《Python源码剖析》读书笔记
《Python源码剖析》电子书下载 http://download.csdn.net/detail/xiarendeniao/5130403
PyObject
Python对象机制的基石,Python中所有对象都拥有PyObject这一部分内容(且在对象所占内存的开头部分)
PyObject其实就是一个引用计数(int)和一个类型对象指针(PyTypeObject* ob_type)组成的结构体
PyObject*作为一个泛型指针在Python内部传递,所有对象的指针都使用PyObject*,具体是什么类型可以从指针所指对象的ob_type域(Python利用该域实现多态)动态判断
PyVarObject
PyVarObject是变长对象(包含可变长度数据的对象)的开头
变长对象(PyStringObject等)的不同对象占用的内存大小可能不一样,定长对象(PyIntObject等)的不同对象占用的内存是一样的
PyVarObject是对PyObject的扩展,由PyObject和一个元素个数(int)组成
PyTypeObject
类型对象,内部成员记录该类型的名称、各种操作函数(如构造函数、加减数值运算、大小比较等)等,详见PyTypeObject的C语言定义
是Python中对面向对象理论中"类"这个概念的实现
在C中用PyTypeObject作为类型定义出来的各变量(如PyInt_Type)就是面向对象中的"类"
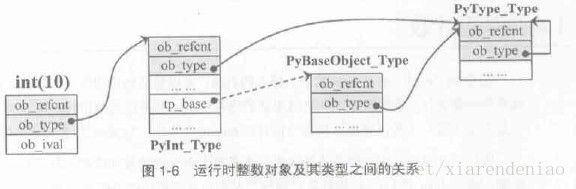
每个"实例对象"的实例(如PyIntbject的一个实例int(5))的ob_type指针指向一个与自己关联的类型对象的实例(如PyInt_Type),类型对象(PyTypeObject)的实例(如PyInt_Type)的ob_type指针指向实例PyType_Type,PyType_Type(理论上说PyType_Type应该是一个全局唯一对象)的ob_type指针指向它自己(Page25)[图1-6]
用实例对象作为类型定义的变量/对象就是我们一般意义上的实例对象(C++中的实例对象)
PyBaseObject_Type
所有对象最顶层的父类(PyInt_Type的tp_base指向PyBaseObject_Type)
PyBaseObject_Type这个对象的ob_type指向PyType_Type
PyIntObject
整数对象
0.查看书中陈列的类型定义/对象创建代码思路会比较清晰
1.小整数在python初始化的时候创建好放入缓冲池备用,无需在使用时创建对象;小整数的范围是可配置后编译的
2.大整数在使用时当场创建对象,然后放入block_list中的某个位置;大整数不再使用时(引用计数减少到零)并没有释放其在block_list中的内存,只是加入到free_list链表而已,那么疯狂创建大整数(创建新的大整数时旧的大整数暂不释放,使其无法复用内存)是可以导致内存泄露的
3.所有整数对象由block_list+free_list来维护,包括小整数对象池
PyStringObject
字符串对象
1.字符串对象是不可变的变长对象:对象大小不固定(由字符串长度而定;相比而言,整数对象就是定长对象);对象一旦创建,不可修改(和tuple类似)
2.空字符串对象统一由nullstring代替,使用时只用修改这个全局对象的引用计数即可
3.单个字符的字符串对象有缓冲机制,第一次使用的时候创建对象并缓存下来(和小整数不一样,小整数是python初始化的时候就创建好),下次使用的时候省去了对象创建过程
4.字符串对象支持intern机制,对某个字符串对象使用intern之后该字符串对象就指针就存入到interned这个dict(对于非单个字符的对象,使用intern机制的时候,对象的引用计数不增加,防止对象因引用计数永远>=2而无法销毁),当下次创建字符串对象时检查该字符串是否已经interned,是的话就返回interned中的引用,销毁新创建的临时对象(所以,intern机制不能避免新对象的创建,不过确实能减少内存的消耗;intern机制还可以让字符串比较变得easy,只用比较PyStringObject的指针即可,因为相同的字符串都由同一个PyStringObject表示着)
5.字符串拼接尽量用join而不要用+:'aa'+'bb'+'cc'需要分配两次内存(string_concat);''.join(['aa','bb','cc'])只需分配一次内存(string_join);后者效率更高
PyListObject
列表对象
1.PyListObject也有缓冲机制,当对象销毁(PyListObject的析构函数)的时候只销毁PyListObject维护的元素列表ob_item(把数组ob_item中每个指针所指对象引用计数减一;把数组ob_item所占内存释放),把PyListObject对象放入缓冲池free_lists中,当下次创建新对象的时候直接从缓冲池获取一个并创建其元素列表即可;如果free_lists已满(num_free_lists>=MAXFREELISTS)就不缓存而直接销毁
2.PyListObject跟C++的vector结构类似;内部的内存管理机制也差不多;跟C++中的list却很不一样
3.对于可能为NULL的PyObject指针,减少其引用计数的时候需要用Py_XDECREF
4.当insert/append元素时会调整PyListObject维护的元素列表的内存大小list_resize()(remove的时候貌似不会),调整的条件是"newsize>=allocate||newsize<=allocated/2"
PyDictObject
字典对象
1.关联容器(元素以键值对的形式存在)存储符合该容器所代表的关联规则的元素对(同一个PyDcitObject中存储的key/value类型可以都不一样,这个跟C++ map那种强类型的东东不一样哦),要求极高的搜索效率;C++STL中的map基于红黑树(RB-tree,平衡二叉树)实现,搜索时间复杂度O(logN);PyDictObject对搜索效率要求更高,因为Python字节码(变量名-变量值,k-v)的运行环境都需要通过PyDictObject来建立;PyDictObject的数据结构采用散列表(hash table),搜索的最佳时间复杂度是O(1)
2.当不同的key通过散列函数(hash function,将key映射成一个整数,可以用整数作为索引值访问某块内存区域)得到相同的散列值(hash value)时,就出现了散列冲突;出现冲突时Python使用探测函数f作二次探测确定下一个候选位置(开放定址法;也可以用开链法解决散列冲突);多次探测时形成的链路叫“冲突探测链”(探测序列),当元素删除时只能伪删除,否则会导致该链路断掉,使得其下一次的搜索无法搜到链路后半截的元素
3.PyDictEntry是PyDictObject维护的键值对;三种状态Unused/Active/Dummy;Dummy状态的PyDictEntry为删除的产物、可复用
4.PyDictObject创建时会默认开辟PyDict_MINSIZE(8)个元素的内存空间(ma_smalltable数组);当insert操作使得dict的元素超过该大小时才会申请额外空间
5.和PyListObject类似,PyDictObject也有缓冲池(free_dicts/num_free_dicts/MAXFREEDICTS)
6.搜索策略lookdict/lookdict_string(默认的简化版搜索函数)是核心,插入/删除都是基于搜索来实现的,搜索结果:成功 Active PyDictEntry; 失败 Unused PyDictEntry / Dummy PyDictEntry
7.插入/设置元素后会检查是否需要调整PyDcitObject元素存储的内存区域(ma_table所指向的数组;如果指向ma_smalltable就忽略)大小(装载率ma_fill/(ma_mask+1)大于2/3时调整);调整操作把内存区域缩小或放大都是有可能的;调整操作的过程实质上是把Dummy PyDictEntry丢掉并重构探测链(dictresize函数)
[第七章]Python的编译结果--Code对象和pyc文件
.pyc
二进制文件
import会触发.pyc文件的生成,在sys.path中找到.py而没找到.pyc和.dll时python会编译.py文件(得到PyCodeObject对象)并写入.pyc文件
python标准库的py_compile/compilier也可以编译.py文件
组成:magic number(用于做python版本兼容);.pyc创建时间;PyCodeObject对象
其实就是把内存中PyCodeObject的数据以一定的规则写入到硬盘上方便下次使用的时候快速加载(写和读详见7.3.1/7.3.2)
PyCodeObject
一个PyCodeObject可以嵌套多个其他的PyCodeObject,被嵌套的对象记录在co_consts中
一个Code Block对应一个PyCodeObject
包含字节码指令以及程序所有静态信息
PyCodeObject.co_code:字节码指令序列,PyStringObject
PyCodeObject.co_const:常量表,保存Code Block中所有常量,PyTupleObject
PyCodeObject.co_names:符号表,保存Code Block中所有符号,PyTupleObject
python标准库的dis可以解析PyCodeObject对象(得到字节码指令信息)
名字空间
符号(名字)的上下文环境,符号的含义取决于和值取决于名字空间
python中module(.py文件)、类、函数都对应着一个独立的名字空间
一个Code Block对应着一个名字空间、对应着一个PyCodeObject
[第八章]Python虚拟机框架
PyFrameObject
操作系统运行可执行文件时函数之间的调用通过创建新的栈帧完成,一个函数对应一个栈帧,一连串的栈帧组成函数调用栈,一个函数执行完系统把栈指针和帧指针恢复到前一个栈帧
一个PyFrameObject跟一个Code Block (一个PyCodeObject)对应,记录着执行环境
多个PyFrameObject相链模拟操作系统函数调用栈(执行环境链)
对象内部包含PyCodeObject、buildin(内建)名字空间、global(全局)名字空间、local(局部)名字空间
PyFrameObject对象内部的"运行时栈"单指运算时所需内存空间(和操作系统的"运行时栈"不同);运行时栈的大小是由python编译时计算好了存储在PyCodeObject中的
名字空间
"约束":一个名字(也叫符号/标识符,如变量名、函数名、类名等)和实际对象之间的关联关系(name,obj),由赋值语句创建(说白了就是变量名和变量值之间的对应关系)
一个PyDictObject对象,存放着"约束"(说白了就是存放着变量名和变量值之间的对应关系)
一个module中可能存在多个名字空间,每个名字空间与一个作用域对应
一个对象的名字空间中的所有名字都称为对象的属性
属性引用可当做特殊的名字引用,不受LEGB制约,直接到某个对象的名字空间中去查找名字
作用域
一个"约束"(变量名和变量值之间对应关系)起作用的那段Code Block称为这个"约束"的作用域
作用域由源程序的文本决定; 可见,python具有静态作用域(词法作用域)的性质
个人理解:说白了就是定义变量的代码所在的Code Block
LGB
python2.2之前的作用域规则
名字引用动作沿着local作用域、global作用域、buildin作用域的顺序查找名字对应的"约束"
LEGB
python2.2引入嵌套函数以后的作用域规则
最内嵌套作用域规则:由一个赋值语句引进的名字在这个赋值语句所在的作用域里是可见(起作用)的,而且在其内部嵌套的每个作用域里也可见,除非它被嵌套于内部的、引用同样名字的另一条赋值语句所屏蔽
E:enclosing,闭包,"直接外围作用域";把内嵌函数对象和内嵌函数Code Block中名字引用的实际约束(上一层函数定义的作用域/上上一层/全局/buildin)捆绑起来的整体叫做闭包
该规则使得:决定python程序行为更多的是代码出现位置而不是代码执行先后时间(内嵌函数对象不管什么时候执行,它内部引用的名字始终对应闭包里面的对象)
LEGB VS 闭包
前者是语言设计时的设计策略,形而上的“道”;后者是实现语言的一种方案,形而下的“器”
global
强制命令python对某个名字的引用只参考global名字空间而不用去管LEGB规则
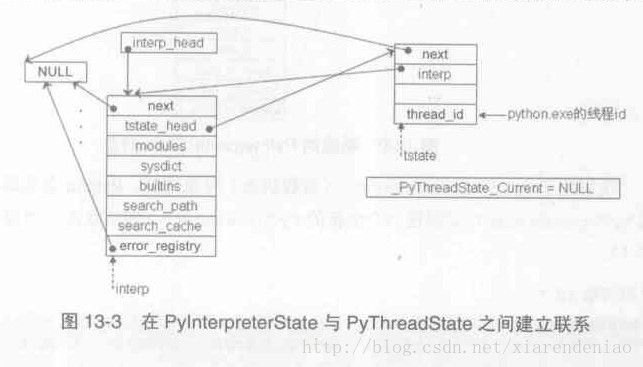
PyInterpreterState
表示进程概念的对象
PyInterpreterState.tstate_head模拟进程环境中的线程集合(由多个PyThreadState对象组成,PyThreadState轮流使用字节码执行引擎)
PyThreadState
表示线程概念的对象
PyThreadState.frame模拟线程中的函数调用栈(PyFrameObject链)
PyEval_EvalFrameEx
操作当前PyFrameObject:顺序执行PyFrameObject中PyCodeObject中的字节码指令,利用PythonFrameObject的运行时栈、PyCodeObject的符号表、PyCodeObject的常量表操作名字空间
[第九章]Python虚拟机中的一般表达式
1.简单内建对象的创建:根据字节码指令(LOAD_CONST、STORE_NAME)从PythonCodeObject的常量表和符号表中取出对应数据利用PyFrameObject的运行时栈做临时存储空间最终建立变量名和变量值之间的对应关系并存储到local名字空间中
2.看陈列的字节码和字节码对应的C代码挺有意思
3.数值运算加法(BINARY_ADD)有快速通道(PyIntObject相加/PyStringObject相加)和慢速通道(有大量的类型判断和寻找对应加法函数的操作);如果程序有大量浮点运算,为了提高效率可以手动添加对应的快速通道,然后重新编译Python
4.print >> file('/tmp/d','w'),'data.data.data' 原来print还有这种用法!
[第十章]Python虚拟机中的控制流
[第十一章]Python虚拟机中的函数机制
def f(): ---> MAKE_FUNCTION指令 ---> PyFunction_New(PyObject* code, PyObject* globals) ---> PyFunctionObject对象
f() ---> CALL_FUNCTION指令 ---> call_function(PyObject*** pp_stack, int oparg) ... ---> PyEval_EvalFrameEx() (函数调用过程:创建新的栈帧,在新的栈帧中执行代码)
PyFunctionObject是对字节码和global名字空间的一种打包和运输方式。(global名字空间、默认参数、字节码指令捆绑在PyFunctionObject这个大包袱中,PyFunctionObject是Python中闭包的具体表现)
C语言中函数是否可调用(可编译通过)完全是基于源代码中函数出现的位置做的分析,而Python则依靠的是运行时的名字空间。
Python四种类别的函数参数:
位置参数(positional argument):f(a,b)
键参数(key argument):f(a,b=10)
扩展位置参数(excess positional argument):def f(a,b,*list):...
扩展键参数(excess key argument):def f(a,b,**keys):...
函数参数中一个参数是位置参数还是键参数实际上仅仅是由函数实参的形式所决定的,而与函数定义时的形参没有任何关系。另,非键参数的位置必须在键参数之前。
CALL_FUNCTION指令的参数2Byte,低字节记录位置参数个数,高字节记录键参数个数(因此Python函数最多256个位置参数/键参数)。
Python内部把扩展位置参数*list作为一个局部变量(每个普通位置参数也作为一个局部变量):def PyFunc(a,b,*list):pass 对于PyFunc(1,2,3,4)的调用,co_argcount=2,co_nlocals=3 (co_argcount/co_nlocals是PyCodeObject的成员,在编译时确定,所以不管函数如何调用这两个值不变;所有扩展位置参数被存储到一个PyListObject对象中)
与上述类似,Python的所有扩展键参数被存储到一个PyDictObject对象中。
位置参数在函数调用过程中如何传递和访问:在调用函数时,Python将函数参数值从左至右压入到运行时栈中,在fast_function中,又将这些参数依次(从左到右)拷贝到新建的与函数对应的PyFrameObject对象的f_localsplus中。在访问函数参数时,Python虚拟机没有按照通常访问符号的做法,去查什么名字空间,而是直接通过一个索引(偏移位置)来访问f_localsplus中存储的符号对应的值对象。这种通过索引(偏移位置)进行访问的方法也正是“位置参数”名称的由来。
通过阅读函数调用的实现部分(参数的传递、默认参数的使用和替换),可以发现函数调用时位置参数必须在键参数的左边,而键参数跟键参数之间的先后顺序则没什么要求!(位置参数跟位置参数之间的先后顺序?脑子进水了才会想这个问题)
所有扩展位置参数一股脑塞进一个PyTupleObject,该PyTupleObject对象被Python虚拟机通过SETLOCAL放到了PyFrameObject对象的f_localsplus中,位置是co->co_argcount,普通位置参数列表后的第一个位置。
当函数拥有扩展位置参数时,扩展键参数的PyDictObject对象在f_localsplus中的位置一定在扩展位置参数PyTupleObject对象之后的下一个位置。函数内部的局部变量和函数参数一样,都是存在f_localsplus中运行时栈前面的那段内存中间中。(为什么在函数实现中没有local名字空间呢?因为函数中局部变量总是固定不变的,所以在编译时就能确定局部变量使用的内存空间的位置,也能确定访问局部变量的字节码指令应该如何访问内存。跟查名字空间相比这种静态访问更快。)
[闭包]
名字空间和函数捆绑后的结果被称为闭包(closure)。闭包是Python的核心作用域规则(最内嵌套作用域规则)的一种实现形式。
closure相关:PyCodeObject:
PyCodeObject.co_cellvars 通常是一个tuple,保存嵌套的作用域中使用的变量名集合
PyCodeObject.co_freevars 通常是一个tuple,保存使用了的外层作用域中的变量名集合
PyFrameObject:
PyFrameObject.f_localsplus 指向的内存包含:局部变量(参数+局部变量)、cell对象(PyCodeObject.co_cellvars对应的PyCellObject)、free对象(PyCodeObject.co_freevars对应的PyCellObject)、运行时栈
PyFunctionObject:
PyFunctionObject.func_closure NULL or a tuple of PyCellObject
PyCellObject,cell对象在PyFrameObject.f_localsplus中局部变量之后的位置。对cell对象的访问也是通过基于索引访问PyFrameObject.f_localsplus来完成,不需要知道cell变量对应的变量名。在CALL_FUNCTION指令执行过程中(PyEval_EvalCodeEx()函数内部)会创建新的PyFrameObject对象,并为其创建ob_ref=NULL的PyCellObject对象,并拷贝到PyFrameObject.f_localsplus中,在执行到相关变量(被内嵌函数引用的局部变量)的赋值语句时才会设置PyCellObject.ob_ref(STORE_DEREF指令)。
内嵌函数的定义语句“def inner_func():”编译成字节码“LOAD_CLOSURE,BUILD_TUPLUE,LOAD_CONST,MAKE_CLOSURE,STORE_FAST”,这些指令执行时创建内嵌函数对应的PyFunctionObject对象,并将[内嵌函数对应的PyCodeObject]/[global名字空间]/[PyCellObject的tuple(约束集合)]/[默认参数]都设置到PyFunctionObject内部成员身上,然后PyFunctionObject对象被放入到当前函数栈帧(内嵌函数外部这个函数)的f_localsplus中(局部变量区域)。
内嵌函数执行时(CALL_FUNCTION指令),PyEval_EvalCodeEx()函数根据PyFunctionObject(内嵌函数对象).PyCodeObject.co_freevars(引用的外部作用域中的符号名)把参数closure(传入的外部函数构建的闭包tuple)中的PyCellObject对象一个一个放入到PyFrameObject(当前栈帧对象,内嵌函数对应的栈帧).f_localsplus相应位置。
装饰器(Decorator)仅仅是对原函数func做"func=decorator_func(func)"包装。用的还是closure的概念。[第十二章]Python虚拟机中的类机制
12.1
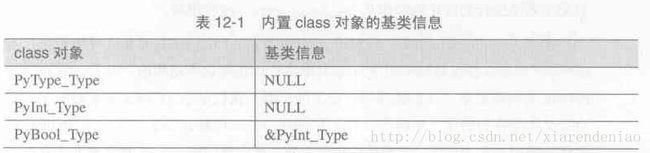
Python2.2之前用户定义的class不能继承自内置的type(int,dict等)。
Python2.2之前Python中实际存在三种对象:type对象表示Python内置的类型
class对象表示Python程序员定义的类型
instance对象(实例对象)表示由class对象创建的实例
Python2.2之后type和class已统一。我们用
通过对象的__class__属性或Python内置的type方法可以探测一个对象和哪个对象存在is-instace-of关系;通过对象的__bases__属性可以探测一个对象和哪个对象存在is-kind-of关系;Python还提供了两个内置方法issubclass和isinstanceof来判断两个对象间是否存在我们期望的关系。
[dongsong@localhost python_study]$ cat metaclass.py
#encoding=utf-8
class A(object):
pass
if __name__ == '__main__':
a = A()
print 'a.__class__ = %s' % str(a.__class__)
print 'type(a) = %s ' % str(type(a))
print 'A.__class__ = %s' % str(A.__class__)
print 'type(A) = %s' % str(type(A))
print 'object.__class__ = %s' % str(object.__class__)
print 'type(object) = %s' % str(type(object))
print 'A.__bases__ = %s' % str(A.__bases__)
print 'object.__bases__ = %s' % str(object.__bases__)
try:
print 'a.__bases__ = %s' % str(a.__bases__)
except Exception,e:
print '%s: %s' % (type(e), str(e))
print 'isinstance(a,A) = %s' % str(isinstance(a,A))
print 'issubclass(A,object) = %s' % str(issubclass(A,object))
print 'type.__class__ = %s' % str(type.__class__)
print 'type.__bases__ = %s' % str(type.__bases__)
print 'int.__class__ = %s' % str(int.__class__)
print 'int.__bases__ = %s' % str(int.__bases__)
print 'dict.__class__ = %s' % str(dict.__class__)
print 'dict.__bases__ = %s' % str(dict.__bases__)
[dongsong@localhost python_study]$ vpython metaclass.py
a.__class__ =
type(a) =
A.__class__ =
type(A) =
object.__class__ =
type(object) =
A.__bases__ = (,)
object.__bases__ = ()
: 'A' object has no attribute '__bases__'
isinstance(a,A) = True
issubclass(A,object) = True
type.__class__ =
type.__bases__ = (,)
int.__class__ =
int.__bases__ = (,)
dict.__class__ =
dict.__bases__ = (,)

总结:
在Python中,任何一个对象都有一个type,可以通过对象的__class__属性获得。任何一个instance对象的type都是一个class对象,而任何一个class对象的type都是metaclass对象。在大多数情况下这个metaclass都是
,而在Python内部,它实际上对应的就是PyType_Type。 在Python中,任何一个class对象都直接或间接与
对象之间存在is-kind-of关系,包括 。在Python内部, 对应的是PyBaseObject_Type。
12.2
[图12-4]
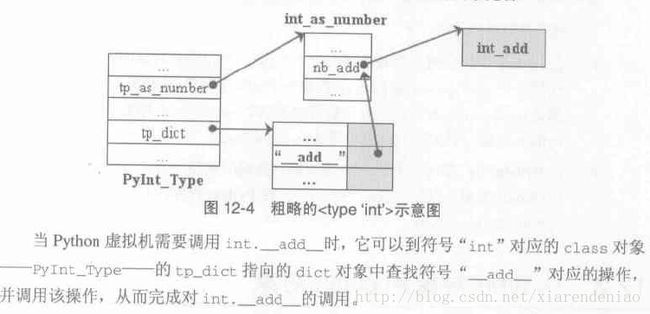
只要一个对象对应的class对象中实现了"__call__"操作(在Python内部的PyTypeObject中,tp_call不为空),那么该对象就是一个可调用(callable)的对象。在Python内部,是通过一个名为PyObject_Call的函数对instance对象进行操作,从而调用对象中的__call__,完成"可调用"特性的。一个对象是否可调用并不是在编译期能确定的,必须是在运行时才能在PyObject_CallFunctionObjArgs中确定。
从Python2.2开始,Python启动时会对类型系统(对象模型)进行初始化动作,动态的在内置类型对应的PyTypeObject(比如,对于int就是修改全局变量PyInt_Type的成员属性)中填充一些重要的东西(包括填充tp_dict,从而完成内置类型从type对象到class对象的转变)。这个初始化动作从_Py_ReadyTypes函数开始(内部调用PyType_Ready函数)。
class对象(如PyInt_Type)的ob_type信息(如PyType_Type)就是对象的__class__将返回的信息;ob_type就是metaclass。Python虚拟机将基类(ob_base)的metaclass作为了子类的metaclass。[表12-1]
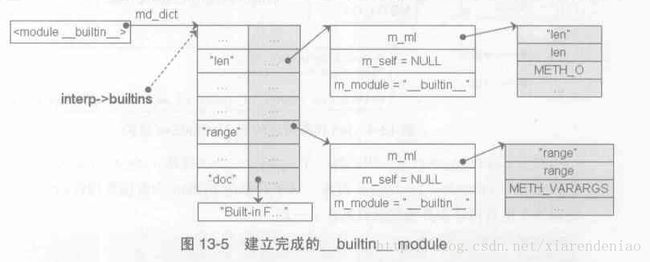
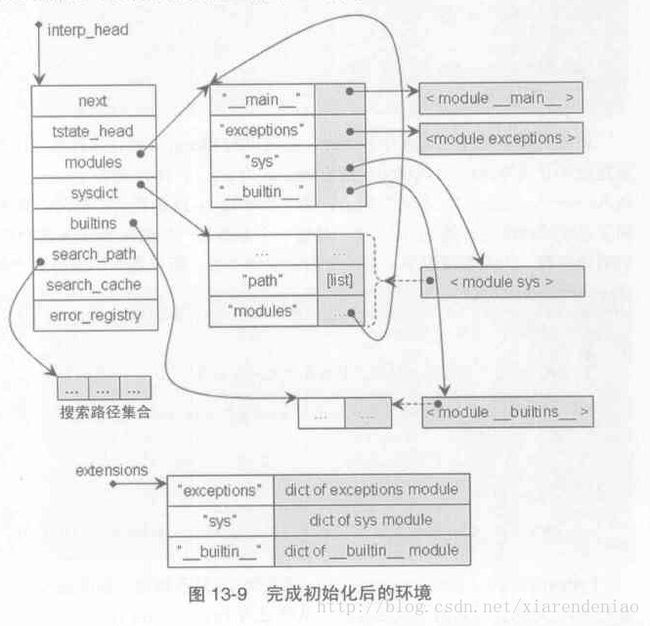
PyHeapTypeObject定义中的各个域的顺序隐含着操作优先级信息。比如,PyMappingMethods的位置在PySequenceMethods之前,mp_subscript是PyMappingMethods中的PyObjet*,而sq_item是PySequenceMethods中的PyObject*,所以最终计算出的偏移:offset(mp_subscript) 整个对slotdefs排序在init_slotdefs函数中完成。slot中的offset正是操作排序的关键所在。 slot可以视为PyTypeObject中定义的操作,包含操作名name、操作的函数地址在PyHeapTypeObject中的偏移量offset、函数指针等。 PyTypeObject对象的tp_dict成员是一个PyDictObject对象,key是"__getitem__"等操作名,value是包装了slot的PyObject(被称为descriptor)。 [第十三章]Python运行环境初始化 Py_InitializeEx()-->PyInterpreterState_New()创建PyInterpreterState对象;PyThreadState_New()创建PyThreadState对象。 interp_head是PyInterpreterState对象通过next指针形成链表结构的表头,模拟OS多进程。 PyThreadState对象通过next指针形成链表模拟OS多线程。 PyFrameObject对象链表就是函数调用栈。 图13-3.PyInterpreterState和PyThreadState之间的联系 全局变量_PyThreadState_Current维护者当前活动线程PyThreadState对象。Python启动时创建第一个PyThreadState对象后用PyThreadState_Swap()函数设置这个全局变量。 Py_InitializeEX()-->_Py_ReadyTypes()初始化Python类型系统(Python的类机制里面有描述)。 Py_InitializeEX()-->_PyFrame_Init()设置全局变量builtin_object. __builtin__ module Python创建的第一个module是__builtin__ module.在Py_InitializeEx()-->_PyBuiltin_Init()中实现。 PyObject* Py_InitModule4(const char *name, PyMethodDef *methods, const char *doc, PyObject *passthrough, int module_api_version) name: module的名称 methods: 该module中所包含的函数的集合 doc: module的文档 passthrough: 在Python2.5中没用,NULL module_api_version: Python内部使用的version值 该函数分两部分: 一个是创建module对象(PyImport_AddModule()),先从module pool(Python内部维护着所有加载到内存的module的dict,即interp->modules,也即sys.modules)中查看是否存在同名的module,存在则直接返回,不存在就通过PyModule_New()创建新的module对象并将(name,module)对应关系插入到module集合. 另一个是将(符号,值)对应关系放置到创建的module中。在创建__builtin__ module时,这里做的工作是:对builtin_methods中每个PyMethodDef结构,PyInitModule4()都会基于它来创建一个PyCFunctionObject对象(参加PyCFunction_NewEx函数),这个对象是Python中对函数指针(和其他信息)的包装。(PyCFunctionObject.m_module指向的是PyStringObject对象,该对象维护的是某个PyModuleObject对象的名字) 图13-5.__builtin__ module示意图 interp->builtins指向__builtin__ module维护的PyDictObject对象,省去去interp->modules中查找。 sys module interp->sysdict指向sys module维护的PyDictObject对象。 图13-6.完成sys module创建后的内存布局 interp->modules是一个PyDictObject对象,存储(module name, PyModuleObject),对于Python的标准扩展module,为防止从该dict删除后的再次初始化,Python将所有扩展module用一个全局PyDictObject对象进行备份维护(_PyImport_FixupExtension())。 sys.path是Python搜索一个module时的默认搜索路径集合(PySys_SetPath()). 初始化import机制的环境 _PyImport_Init() Py_InitializeEx()-->initmain(): 创建__main__ module,插入interp->modules 获取__main__ module中的dict 获取interp->modules中的__builtin__ module 将("__builtins__", __builtin__ module)插入__main__ module的dict中(WARNING: __builtin__ module的__name__是"__builtin__",而在__main__ module名字空间中的符号是"__builtins__") __main__ module的__name__是"__main__" 作为主程序运行的Python源文件可以被视为名为__main__的module; 以import方式加载的py文件其__name__不会是"__main__" Python交互模式下,dir()输出的结果正是__main__ module的内容 site-specific module的搜索路径 规模较大的第三方库都会放在%PythonHome%/lib/site-packages目录下,%PythonHome%/lib目录下的标准库site.py把这些第三方库加入Python的搜索路径(sys.path)中 Py_InitializeEx()-->initsite()负责加载site.py,site.py模块的工作是: 1.将site-packages路径加入到sys.path中 2.讲site-packages目录下的所有.pth文件中的所有路径加入到sys.path中 图13-9.完成初始化之后的环境 Py_Main()-->int PyRun_AnyFileExFlags(FILE *fp, const char *filename, int closeit, PyCompilerFlags *flags) 以脚本文件方式运行Python时filename就是文件名;以为交互方式运行Python时filename为NULL。 PyRun_AnyFileExFlags()内部,两种方式分道扬镳最后殊途同归一起进入了run_mod()函数 PyRun_AnyFileExFlags()-->PyRun_InteractiveLoopFlags() 交互模式运行 PyRun_InteractiveLoopFlags()-->PyRun_InteractiveOneFlags() PyParser_ASTFromFile()解析和编译输入的Python语句,构建AST(抽象语法树) 获取__main__ module维护的PyDictObject 调用run_mod()执行用户输入的语句(__main__ module维护的PyDictObject作为参数传入run_mod(),其作为虚拟机开始执行时当前活动frame对象的local和global名字空间) PyRun_AnyFileExFlags()-->PyRun_SimpleFileExFlags() 脚本文件方式运行 设置__main__ module的__file__属性 PyRun_FileExFlags()执行脚本文件 PyParser_ASTFromFile()解析和编译输入的Python语句,构建AST(抽象语法树) run_mod()做执行(传入run_mod()的local和global名字空间也是__main__ module维护的PyDictObject) static PyObject *run_mod(mod_ty mod, const char *filename, PyObject *globals, PyObject *locals, PyCompilerFlags *flags, PyArena *arena) PyAST_Compile()基于AST编译出字节码指令序列,创建PyCodeObject对象 PyEval_EvalCode()创建PyFrameObject对象,执行PyCodeObject对象中的字节码指令序列:PyEval_EvalCode()-->PyEval_EvalCodeEx() PyThreadState_GET()获取线程对象 PyFrame_New()创建PyFrameObject对象 PyEval_EvalFrameEx()执行字节码,大循环 PyFrameObject *PyFrame_New(PyThreadState *tstate, PyCodeObject *code, PyObject *globals, PyObject *locals) 设置builtin名字空间(Python所有线程共享同样的builtin名字空间) 设置global名字空间 设置local名字空间:调用函数时不用创建local名字空间;一般情况下locals和globals指向相同的dict
[第十四章]Python模块的动态加载机制 全局的module集合,作为module pool,保存了module的唯一映像,当某个.py文件通过import声明感知某个module(以某个符号的形式引入到某个名字空间)时,Python虚拟机会在这个pool中查找,如果已经存在就引入一个符号到该.py文件的名字空间,并将其关联到该module,使其透过和这个符号被.py文件感知到;如果该module不在pool中,这时Python才会执行动态加载的动作。如果要重新加载需要用builtin module中的reload操作来实现(reload背后没有创建新的module对象,这是对原有module做更新,故module的id不变)。 import import的真实含义是将某个module以某个符号的形式引入到某个名字空间。 对于内建module:Python环境初始化时加载的sys等module没有暴露在当前local名字空间,需要用户显式用import引入到local名字空间,这些预先加载的module存放在sys.modules中。 对于用户自定义module:import会创建一个新的module并引入到当前local名字空间中,而且这个被动态加载的module也会加入到sys.modules(实际上,所有的import动作,不论发生在什么时间什么地方都会影响到全局module集合;这样做有一个好处,即如果程序的另一点再次import这个module,Python虚拟机只需要将全局module集合中缓存的那个module对象返回即可)。 package module对象内部通过一个dict维护所有(属性,属性值).同class一样,module又是一个名字空间。 module管理class和函数,package管理module,多个较小的package又可以聚合成一个较大的package. module由一个单独的文件来实现(.py .pyc .dll),package由文件夹来实现。 只有文件夹中有__init__.py文件时,Python虚拟机才会认为这个文件夹是合法的package. import A.tank : 会导致当前local名字空间增加一个"A"符号代表的module对象(其实是一个package),sys.module(这个dict)中增加两个分别以“A”和“A.tank”为key、以对应module为value的元素。 import A.B.c:会导致当前local名字空间增加一个"A"符号,sys.modules中增加"A"、"A.B"、"A.B.c"; 具体过程是,分解成(A,B,c)的节点集合,从左到右依次去sys.modules中查找每个符号对应的module(A,A.B,A.B.c),如果只找到A(可能由之前的那个import A.tank引入的),就取出A对应的PyModuleObject对象中的元信息__path__(代表当前package的路径),接下来对B的搜索将只在A.__path__中进行,而不是在Python的所有搜索路径中执行。 from import as可以控制module以什么名字被引入到当前的locals(). Python运行时的全局module pool的维护和搜索 解析和搜索module路径的树状结构 对不同文件格式的module的动态加载机制 当Python虚拟机import一个package或module时,都会创建一个module对象,并且设置其__name__和__path__,只不过module对应的__path__为空罢了。vi -t PyHeapTypeObject
/* The *real* layout of a type object when allocated on the heap */
typedef struct _heaptypeobject {
/* Note: there's a dependency on the order of these members
in slotptr() in typeobject.c . */
PyTypeObject ht_type;
PyNumberMethods as_number;
PyMappingMethods as_mapping;
PySequenceMethods as_sequence; /* as_sequence comes after as_mapping,
so that the mapping wins when both
the mapping and the sequence define
a given operator (e.g. __getitem__).
see add_operators() in typeobject.c . */
PyBufferProcs as_buffer;
PyObject *ht_name, *ht_slots;
/* here are optional user slots, followed by the members. */
} PyHeapTypeObject;typedef struct wrapperbase slotdef;
struct wrapperbase {
char *name;
int offset;
void *function;
wrapperfunc wrapper;
char *doc;
int flags;
PyObject *name_strobj;
};
Py_Main()-->Py_Initialize(..)-->Py_InitializeEx(..)
PyInterpreterState结构体是对进程的模拟,PyThreadState结构体是对线程的模拟(第八章有提到)。
图13-1.Python运行时的整个环境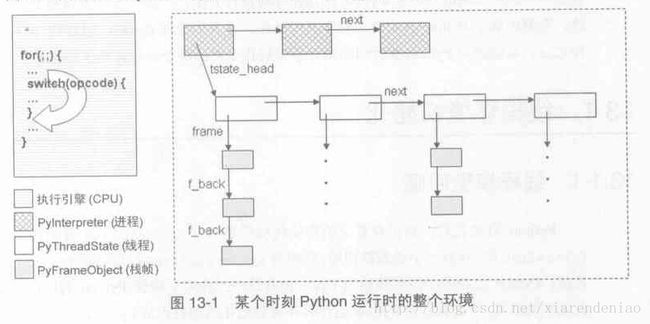
初始化线程环境

初始化Python内建exceptions _PyExc_Init()
备份exceptions module和__builtin__ module _PyImport_FixupExtension("exceptions", "exceptions"),_PyImport_FixupExtension("__builtin__","__builtin__")
在sys.module中添加一些对象用于import机制 _PyImportHooks_Init()
__main__ module
激活Python虚拟机
【黑盒测试】
dir():没有参数时打印出当前local名字空间的所有符号;有参数时将参数视为对象,输出该对象的所有属性。
sys.modules
使得Python虚拟机在当前名字空间中引入的符号尽可能的少,更好的避免名字空间遭到污染。
import A.tank as Tank
from A import tank: 当前local名字空间中增加"tank",sys.modules中增加"A"和"A.tank"。故本质上跟import A.tank一样,都是讲packet A和module A.tank动态加载到sys.modules结合中,区别在于Python会在当前local名字空间中引入什么符号。
from A.tank import a: 仅仅将module A.tank中的对象a暴露到当前local名字空间中,当前locals()中会增加一个"a",sys.modules中会增加"A"和"A.tank"(a只是module A.tank的一个对象,故sys.modules中不会有A.tank.a这样的module存在).
locals()中增加一个符号"Tank",映射module A.tank;sys.modules中增加module A和module A.tank.
【内部探测(白盒测试)】
import包含三项功能:
我门将所有import动作都归一到同一个抽象原则下:Python的import动作都发生在某一个package的环境里。
reload(xx) 不会把源文件中删除的符号从内存的module中删除,只会更新或添加新的符号,参见load_module(..)-->load_source_module(..)-->PyImport_ExecCodeModuleEx(..)
Python虚拟机初始化过程中在内部维护了一个对于内建module的备份,所有的内建module,一旦被加载之后都会拷贝一份,存到这个备份中,以后再次import时就可以不用再进行module的初始化动作,直接使用备份中缓存的module就可以了。Python对于扩展module,也做了备份。
imp module: .py源码文件中的import语句是静态的,Python也提供了动态的import机制,即在运行时动态的选择需要import的对象。imp module暴露了用于import机制的核心接口。