapy settings for goods project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'goods'
SPIDER_MODULES = ['goods.spiders']
NEWSPIDER_MODULE = 'goods.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'goods (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'goods.middlewares.GoodsSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'goods.middlewares.GoodsDownloaderMiddleware': 543,
'goods.middlewares.UserAgentDownloadMiddleware': 10,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'goods.pipelines.GoodsPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
5、middlewares.py
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
import random
class UserAgentDownloadMiddleware(object):
USER_AGENTS=[
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36",
"Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16",
"Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14",
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1",
"Mozilla/5.0 (Windows NT 6.3; rv:36.0) Gecko/20100101 Firefox/36.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10; rv:33.0) Gecko/20100101 Firefox/33.0",
"Mozilla/5.0 (X11; Linux i586; rv:31.0) Gecko/20100101 Firefox/31.0",
]
def process_request(self,request,spider):
user_agent = random.choice(self.USER_AGENTS)
request.headers['User-Agent']=user_agent
6、pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.exporters import JsonLinesItemExporter
from openpyxl import Workbook
class GoodsPipeline(object):
def __init__(self):
# 转为json格式
self.book_fp = open('book.json', 'wb')
self.book_exporter = JsonLinesItemExporter(self.book_fp, ensure_ascii=False)
#转为excel表
self.wb = Workbook() # 类实例化
self.ws = self.wb.active # 激活工作表
self.ws.append(['Title', 'Author', 'PublishingHouse', 'ISBN', 'Edition', 'ProductID', 'Packaging',
'Format','PublicationTime','BookNum','crawlTime','ProductPrice']) # 添加表头
def process_item(self, item, spider):
#接收item(json)
self.book_exporter.export_item(item)
# excel
data = [item["Title"], item["Author"], item["PublishingHouse"], item["ISBN"], item["Edition"],
item["ProductID"], item["Packaging"], item["Format"],item["PublicationTime"],
item["BookNum"], item["crawlTime"], item["ProductPrice"]]
self.ws.append(data) # 将数据以行的形式添加到工作表中
self.wb.save('books_1.xlsx') # 保存
return item
def close_spider(self,spider):
self.book_fp.close()
7、首先运行main启动类,获取商品ID及详细信息
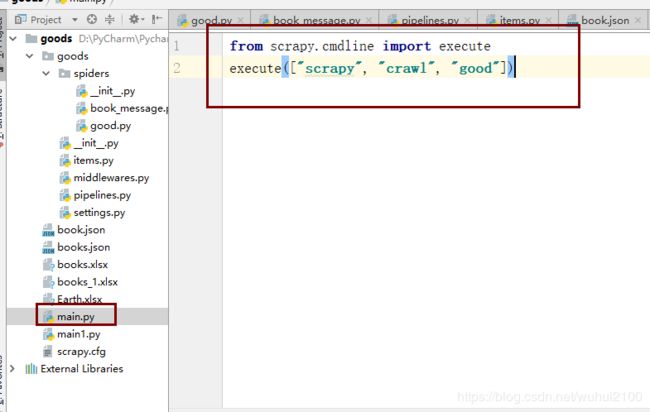
最后运行main1获取同一件商品当前爬取的时间段价格

运行结果:
1、运行main结果如下
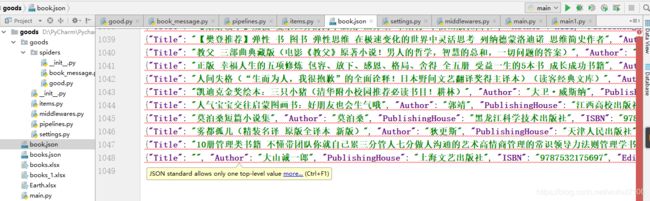
注意:这里使用需要把获取的json前面加上{“books”:[ ,尾部加上 ] } 复制全部内容放入自己创建的books.json中
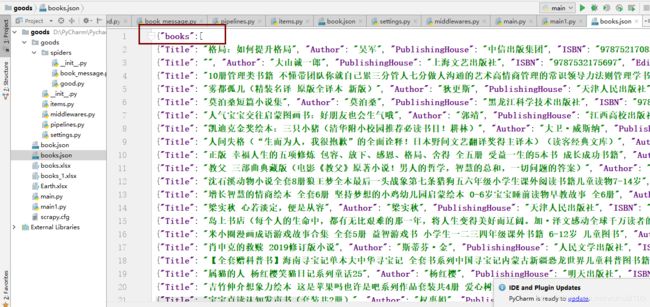
2、再运行main1即可获取自己想要的当前爬取的商品价格信息了
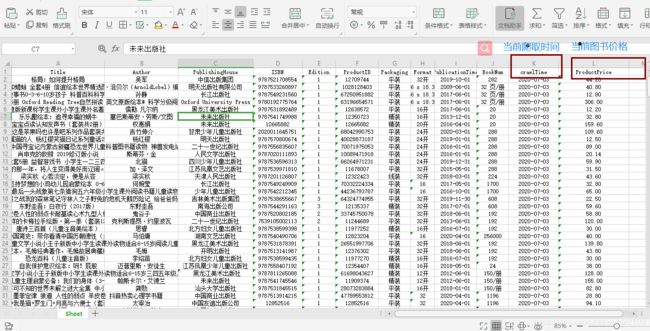
打开结果:
最累的时候,家人是你最好的归宿!