KafkaProducer源码解析
KafkaProducer使用示例
public class Producer extends Thread {
private final KafkaProducer producer;
private final String topic;
private final Boolean isAsync;
public Producer(String topic, Boolean isAsync) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("client.id", "DemoProducer");
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer(props);
this.topic = topic;
this.isAsync = isAsync;
}
public void run() {
int messageNo = 1;
while (true) {
String messageStr = "Message_" + messageNo;
if (isAsync) { // Send asynchronously
producer.send(new ProducerRecord(topic, messageNo, messageStr),
new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
System.out.println("The offset of the record we just sent is: " + metadata.offset());
}
}
);
} else { // Send synchronously 阻塞式,等待Future结果
producer.send(new ProducerRecord(topic, messageNo, messageStr)).get();
}
++messageNo;
}
}
}
(1)、KafkaProducer的send方法
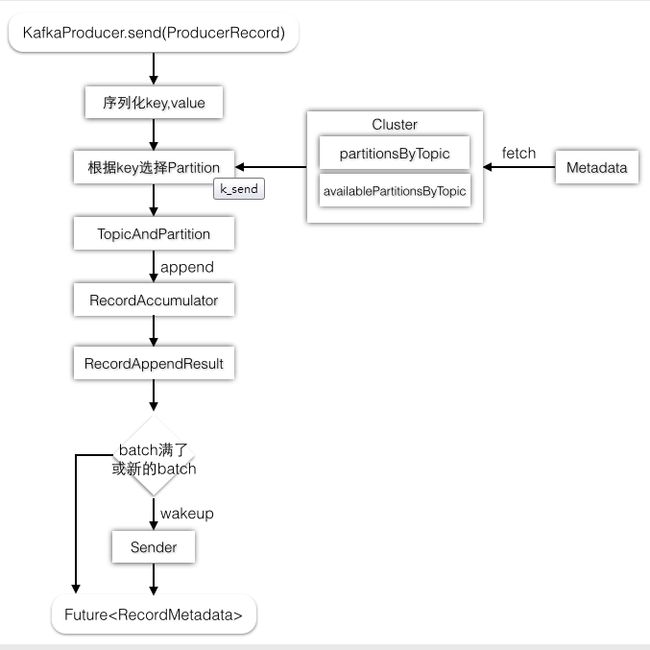
public Future send(ProducerRecord record, Callback callback) {
try {
// first make sure the metadata for the topic is available
long startTime = time.milliseconds();
waitOnMetadata(record.topic(), this.maxBlockTimeMs);
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer");
}
checkMaybeGetRemainingTime(startTime);
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer");
}
checkMaybeGetRemainingTime(startTime);
int partition = partition(record, serializedKey, serializedValue, metadata.fetch());
checkMaybeGetRemainingTime(startTime);
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
ensureValidRecordSize(serializedSize);
TopicPartition tp = new TopicPartition(record.topic(), partition);
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
long remainingTime = checkMaybeGetRemainingTime(startTime);
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, serializedKey, serializedValue, callback, remainingTime);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
throw new InterruptException(e);
} catch (BufferExhaustedException e) {
this.errors.record();
this.metrics.sensor("buffer-exhausted-records").record();
throw e;
} catch (KafkaException e) {
this.errors.record();
throw e;
}
}
(2)、Partition方法
public class PartitionInfo {
private final String topic;
private final int partition;
private final Node leader;
private final Node[] replicas;
private final Node[] inSyncReplicas;
}
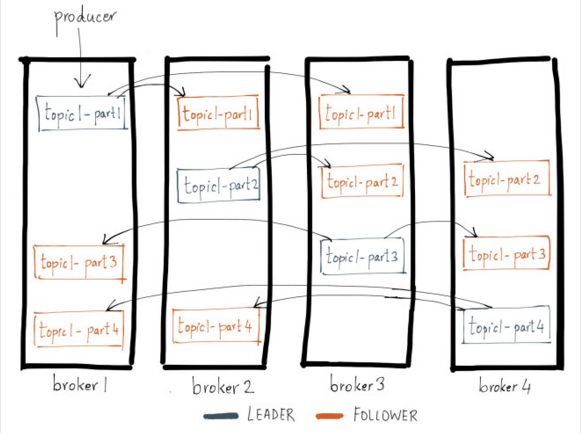
下图是kafka-manager中某个topic的PartitionInfo信息(副本数=4,Broker数量刚好也是4,导致每个Partition都分布在所有Broker上)。

topic1有4个partition。则总共有4个对应的PartitionInfo对象。每个PartitionInfo(比如topic1-part1)都有唯一的Partition编号(1),replicas(1,2,3)。
注:replicas在Partition时不需考虑,partitionsForTopic和availablePartitionsForTopic里面其实是没有follower replics的,replicas只是复制leader
//KafkaProducer
private int partition(ProducerRecord record, byte[] serializedKey , byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
if (partition != null) {
//这个topic所有的partitions. 用来负载均衡, 即Leader Partition不要都分布在同一台机器上
List partitions = cluster.partitionsForTopic(record.topic());
int numPartitions = partitions.size();
// they have given us a partition, use it
if (partition < 0 || partition >= numPartitions)
throw new IllegalArgumentException("Invalid partition given with record: " + partition
+ " is not in the range [0..."
+ numPartitions
+ "].");
return partition;
}
return this.partitioner.partition(record.topic(), record.key(), serializedKey, record.value(), serializedValue,
cluster);
}
//DefaultPartitioner,Partitioner接口的默认实现,以round-robin方式将消息平均负载到每一个Partition上
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = counter.getAndIncrement();
// 这个topic可以使用的partitions: availablePartitionsByTopic
List availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = DefaultPartitioner.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return DefaultPartitioner.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
(3)、RecordAccumulator.append 缓存中添加消息
由于生产者发送消息是异步地,所以可以将多条消息缓存起来,等到一定时机批量地写入到Kafka集群中,RecordAccumulator就扮演了缓冲者的角色。生产者每生产一条消息,就向accumulator中追加一条消息,并且要返回本次追加是否导致batch满了,如果batch满了,则开始发送这一批数据。一批消息会首先放在RecordBatch中,然后Batch又放在双端队列Deque
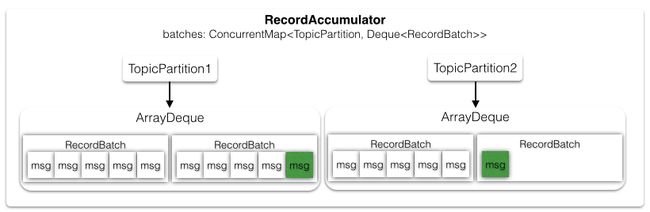
public RecordAppendResult append(TopicPartition tp, byte[] key, byte[] value, Callback callback, long maxTimeToBlock) throws InterruptedException {
// We keep track of the number of appending thread to make sure we do not miss batches in
// abortIncompleteBatches().
appendsInProgress.incrementAndGet();
try {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
// check if we have an in-progress batch
Deque dq = dequeFor(tp);
synchronized (dq) {
RecordBatch last = dq.peekLast();
if (last != null) {
// 有旧的batch, 并且能往这个batch继续追加消息
FutureRecordMetadata future = last.tryAppend(key, value, callback, time.milliseconds());
if (future != null)
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
// 队列为空(没有一个RecordBatch,last=null), 或者新的RecordBatch为空(旧的Batch没有空间了,future=null), 则新分配一个Batch
// we don't have an in-progress record batch try to allocate a new batch
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordBatch last = dq.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(key, value, callback, time.milliseconds());
if (future != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
free.deallocate(buffer);
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
// 内存的ByteBuffer, 追加新消息时,会最终写到这个ByteBuffer中
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
private Deque dequeFor(TopicPartition tp) {
Deque d = this.batches.get(tp);
if (d != null)
return d;
this.batches.putIfAbsent(tp, new ArrayDeque());
return this.batches.get(tp);
}
public FutureRecordMetadata tryAppend(byte[] key, byte[] value, Callback callback, long now) {
//RecordBatch的tryAppend判断MemoryRecords是否能容纳下新的消息,如果可以就追加,如果没有空间返回null,让调用者自己新建一个Batch。
//所以一个RecordBatch只对应了一个MemoryRecords。而一个MemoryRecords可以存放至多maxRecordSize大小的消息。
if (!this.records.hasRoomFor(key, value)) {
return null;
} else {
//此处offset是0,实际上由于消息之间都是独立的,一条消息自己是无法确定自己的offset的。
//offset是由RecordAccumulator.reday方法收集
this.records.append(0L, key, value);
this.maxRecordSize = Math.max(this.maxRecordSize, Record.recordSize(key, value));
this.lastAppendTime = now;
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount);
//客户端传递的Callback是在这里和消息一起被加入的。但是因为生产者是批量地写数据,所以回调函数是在一批数据完成后才被调用。先放入thunks
if (callback != null)
thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}
batches是一个并发安全的,但是每个TopicPartition里的ArrayDeque并不是线程安全的,所以在修改Deque时都需要同步块操作。队列中只要有一个以上的batch(dq.size),或者追加了这条消息后,当前Batch中的记录满了(batch.records),就可以发送消息了。

(4)、发送前分区信息收集
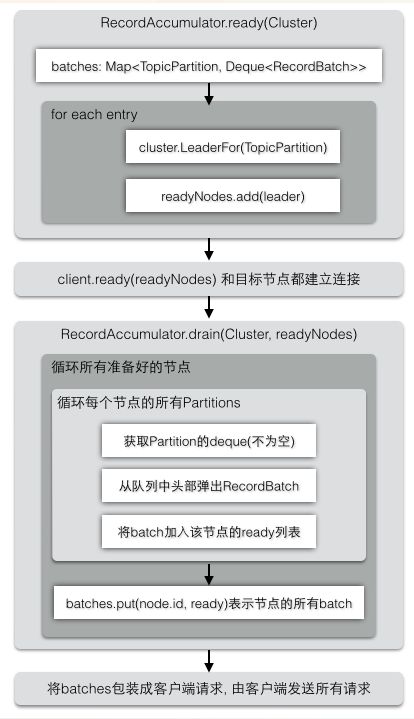
KafkaProducer的构造方法中,初始化的Sender,Sender实现Runnable接口,最终执行之中run方法
this.sender = new Sender(client,
this.metadata,
this.accumulator,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
(short) parseAcks(config.getString(ProducerConfig.ACKS_CONFIG)),
config.getInt(ProducerConfig.RETRIES_CONFIG),
this.metrics,
new SystemTime(),
clientId,
this.requestTimeoutMs);
String ioThreadName = "kafka-producer-network-thread" + (clientId.length() > 0 ? " | " + clientId : "");
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// main loop, runs until close is called
while (running) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
log.debug("Beginning shutdown of Kafka producer I/O thread, sending remaining records.");
// okay we stopped accepting requests but there may still be
// requests in the accumulator or waiting for acknowledgment,
// wait until these are completed.
while (!forceClose && (this.accumulator.hasUnsent() || this.client.inFlightRequestCount() > 0)) {
try {
run(time.milliseconds());
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
if (forceClose) {
// We need to fail all the incomplete batches and wake up the threads waiting on
// the futures.
this.accumulator.abortIncompleteBatches();
}
try {
this.client.close();
} catch (Exception e) {
log.error("Failed to close network client", e);
}
log.debug("Shutdown of Kafka producer I/O thread has completed.");
}
public void run(long now) {
Cluster cluster = metadata.fetch();
// get the list of partitions with data ready to send 获取分区信息
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// if there are any partitions whose leaders are not known yet, force metadata update
if (result.unknownLeadersExist)
this.metadata.requestUpdate();
// remove any nodes we aren't ready to send to
Iterator iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
// create produce requests
Map> batches = this.accumulator.drain(cluster,
result.readyNodes,
this.maxRequestSize,
now);
List expiredBatches = this.accumulator.abortExpiredBatches(this.requestTimeout, cluster, now);
// update sensors
for (RecordBatch expiredBatch : expiredBatches)
this.sensors.recordErrors(expiredBatch.topicPartition.topic(), expiredBatch.recordCount);
sensors.updateProduceRequestMetrics(batches);
//以节点为级别的生产请求列表. 即每个节点只有一个ClientRequest
List requests = createProduceRequests(batches, now);
// If we have any nodes that are ready to send + have sendable data, poll with 0 timeout so this can immediately
// loop and try sending more data. Otherwise, the timeout is determined by nodes that have partitions with data
// that isn't yet sendable (e.g. lingering, backing off). Note that this specifically does not include nodes
// with sendable data that aren't ready to send since they would cause busy looping.
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (result.readyNodes.size() > 0) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
log.trace("Created {} produce requests: {}", requests.size(), requests);
pollTimeout = 0;
}
for (ClientRequest request : requests)
//一个入队列的操作
client.send(request, now);
// if some partitions are already ready to be sent, the select time would be 0;
// otherwise if some partition already has some data accumulated but not ready yet,
// the select time will be the time difference between now and its linger expiry time;
// otherwise the select time will be the time difference between now and the metadata expiry time;
//这里才是真正的读写操作
this.client.poll(pollTimeout, now);
}
RecordAccumulator.ready 找到每个PartitionInfo的Leader节点
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
Set readyNodes = new HashSet();
long nextReadyCheckDelayMs = Long.MAX_VALUE;
boolean unknownLeadersExist = false;
boolean exhausted = this.free.queued() > 0;
//batches: 每个TopicPartition都对应了一个双端队列
for (Map.Entry> entry : this.batches.entrySet()) {
TopicPartition part = entry.getKey();
Deque deque = entry.getValue();
//找出这个TopicPartition的Leader节点, 在正式开始发送消息时, 会先建立到这些节点的连接
Node leader = cluster.leaderFor(part);
if (leader == null) {
unknownLeadersExist = true;
} else if (!readyNodes.contains(leader)) {
synchronized (deque) {
RecordBatch batch = deque.peekFirst();
if (batch != null) {
boolean backingOff = batch.attempts > 0 && batch.lastAttemptMs + retryBackoffMs > nowMs;
long waitedTimeMs = nowMs - batch.lastAttemptMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
boolean full = deque.size() > 1 || batch.records.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
// 加入到等待连接的节点中.
readyNodes.add(leader);
} else {
// Note that this results in a conservative estimate since an un-sendable partition may have
// a leader that will later be found to have sendable data. However, this is good enough
// since we'll just wake up and then sleep again for the remaining time.
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeadersExist);
}
RecordAccumulator.drain 对batches中的每个TopicPartition重新整理成以Node节点为级别进行包装
public Map> drain(Cluster cluster, Set nodes, int maxSize, long now) {
Map> batches = new HashMap>();
for (Node node : nodes) {
int size = 0;
List parts = cluster.partitionsForNode(node.id()); // 节点上所有的Partition
List ready = new ArrayList(); // 用来保存这个节点的Batch
int start = drainIndex = drainIndex % parts.size(); // 为了不被饿死,start并不是从0开始. 初始时,start=drainIndex
do {
PartitionInfo part = parts.get(drainIndex);
Deque deque = dequeFor(new TopicPartition(part.topic(), part.partition()));
if (deque != null) { // 并不是所有的Partition都有队列的
synchronized (deque) { // 队列不是线程安全的,需要同步块
RecordBatch first = deque.peekFirst(); // Batch加入到队列的时候是加到尾部, 拉取Batch时则从头部, 所以叫做双端队列嘛
if (first != null) {
RecordBatch batch = deque.pollFirst(); // 上面并没有把Batch从队列中删除, 如果这个Batch真的可以被消费,才真正删除(在first后做了一些判断,这里省略了)
batch.records.close(); // 释放内存
ready.add(batch); // 添加到待发送列表中
}
}
}
this.drainIndex = (this.drainIndex + 1) % parts.size();
} while (start != drainIndex); // 直到遍历完这个节点所有的Partition,说明这个节点不会有其他的Partition了,可以放心地退出循环
batches.put(node.id(), ready); // Batch是以Node为级别的.表示这个Node可以接受一批的RecordBatch. 因为每个RecordBatch的Partition都是无序的.
}
return batches;
}
(5)、Sender对Request和Response的处理
Sender的run方法代码上面提到,整个过程是这样:先①准备(ready)需要发送的partitions到哪些Nodes上,②并建立到节点的连接,然后③构造每个Node需要的RecordBatch列表(一个节点同时可以接受多批数据),④并转换为客户端的请求ClientRequest。
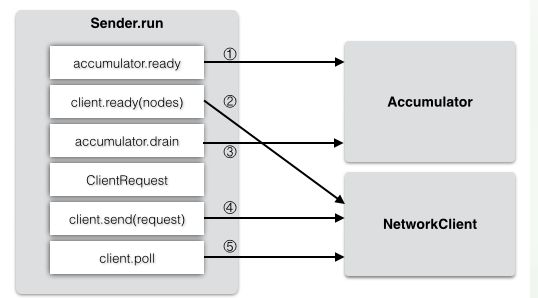


ClientRequest
ClientRequest结构
public final class ClientRequest {
private final long createdTimeMs;
private final boolean expectResponse;
private final RequestSend request;
private final RequestCompletionHandler callback;
private final boolean isInitiatedByNetworkClient;
private long sendTimeMs;
}
private List createProduceRequests(Map> collated, long now) {
List requests = new ArrayList(collated.size());
for (Map.Entry> entry : collated.entrySet())
requests.add(produceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue()));
return requests;
}
/**
* Create a produce request from the given record batches
*/
private ClientRequest produceRequest(long now, int destination, short acks, int timeout, List batches) {
Map produceRecordsByPartition = new HashMap(batches.size());
final Map recordsByPartition = new HashMap(batches.size());
for (RecordBatch batch : batches) {
// 每个RecordBatch都有唯一的TopicPartition
TopicPartition tp = batch.topicPartition;
// RecordBatch的records是MemoryRecords,底层是ByteBuffer
produceRecordsByPartition.put(tp, batch.records.buffer());
recordsByPartition.put(tp, batch);
}
// 构造生产者的请求(每个Partition都有生产记录), 并指定目标节点,请求头和请求内容, 转换为发送请求对象
ProduceRequest request = new ProduceRequest(acks, timeout, produceRecordsByPartition);
RequestSend send = new RequestSend(Integer.toString(destination),
this.client.nextRequestHeader(ApiKeys.PRODUCE),
request.toStruct());
// 回调函数会作为客户端请求的一个成员变量, 当客户端请求完成后, 会触发回调函数的执行!
//callback回调中执行handleProduceResponse
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
return new ClientRequest(now, acks != 0, send, callback);
}
回调函数传给了ClientRequest客户端请求,当客户端真正发生读写后(poll),会产生ClientResponse对象,触发回调函数的执行。因为回调对象RequestCompletionHandler的回调方法onComplete的参数是ClientResponse。NetworkClient.poll是真正发生读写的地方,所以它也会负责生成客户端的响应信息。

public class ClientResponse {
private final long receivedTimeMs;
private final boolean disconnected;
private final ClientRequest request;
private final Struct responseBody;
}
//真正的读写操作,生成responses
public List poll(long timeout, long now) {
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
//selector.poll方法,进行NIO的轮询操作
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
long updatedNow = this.time.milliseconds();
List responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleTimedOutRequests(responses, updatedNow);
// invoke callbacks
for (ClientResponse response : responses) {
if (response.request().hasCallback()) {
try {
response.request().callback().onComplete(response);
} catch (Exception e) {
log.error("Uncaught error in request completion:", e);
}
}
}
return responses;
}
回调执行的handleProduceResponse方法
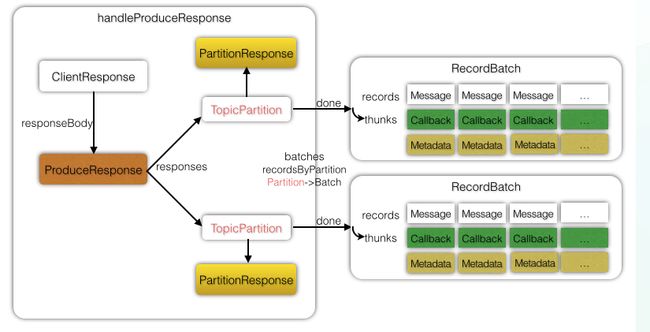
private void handleProduceResponse(ClientResponse response, Map batches, long now) {
int correlationId = response.request().request().header().correlationId();
if (response.wasDisconnected()) {
log.trace("Cancelled request {} due to node {} being disconnected", response, response.request()
.request()
.destination());
for (RecordBatch batch : batches.values())
completeBatch(batch, Errors.NETWORK_EXCEPTION, -1L, correlationId, now);
} else {
log.trace("Received produce response from node {} with correlation id {}",
response.request().request().destination(),
correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
ProduceResponse produceResponse = new ProduceResponse(response.responseBody());
for (Map.Entry entry : produceResponse.responses() .entrySet()) {
TopicPartition tp = entry.getKey();// 每一个TopicPartition都对应一个PartitionResponse
ProduceResponse.PartitionResponse partResp = entry.getValue();
Errors error = Errors.forCode(partResp.errorCode);
RecordBatch batch = batches.get(tp);
completeBatch(batch, error, partResp.baseOffset, correlationId, now);
}
this.sensors.recordLatency(response.request().request().destination(), response.requestLatencyMs());
this.sensors.recordThrottleTime(response.request().request().destination(),
produceResponse.getThrottleTime());
} else {
// this is the acks = 0 case, just complete all requests
for (RecordBatch batch : batches.values())
completeBatch(batch, Errors.NONE, -1L, correlationId, now);
}
}
}
private void completeBatch(RecordBatch batch, Errors error, long baseOffset, long correlationId, long now) {
if (error != Errors.NONE && canRetry(batch, error)) {
// retry
log.warn("Got error produce response with correlation id {} on topic-partition {}, retrying ({} attempts left). Error: {}",
correlationId,
batch.topicPartition,
this.retries - batch.attempts - 1,
error);
this.accumulator.reenqueue(batch, now);
this.sensors.recordRetries(batch.topicPartition.topic(), batch.recordCount);
} else if (error == Errors.TOPIC_AUTHORIZATION_FAILED) {
batch.done(baseOffset, new TopicAuthorizationException(batch.topicPartition.topic()));
} else {
// tell the user the result of their request
batch.done(baseOffset, error.exception());
this.accumulator.deallocate(batch);
if (error != Errors.NONE)
this.sensors.recordErrors(batch.topicPartition.topic(), batch.recordCount);
}
if (error.exception() instanceof InvalidMetadataException)
metadata.requestUpdate();
}
public void done(long baseOffset, RuntimeException exception) {
log.trace("Produced messages to topic-partition {} with base offset offset {} and error: {}.",
topicPartition,
baseOffset,
exception);
// execute callbacks
for (int i = 0; i < this.thunks.size(); i++) {
try {
Thunk thunk = this.thunks.get(i);
if (exception == null) {
RecordMetadata metadata = new RecordMetadata(this.topicPartition, baseOffset, thunk.future.relativeOffset());
thunk.callback.onCompletion(metadata, null);
} else {
thunk.callback.onCompletion(null, exception);
}
} catch (Exception e) {
log.error("Error executing user-provided callback on message for topic-partition {}:", topicPartition, e);
}
}
this.produceFuture.done(topicPartition, baseOffset, exception);
}
(6)、消息发送的底层实现

refer:
http://zqhxuyuan.github.io/2016/01/06/2016-01-06-Kafka_Producer/