ElasticJob -- 分布式作业调度
Elastic-Job是一个分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。
Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供最轻量级的分布式任务的协调服务,外部依赖仅Zookeeper。
Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务。
项目开源地址:https://github.com/dangdangdotcom/elastic-job
场景分析:
任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
场景1:有一个遍历数据库某张表的作业,现有2台服务器。为了快速的执行作业,那么每台服务器应执行作业的50%。 为满足此需求,可将作业分成2片,每台服务器执行1片。作业遍历数据的逻辑应为:服务器A遍历ID以奇数结尾的数据;服务器B遍历ID以偶数结尾的数据。 如果分成10片,则作业遍历数据的逻辑应为:每片分到的分片项应为ID%10,而服务器A被分配到分片项0,1,2,3,4;服务器B被分配到分片项5,6,7,8,9,直接的结果就是服务器A遍历ID以0-4结尾的数据;服务器B遍历ID以5-9结尾的数据。
场景2:余额宝里的昨日收益,系统需要job在每天某个时间点开始,给所有余额宝用户计算收益。如果用户数量不多,我们可以轻易使用quartz来完成,我们让计息job在某个时间点开始执行,循环遍历所有用户计算利息,这没问题。可是,如果用户体量特别大,我们可能会面临着在第二天之前处理不完这么多用户。另外,我们部署job的时候也得注意,我们可能会把job直接放在我们的webapp里,webapp通常是多节点部署的,这样,我们的job也就是多节点,多个job同时执行,很容易造成重复执行,比如用户重复计息,为了避免这种情况,我们可能会对job的执行加锁,保证始终只有一个节点能执行,或者干脆让job从webapp里剥离出来,独自部署一个节点。
elastic-job就可以帮助我们解决上面的问题,elastic底层的任务调度还是使用的quartz,通过zookeeper来动态给job节点分片
整体架构图
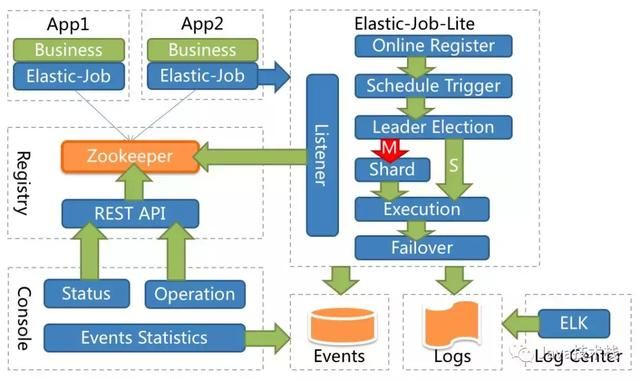
Elastic-Job-Lite
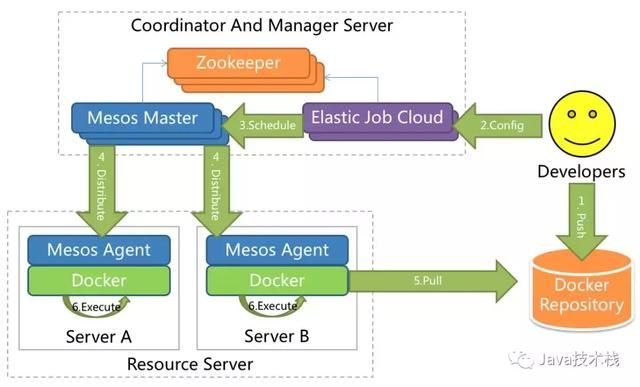
Elastic-Job-Cloud
作业启动流程
-
弹性分布式实现
-
第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
-
某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态。
-
主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
-
定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
-
通过4可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
-
每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
-
实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。
-

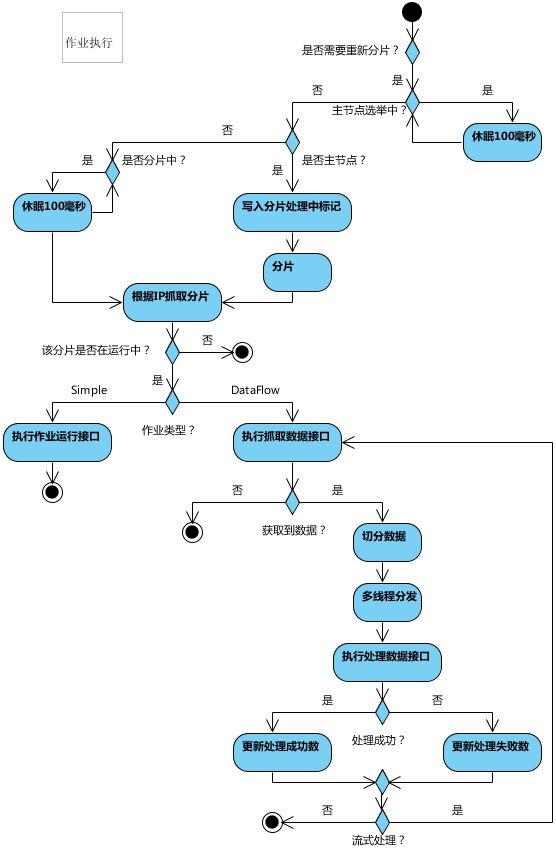
作业执行流程
应用:
1. 引入框架的jar包
com.dangdang
elastic-job-lite-core
2.0.5
com.dangdang
elastic-job-lite-spring
2.0.5
2. 构建job
public class MyTask implements SimpleJob{
public void execute(ShardingContext context) {
System.out.println("定时任务测试");
}
}3. spring 配置
url="${ds1.jdbc.url}" username="${ds1.jdbc.username}" password="${ds1.jdbc.password}"
log-level="INFO" />
分片:
public interface SimpleJob extends ElasticJob {
/**
* 执行作业.
*
* @param shardingContext 分片上下文
*/
void execute(ShardingContext shardingContext);
}注意这里面有一个shardingContext参数,看下源码:
/**
* 分片上下文.
*
* @author zhangliang
*/
@Getter
@ToString
public final class ShardingContext {
/**
* 作业名称.
*/
private final String jobName;
/**
* 作业任务ID.
*/
private final String taskId;
/**
* 分片总数.
*/
private final int shardingTotalCount;
/**
* 作业自定义参数.
* 可以配置多个相同的作业, 但是用不同的参数作为不同的调度实例.
*/
private final String jobParameter;
/**
* 分配于本作业实例的分片项.
*/
private final int shardingItem;
/**
* 分配于本作业实例的分片参数.
*/
private final String shardingParameter;
public ShardingContext(final ShardingContexts shardingContexts, final int shardingItem) {
jobName = shardingContexts.getJobName();
taskId = shardingContexts.getTaskId();
shardingTotalCount = shardingContexts.getShardingTotalCount();
jobParameter = shardingContexts.getJobParameter();
this.shardingItem = shardingItem;
shardingParameter = shardingContexts.getShardingItemParameters().get(shardingItem);
}
}这里面有2个很重要的属性:shardingTotalCount 分片总数(比如:2)、shardingItem 当前分片索引(比如:1),前面提到的性能扩容,就可以根据2个参数进行简单的处理,假设在电商系统中,每天晚上有个定时任务,要统计每家店的销量。商家id一般在表设计上是一个自增数字,如果总共2个分片(注:通常也就是部署2个节点),可以把 id为奇数的放到分片0,id为偶数的放到分片1,这样2个机器各跑一半,相对只有1台机器而言,就快多了。
伪代码如下:
public class TestJob implements SimpleJob {
@Override
public void execute(ShardingContext shardingContext) {
int shardIndx = shardingContext.getShardingItem();
if (shardIndx == 0) {
//处理id为奇数的商家
} else {
//处理id为偶数的商家
}
}
}这个还可以进一步简化,如果使用mysql查询商家列表,mysql中有一个mod函数,直接可以对商家id进行取模运算
select * from shop where mod(shop_id,2)=0
如果把上面的2、0换成参数,mybatis中类似这样:
select * from shop where mod(shop_id,#{shardTotal})=#{shardIndex}
作业类型:
elastic-job提供了三种类型的作业:Simple类型作业、Dataflow类型作业、Script类型作业。这里主要讲解前两者。Script类型作业意为脚本类型作业,支持shell,python,perl等所有类型脚本,使用不多,可以参见github文档。
SimpleJob需要实现SimpleJob接口,意为简单实现,未经过任何封装,与quartz原生接口相似,比如示例代码中所使用的job。
Dataflow类型用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。
可通过DataflowJobConfiguration配置是否流式处理。
流式处理数据只有fetchData方法的返回值为null或集合长度为空时,作业才停止抓取,否则作业将一直运行下去; 非流式处理数据则只会在每次作业执行过程中执行一次fetchData方法和processData方法,随即完成本次作业。
实际开发中,Dataflow类型的job还是很有好用的。
public class MyDataFlowJob implements DataflowJob {
/*
status
0:待处理
1:已处理
*/
@Override
public List fetchData(ShardingContext shardingContext) {
List users = null;
/**
* users = SELECT * FROM user WHERE status = 0 AND MOD(id, shardingTotalCount) = shardingItem Limit 0, 30
*/
return users;
}
@Override
public void processData(ShardingContext shardingContext, List data) {
for (User user: data) {
user.setStatus(1);
/**
* update user
*/
}
}
}
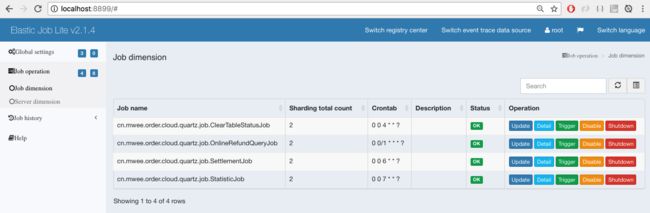
控制台:
elastic-job还提供了一个不错的UI控制台,项目源代码git clone到本地,mvn install就能得到一个elastic-job-lite-console-${version}.tar.gz的包,解压,然后运行里面的bin/start.sh 就能跑起来,界面类似如下:
-
作业详细信息页
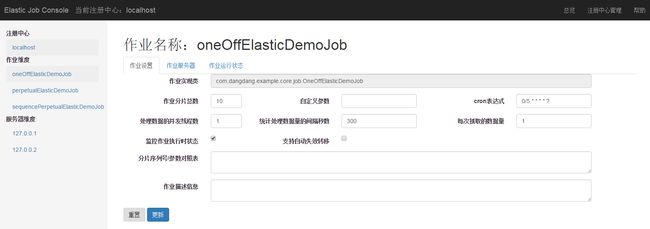
通过这个控制台,可以动态调整每个定时任务的触发时间(即:cornExpress)。详情可参考官网文档-运维平台部分。
Refrence:
https://www.cnblogs.com/yjmyzz/p/elastic-job-tutorial.html
https://github.com/elasticjob/elastic-job-lite
https://www.cnblogs.com/wyb628/p/7682580.html