ORACLE 数据同步 容灾备份恢复 主从架构 读写分离 (OGG,ADG,DSG,高级复制,流复制,logmnr)
ORACLE 几种同步灾备手段(OGG,ADG,DSG,高级复制,流复制,logmnr)
2017年07月14日 13:45:47 小学生汤米 阅读数:11073
目前所接触的Oracle 的灾备以及同步手段主要有ADG,OGG,DSG,高级复制,流复制以及自主开发的基于logmnr的数据同步软件,各有优劣。各自评价如下:
1. ADG,最常用的同城,异地灾备解决方案,物理级备份,备机不可写,传输数据为所有redo日志的更改,数据量稍大,不过从以往的使用经验来看,也不太会影响网络,除非应用对网络有很苛刻的要求,即使有,也可以通过vlan或者路由或者多网卡的方法特别建立网络通道,主备库完全一致,缺点是必须全库备份。
2. OGG,DSG这两个我觉得是一个类型的,逻辑备份,主要采用特有的技术从联机日志中抽取更改项应用到备库,主备库为两个库,可以全库同步也可以同步单张表或数张表,同步速度较快,传输数据量很少,DML操作和DDL操作均支持。
3. 高级复制 仅支持DML操作,DDL操作不支持,切升级后表要重新配置,同步数据量也较少。10g,11g有用于做同步灾备使用,但是bug超级多,问题超级多。Oracle12c的说明里已经不再有高级复制这个组件
4. 流复制 Oracle收购ogg之前主推的同步手段,没用过,不了解。目前也已被抛弃,12c的说明里已经明确说明对流复制不会继续更新补丁。但是仍会有此产品。
5. 基于自主开发的logmnr数据同步:这个优势很大,劣势也很大,毕竟Oracle有独立的同步程序,因此logmnr就被oracle刻意的设置了很多对数据库同步不利的地方,我先说优势,由于是自主开发的,可以自主设置同步手段,设置同步策略(比如推送,还是拉取),设置是否接受等等,能够很方便的开发管理界面。劣势也非常明显,logmnr的每次调用都会记录到alert日志中,这对Oracle的运维是极其不利的,而且logmnr对cpu和io的占用消耗很大,非常明显。
https://blog.csdn.net/gaobudong1234/article/details/75105773
Oracle数据库--读写分离架构
2016年09月24日 18:29:25 梦想之天堂 阅读数:10510
采用Oracle读写分离的思路,Writer DB和Reader DB采用日志复制软件实现实时同步; Writer DB负责交易相关的实时查询和事务处理,Reader DB负责只读接入,处理一些非实时的交易明细,报表类的汇总查询等。同时,为了满足高可用性和扩展性等要求,对读写端适当做外延,比如Writer DB采用HA或者RAC的架构模式,Reader DB可以采用多套,通过负载均衡或者业务分离的方式,有效分担读库的压力。
对于Shared-nothing的数据库架构模式,核心的一个问题就是读写库的实时同步;另外,虽然Reader DB只负责业务查询,但并不代表数据库在功能上是只读的。只读是从应用角度出发,为了保证数据一致和冲突考虑,因为查询业务模块可能需要涉及一些中间处理,如果需要在数据库里面处理(取决与应用需求和设计),所以Reader DB在功能上仍然需要可写。
下面谈一下数据同步的技术选型问题:
能实现数据实时同步的技术很多,基于OS层(例如VERITAS VVR),基于存储复制(中高端存储大多都支持),基于应用分发或者基于数据库层的技术。因为数据同步可能并不是单一的DB整库同步,会涉及到业务数据选择以及多源整合等问题,因此OS复制和存储复制多数情况并不适合做读写分离的技术首选。
基于日志的Oracle复制技术,Oracle自身组件可以实现,同时也有成熟的商业软件。选商业的独立产品还是Oracle自身的组件功能,这取决于多方面的因素。比如团队的相应技术运维能力、项目投入成本、业务系统的负载程度等。
采用Oracle自身组件功能,无外乎Logical Standby、Stream以及11g的Physical Standby(Active Data Guard),对比来说,Stream最灵活,但最不稳定,11g Physical Standby支持恢复与只读并行,但由于并不是日志的逻辑应用机制,在读写分离的场景中最为局限。如果技术团队对相关技术掌握足够充分,而选型方案的处理能力又能支撑数据同步的要求,采用Oracle自身的组件完全可行。
选择商业化的产品,更多出于稳定性、处理能力等考虑。市面上成熟的Oracle复制软件也无外乎几种,无论是老牌的Shareplex,还是本土DSG公司的RealSync和九桥公司的DDS,或是Oracle新贵Goldengate,都是可供选择的目标。随着GoldenGate被Oracle收购和推广,个人认为GoldenGate在容灾、数据分发和同步方面将大行其道。
当然,架构好一个可靠的分布式读写分离的系统,还需要应用上做大量设计,不在本文讨论范围内。
https://blog.csdn.net/hunsoft/article/details/52652498
Oracle11g三种数据同步方式
2017年12月15日 14:21:57 totoroKing 阅读数:5781
DataGurd:
主要备库的方式,就是数据库对数据库的备份方式,主要是解决容灾的。
流复制:
主要是利用ORACLE的归档日志,进行增量备份来实现的,不仅可以配置只复制某些表,还可以配置仅复制某些表上的ddl或dml。可以复制到表,用户,数据库级别。
高级复制:
主要是基于触发器的原理来触发数据同步的,因此,高级复制无法实现用户,数据库级别的对象复制,只能做些表、索引和存储过程的复制。
如果出于容灾整个数据库的考虑,高级复制相当复杂,而且并不一定能做好,流复制的配置相对简单。流复制是后来产生的复制技术,是基于日志挖掘技术实现的,对数据库的影响较低。但在稳定性方面较差,实时性没有高级复制强(因为高级复制是基于触发器的)。如果系统意外的话,流复制的恢复将会需要较长时间,特别是意外时间越长,恢复时间成倍增长。
PS:以上配置均能在oracle11g的EM图形界面上配置,看似简单不用输入太多的命令行,但是目前相关教程很少,有的也大度是10g以前的版本,所有建议还是使用命令行的方式。
https://blog.csdn.net/qq_30553235/article/details/78812610
Oracle读写分离架构
读写分离是架构分布式系统的一个重要思想。不少系统整体处理能力并不能同业务的增长保持同步,因此势必会带来瓶颈,单纯的升级硬件并不能一劳永逸。针对业务类型特点,需要从架构模式上进行一系列的调整,比如业务模块的分割,数据库的拆分等等。
集中式和分布式是两个对立的模式,不同行业的应用特点也决定了架构的思路。如互联网行 业中一些门户站点,出于技术和成本等方面考虑,更多的采用开源的数据库产品(如MYSQL),由于大部分是典型的读多写少的请求,因此为MYSQL及其复 制技术大行其道提供了条件。而相对一些传统密集交易型的行业,比如电信业、金融业等,考虑到单点处理能力和可靠性、稳定性等问题,可能更多的采用商用数据 库,比如DB2、Oracle等。
就数据库层面来讲,大部分传统行业核心库采用集中式的架构思路,采用高配的小型机做主机载体,因为数据库本身和主机强大的处理能力,数据库端一般能支撑业务的运转,因此,Oracle读写分离式的架构相对MYSQL来讲,相对会少。
前段时间一直在规划公司新的数据库架构,考虑到我们的业务特点,采用Oracle读写分离的思路,Writer DB和Reader DB采用日志复制软件实现实时同步; Writer DB负责交易相关的实时查询和事务处理,Reader DB负责只读接入,处理一些非实时的交易明细,报表类的汇总查询等。同时,为了满足高可用性和扩展性等要求,对读写端适当做外延,比如Writer DB采用HA或者RAC的架构模式,Reader DB可以采用多套,通过负载均衡或者业务分离的方式,有效分担读库的压力。
对于Shared-nothing的数据库架构模式,核心的一个问题就是读写库的实时同步;另外,虽然Reader DB只负责业务查询,但并不代表数据库在功能上是只读的。只读是从应用角度出发,为了保证数据一致和冲突考虑,因为查询业务模块可能需要涉及一些中间处 理,如果需要在数据库里面处理(取决与应用需求和设计),所以Reader DB在功能上仍然需要可写。
下面谈一下数据同步的技术选型问题:
能实现数据实时同步的技术很多,基于OS层(例如VERITAS VVR),基于存储复制(中高端存储大多都支持),基于应用分发或者基于数据库层的技术。因为数据同步可能并不是单一的DB整库同步,会涉及到业务数据选择以及多源整合等问题,因此OS复制和存储复制多数情况并不适合做读写分离的技术首选。
基于日志的Oracle复制技术,Oracle自身组件可以实现,同时也有成熟的商业软件。选商业的独立产品还是Oracle自身的组件功能,这取决于多方面的因素。比如团队的相应技术运维能力、项目投入成本、业务系统的负载程度等。
采用Oracle自身组件功能,无外乎Logical Standby、Stream以及11g的Physical Standby(Active Data Guard),对比来说,Stream最灵活,但最不稳定,11g Physical Standby支持恢复与只读并行,但由于并不是日志的逻辑应用机制,在读写分离的场景中最为局限。如果技术团队对相关技术掌握足够充分,而选型方案的处 理能力又能支撑数据同步的要求,采用Oracle自身的组件完全可行。
选择商业化的产品,更多出于稳定性、处理能力等考虑。市面上成熟的Oracle复制软件也无外乎几种,无论是老牌的Shareplex,还是本土DSG公 司的RealSync和九桥公司的DDS,或是Oracle新贵Goldengate,都是可供选择的目标。随着GoldenGate被Oracle收购 和推广,个人认为GoldenGate在容灾、数据分发和同步方面将大行其道。
当然,架构好一个可靠的分布式读写分离的系统,还需要应用上做大量设计,不在本文讨论范围内。
分类: oracle
http://www.cnblogs.com/karmapeng/p/4409235.html
Oracle数据库备份与恢复的三种方法
2018年01月03日 10:09:25 kepa520 阅读数:17227更多
个人分类: Oracle
原文地址:https://www.2cto.com/database/201307/227723.html
Oracle数据库有三种标准的备份方法,它们分别是导出/导入(EXP/IMP)、热备份和冷备份。导出备件是一种逻辑备份,冷备份和热备份是物理备份。
一、 导出/导入(Export/Import)
利用Export可将数据从数据库中提取出来,利用Import则可将提取出来的数据送回到Oracle数据库中去。
1、 简单导出数据(Export)和导入数据(Import)
Oracle支持三种方式类型的输出:
(1)、表方式(T方式),将指定表的数据导出。
(2)、用户方式(U方式),将指定用户的所有对象及数据导出。
(3)、全库方式(Full方式),瘵数据库中的所有对象导出。
数据导入(Import)的过程是数据导出(Export)的逆过程,分别将数据文件导入数据库和将数据库数据导出到数据文件。
2、 增量导出/导入
增量导出是一种常用的数据备份方法,它只能对整个数据库来实施,并且必须作为SYSTEM来导出。在进行此种导出时,系统不要求回答任何问题。导出文件名缺省为export.dmp,如果不希望自己的输出文件定名为export.dmp,必须在命令行中指出要用的文件名。
增量导出包括三种类型:
(1)、“完全”增量导出(Complete)
即备份三个数据库,比如:
exp system/manager inctype=complete file=040731.dmp
(2)、“增量型”增量导出
备份上一次备份后改变的数据,比如:
exp system/manager inctype=incremental file=040731.dmp
(3)、“累积型”增量导出
累计型导出方式是导出自上次“完全”导出之后数据库中变化了的信息。比如:
exp system/manager inctype=cumulative file=040731.dmp
数据库管理员可以排定一个备份日程表,用数据导出的三个不同方式合理高效的完成。
比如数据库的被封任务可以做如下安排:
星期一:完全备份(A)
星期二:增量导出(B)
星期三:增量导出(C)
星期四:增量导出(D)
星期五:累计导出(E)
星期六:增量导出(F)
星期日:增量导出(G)
如果在星期日,数据库遭到意外破坏,数据库管理员可按一下步骤来回复数据库:
第一步:用命令CREATE DATABASE重新生成数据库结构;
第二步:创建一个足够大的附加回滚。
第三步:完全增量导入A:
imp system/manager inctype=RESTOREFULL=y FILE=A
第四步:累计增量导入E:
imp system/manager inctype=RESTOREFULL=Y FILE=E
第五步:最近增量导入F:
imp system/manager inctype=RESTOREFULL=Y FILE=F
二、 冷备份
冷备份发生在数据库已经正常关闭的情况下,当正常关闭时会提供给我们一个完整的数据库。冷备份时将关键性文件拷贝到另外的位置的一种说法。对于备份Oracle信息而言,冷备份时最快和最安全的方法。冷备份的优点是:
1、 是非常快速的备份方法(只需拷文件)
2、 容易归档(简单拷贝即可)
3、 容易恢复到某个时间点上(只需将文件再拷贝回去)
4、 能与归档方法相结合,做数据库“最佳状态”的恢复。
5、 低度维护,高度安全。
但冷备份也有如下不足:
1、 单独使用时,只能提供到“某一时间点上”的恢复。
2、 再实施备份的全过程中,数据库必须要作备份而不能作其他工作。也就是说,在冷备份过程中,数据库必须是关闭状态。
3、 若磁盘空间有限,只能拷贝到磁带等其他外部存储设备上,速度会很慢。
4、 不能按表或按用户恢复。
如果可能的话(主要看效率),应将信息备份到磁盘上,然后启动数据库(使用户可以工作)并将备份的信息拷贝到磁带上(拷贝的同时,数据库也可以工作)。冷备份中必须拷贝的文件包括:
1、 所有数据文件
2、 所有控制文件
3、 所有联机REDO LOG文件
4、 Init.ora文件(可选)
值得注意的使冷备份必须在数据库关闭的情况下进行,当数据库处于打开状态时,执行数据库文件系统备份是无效的。
下面是作冷备份的完整例子。
(1) 关闭数据库
sqlplus /nolog sql>;connect /as sysdba sql>;shutdown normal;
(2) 用拷贝命令备份全部的时间文件、重做日志文件、控制文件、初始化参数文件
{$PageTitle=sql>;cp ; ;}
(3) 重启Oracle数据库
sql>;startup
三、 热备份
热备份是在数据库运行的情况下,采用archivelog mode方式备份数据库的方法。所以,如果你有昨天夜里的一个冷备份而且又有今天的热备份文件,在发生问题时,就可以利用这些资料恢复更多的信息。热备份要求数据库在Archivelog方式下操作,并需要大量的档案空间。一旦数据库运行在archivelog状态下,就可以做备份了。热备份的命令文件由三部分组成:
1. 数据文件一个表空间一个表空间的备份。
(1) 设置表空间为备份状态
(2) 备份表空间的数据文件
(3) 回复表空间为正常状态
2. 备份归档log文件
(1) 临时停止归档进程
(2) log下那些在archive rede log目标目录中的文件
(3) 重新启动archive进程
(4) 备份归档的redo log文件
3. 用alter database bachup controlfile命令来备份控制文件
热备份的优点是:
1. 可在表空间或数据库文件级备份,备份的时间短。
2. 备份时数据库仍可使用。
3. 可达到秒级恢复(恢复到某一时间点上)。
4. 可对几乎所有数据库实体做恢复
5. 恢复是快速的,在大多数情况下爱数据库仍工作时恢复。
热备份的不足是:
1. 不能出错,否则后果严重
2. 若热备份不成功,所得结果不可用于时间点的恢复
3. 因难于维护,所以要特别仔细小心,不允许“以失败告终”。
https://blog.csdn.net/kepa520/article/details/78958255
Oracle Golden Gate - 概念和机制 (ogg)
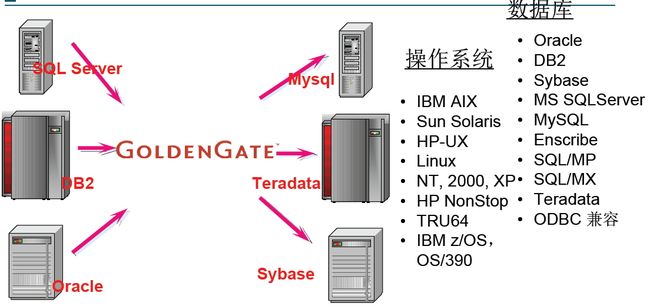
Golden Gate(简称OGG)提供异构环境下交易数据的实时捕捉、变换、投递。

OGG支持的异构环境有:
OGG的特性:
- 对生产系统影响小:实时读取交易日志,以低资源占用实现大交易量数据实时复制
- 以交易为单位复制,保证交易一致性:只同步已提交的数据
- 高性能
- 智能的交易重组和操作合并
- 使用数据库本地接口访问
- 并行处理体系
- 灵活的拓扑结构:支持一对一、一对多、多对一、多对多和双向复制等
- 支持数据过滤和转换
- 可以自定义基于表和行的过滤规则.
- 可以对实时数据执行灵活影射和变换.
- 提供数据压缩和加密:降低传输所需带宽,提高传输安全性.
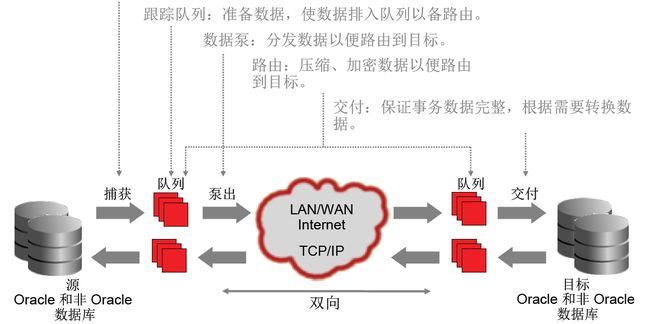
OGG的工作原理:
OGG的进程:
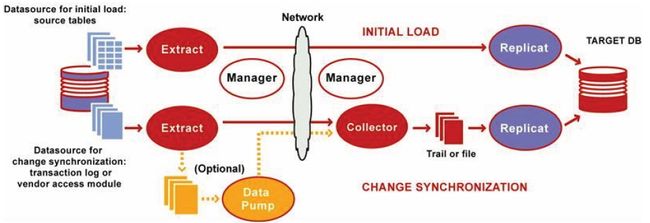
- Manager进程是GoldenGate的控制进程,运行在源端和目标端上。它主要作用有以下几个方面:启动、监控、重启Goldengate的其他进程,报告错误及事件,分配数据存储空间,发布阀值报告等。在目标端和源端有且只有一个manager进程
- Extract运行在数据库源端,负责从源端数据表或者日志中捕获数据。Extract的作用可以按照阶段来划分为:
- 初始时间装载阶段:在初始数据装载阶段,Extract进程直接从源端的数据表中抽取数据
- 同步变化捕获阶段:初始数据同步完成以后,Extract进程负责捕获源端数据的变化(DML和DDL)
- Data Pump进程运行在数据库源端,其作用是将源端产生的本地trail文件,把trail以数据块的形式通过TCP/IP 协议发送到目标端,这通常也是推荐的方式。pump进程本质是extract进程的一种特殊形式,如果不使用trail文件,那么extract进程在抽 取完数据以后,直接投递到目标端,生成远程trail文件。
- Collector进程与Data Pump进程对应 的叫Server Collector进程,这个进程不需要引起我的关注,因为在实际操作过程中,无需我们对其进行任何配置,所以对我们来说它是透明的。它运行在目标端,其 任务就是把Extract/Pump投递过来的数据重新组装成远程ttrail文件。
- Replicat进程,通常我们也把它叫做应用进程。运行在目标端,是数据传递的最后一站,负责读取目标端trail文件中的内容,并将其解析为DML或 DDL语句,然后应用到目标数据库中。
关于OGG的Trail文件:
-
- 为了更有效、更安全的把数据库事务信息从源端投递到目标端。GoldenGate引进trail文件的概念。前面提到extract抽取完数据以 后 Goldengate会将抽取的事务信息转化为一种GoldenGate专有格式的文件。然后pump负责把源端的trail文件投递到目标端,所以源、 目标两端都会存在这种文件。
- trail文件存在的目的旨在防止单点故障,将事务信息持久化,并且使用checkpoint机制来记录其读写位置,如果故障发生,则数据可以根据checkpoint记录的位置来重传 。
https://www.cnblogs.com/qiumingcheng/p/5435907.html
ORACLE读写分离(注:根据网上资料搭建完成步奏总结)
置顶 2018年07月02日 14:20:01 is-One 阅读数:1243
版权声明: https://blog.csdn.net/qq_20544709/article/details/80883571
研究问题:
1. 什么是读写分离?
2. 为什么要做读写分离?
3. ORACLE读写分离的方式,各有优缺点?
4. 详解其中一种ORACLE读写分离方式。
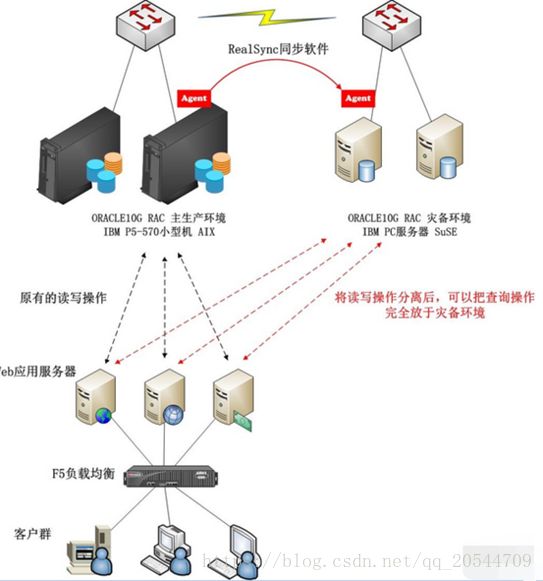
一、 什么是读写分离?
如图:
|
|
Ø 官方定义
为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台 数据库服务器,是对外提供增删改业务的生产服务器;第二台数据库服务器,主要进 行读的操作。
Ø 我的理解
2台数据库服务器,其中一台数据库服务器进行数据写入操作,另一台数据库服 务器进行数据的读取。2台数据库之间数据要进去快速的数据同步。
二、 为什么要做读写分离?
因为数据库的“写”(写10000条数据到oracle可能要3分钟)操作是比较耗时的。
但是数据库的“读”(从oracle读10000条数据可能只要5秒钟)。
所以读写分离,解决的是,数据库的写入,影响了查询的效率。
a、读写分离的好处
1) 增加冗余
2) 增加了机器的处理能力
3) 对于读操作为主的应用,使用读写分离是最好的场景,因为可以确保写的服务器压力更小,而读又可以接受点时间上的延迟。
b、读写分离提高性能之原因
1) 物理服务器增加,负荷增加
2) 主从只负责各自的写和读,极大程度的缓解X锁和S锁争用①
3) 从库同步主库的数据和主库直接写还是有区别的,通过主库发送来的binlog恢复数据,但是,最重要区别在于主库向从库发送binlog是异步的,从库恢复数据也是异步的
4) 读写分离适用与读远大于写的场景,如果只有一台服务器,当select很多时,update和delete会被这些select访问中的数据堵塞,等待select结束,并发性能不高。 对于写和读比例相近的应用,应该部署双主相互复制
5) 可以在从库启动是增加一些参数来提高其读的性能,当然这些设置也是需要根据具体业务需求来定得,不一定能用上
6) 分摊读取。假如我们有1主3从,不考虑上述1中提到的从库单方面设置,假设现在1 分钟内有10条写入,150条读取。那么,1主3从相当于共计40条写入,而读取总数没变,因此平均下来每台服务器承担了10条写入和50条读取(主库不 承担读取操作)。因此,虽然写入没变,但是读取大大分摊了,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了,说白了就是拿机器和带宽换性能。
7) 复制另外一大功能是增加冗余,提高可用性,当一台数据库服务器宕机后能通过调整另外一台从库来以最快的速度恢复服务,因此不能光看性能,也就是说1主1从也是可以的。
三、 ORACLE读写分离的方式,各有优缺点?
读写分离的重点其实就是数据同步,能实现数据实时同步的技术很多,基于OS层(例如VERITAS VVR),基于存储复制(中高端存储大多都支持),基于应用分发或者基于数据库层的技术。因为数据同步可能并不是单一的DB整库同步,会涉及到业务数据选择以及多源整合等问题,因此OS复制和存储复制多数情况并不适合做读写分离的技术首选。
基于日志的Oracle复制技术,Oracle自身组件可以实现,同时也有成熟的商业软件。选商业的独立产品还是Oracle自身的组件功能,这取决于多方面的因素。比如团队的相应技术运维能力、项目投入成本、业务系统的负载程度等。
a、主从同步
a.1、采用Oracle自身组件功能
无外乎Logical Standby、Stream以及11g的Physical Standby(Active Data Guard),对比来说,Stream最灵活,但最不稳定,11g Physical Standby支持恢复与只读并行,但由于并不是日志的逻辑应用机制,在读写分离的场景中最为局限。如果技术团队对相关技术掌握足够充分,而选型方案的处理能力又能支撑数据同步的要求,采用Oracle自身的组件完全可行。
a.1.1、DG方案
DG方案也叫ADG方案,英语全称Physical Standby(Active DataGuard)。支持恢复与只读并行,但由于并不是日志的逻辑应用机制,在读写分离的场景中最为局限 ,将生产机的logfiles传递给容灾机,通过Redo Apply技术来保障数据镜像能力,物理上提供了与生产数据库在数据块级的一致性镜像,也叫physical方式。Physical方式支持异步传输方式,但容灾机处在恢复状态,不可用;
a.1.2、Logical Standby
通过SQL Apply(即Log Miner)技术,将接收到的日志文件还原成SQL语句,并在逻辑备份数据库上执行,从而达到数据一致性的目的,也叫logical 方式。logical方式只支持同步传输方式,但容灾机可以处在read-only状态
a.1.3、Stream
最灵活,但最不稳定
a.2、选择商业化的产品
更多出于稳定性、处理能力等考虑。市面上成熟的Oracle复制软件也无外乎几种,无论是老牌的Shareplex,还是本土DSG公司的RealSync和九桥公司的DDS,或是Oracle新贵GoldenGate,都是可供选择的目标。随着GoldenGate被Oracle收购和推广,个人认为GoldenGate在容灾、数据分发和同步方面将大行其道。
b、读写分离
b.1、数据库中间键mycat 实现oracle数据库读写分离
b.1.1、下载mycat
| wget https://github.com/MyCATApache/Mycat-download/blob/master/1.4-RELEASE/Mycat-server-1.4-release-20151019230038-linux.tar.gz
|
b.1.2、解压
| tar -zxvf Mycat-server-1.4-release-20151019230038-linux.tar.gz
|
b.1.3、配置环境变量:
| vi /etc/profile
末尾加上
MYCAT_HOME=/MyCat/mycat //mycat安装路径
PATH=$PATH:$MYCAT_HOME/bin
export MYCAT_HOME PATH
|
b.1.4、修改配置文件
| /MyCat/mycat/conf/wrapper.conf
修改
wrapper.java.command= /usr/java/jdk1.7.0_80/bin/java //修改wrapper.java.command 为jdk的bin目录下的java
|
b.1.5、设置mycat用户名和密码
修改配置文件/MyCat/mycat/conf/server.xml
|
|
b.1.6、修改配置文件/MyCat/mycat/conf/schema.xml
|
<dataNode name="dn1" dataHost="localhost1" database="db1" />
表空间名称 -->
|
配置结束
b.1.7、启动mycat
| mycat start
|
可以查看日志文件看是否报错/MyCat/mycat/logs/mycat.log
启动报错,导入ojdbc7到mycat的lib目录下
b.1.8、测试
用navicat客户端连接mycat (ip为mycat所在的服务器ip,用户名和密码是在server.xml中配置的user)
|
|
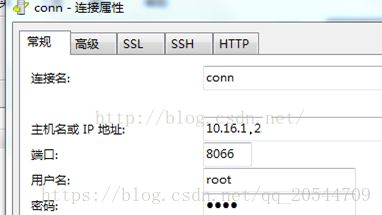
navcat for mysql客户端 可能会连接不上报2003-can't connect to mysql server on 10038
需要配置防火墙开启8066端口
| vi /etc/sysconfig/iptables #编辑防火墙配置文件,添加以下内容
-A INPUT -m state --state NEW -m tcp -p tcp --dport 8066 -j ACCEPT
/etc/init.d/iptables restart #重启防火墙使配置生效
|
b.1.9、程序中配置如下
|
|
b.1.10、相关命令
| 关闭mycat mycat stop
查看mycat状态 mycat status
|
四、 ADG
a、软件环境准备
2个oracle数据库服务器,做单例数据库的读写分离。安装配置略
2个rac数据库服务器。做集群环境的读写分离。安装配置略
b、安装配置前检查
单例数据库的读写分离,检测2个oracle服务器宿主机是否安装oracle数据库,是否配置和版本等等一致。安装配置略
Rac集群数据库的读写分离,分别检测2个rac集群数据库是环境配置、oracle版本等一致。安装配置略
相关信息
|
|
IP地址规划:
|
SID:
|
db_name:
|
db_unique_name
|
| 主数据库
|
192.168.11.120
|
pri
|
pri
|
pri
|
| 备份数据库
|
192.168.11.121
|
std
|
pri
|
std
|
注意:dbname要配置成一样的,并且关闭防火墙。
环境变量:指向oracle安装的目录
| export ORACLE_BASE=/u01/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/11.2.0/db_1
export ORACLE_SID=pri (备库端设置为std)
export LD_LIBRARY_PATH=$ORACLE_HOME/bin:/bin:/usr/bin:/usr/local/bin:
export CLASSPATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib
export PATH=$ORACLE_HOME/bin:$PATH
|
c、安装配置
注意:主库需要建好库(执行dbca),备库不需要。
c.1、将数据库改为强制日志模式 (主库)
[oracle@pri ~]$sqlplus / as sysdba
查看当前是否强制日志模式:
SYS@pri>select name,log_mode,force_logging from v$database;
| NAME LOG_MODE FOR
--------- ------------ ---
PRI NOARCHIVELOG NO
|
SYS@pri>alter database force logging;
成功后再次查看
SYS@pri> select name,log_mode,force_logging fromv$database;
| NAME LOG_MODE FOR
--------- ------------ ---
PRI NOARCHIVELOG YES
|
c.2、创建密码文件 (主库)
注意:两端分别创建自己的密码文件好像有问题,备库的密码文件需要跟主库一致,否则导致日志传输不到备库,有待验证。我最后是将主库的密码文件直接copy到备库,重命名后使用。
[oracle@pri~]$ cd $ORACLE_HOME/dbs
[oracle@pridbs]$ ls
| hc_pri.dat init.ora initpri.ora lkPRI orapwpri snapcf_pri.f spfilepri.ora
|
已经有一个密码文件了
[oracle@pridbs]$ orapwd file=orapwpri password=oracle force=y
这条命令可以手动生成密码文件,force=y的意思是强制覆盖当前已有的密码文件(如果有可以不建立) file= :文件名 password=:数据库超级管理员即sys用户的密码
将主库的密码文件copy给备库,并重命名
[oracle@pri dbs]$ scp orapwpri192.168.11.121:$ORACLE_HOME/dbs/orapwstd
c.3、创建standby redolog日志组 (主库)
注意:standby redo log的文件大小与primary 数据库online redo log 文件大小相同。standby redo log日志文件组的个数依照下面的原则进行计算:Standby redo log组数公式>=(每个instance日志组个数+1)*instance个数,假如只有一个节点,这个节点有三组redolog,所以Standby redo log组数>=(3+1)*1 == 4,所以至少需要创建4组Standby redo log
查看当前线程与日志组的对应关系及日志组的大小:
SYS@pri>select thread#,group#,bytes/1024/1024 from v$log;
| THREAD# GROUP# BYTES/1024/1024
--------------- ------------- ------------------------
1 1 50
1 2 50
1 3 50
|
如上,我现在的环境有三组redolog,每个日志组的大小都是50M,所以Standby redo log组 数>=(3+1)*1== 4所以至少需要创建4组Standby redo log,大小 均为50M (thread:线 程,只有在多实例数据库才有用的参数,例如RAC环境,单 实例不考虑)
查看当前有哪些日志组及其成员:
SYS@pri>col member for a50
SYS@pri>select group#,member from v$logfile;
| GROUP# MEMBER
---------- --------------------------------------------------
3 /u01/app/oracle/oradata/pri/redo03.log
2 /u01/app/oracle/oradata/pri/redo02.log
1 /u01/app/oracle/oradata/pri/redo01.log
|
先手动创建standby log日志组所需的目录:创建新目录只是为了便于区分,并非必须
[oracle@prioradata]$ cd /u01/app/oracle/oradata/
[oracle@prioradata]$ ls
| standbylog pri
|
新建4个日志组作为standby redolog日志组,大小与原来的日志组一致:由于已经存在 group1-3,,所以group号只能从4开始
SYS@pri>alter database add standby logfile group 4'/u01/app/oracle/oradata/standbylog/std_redo04.log' size 50m;
SYS@pri>alter database add standby logfile group 5 '/u01/app/oracle/oradata/standbylog/std_redo05.log'size 50m;
SYS@pri>alter database add standby logfile group 6'/u01/app/oracle/oradata/standbylog/std_redo06.log' size 50m;
SYS@pri>alter database add standby logfile group 7'/u01/app/oracle/oradata/standbylog/std_redo07.log' size 50m;
查看standby 日志组的信息:
SYS@pri>select group#,sequence#,status, bytes/1024/1024 from v$standby_log;
| GROUP# SEQUENCE# STATUS BYTES/1024/1024
---------- ------------------ ------------------- ------------------------
4 0 UNASSIGNED 50
5 0 UNASSIGNED 50
6 0 UNASSIGNED 50
7 0 UNASSIGNED 50
|
查看当前有哪些日志组及其成员:
SYS@pri>set pagesize 100
SYS@pri>col member for a60
SYS@pri>select group#,member from v$logfile order by group#;
| GROUP# MEMBER
------------ ------------------------------------------------------------
1 /u01/app/oracle/oradata/pri/redo01.log
2 /u01/app/oracle/oradata/pri/redo02.log
3 /u01/app/oracle/oradata/pri/redo03.log
4 /u01/app/oracle/oradata/standbylog/std_redo04.log
5 /u01/app/oracle/oradata/standbylog/std_redo05.log
6 /u01/app/oracle/oradata/standbylog/std_redo06.log
c /u01/app/oracle/oradata/standbylog/std_redo07.log
|
c.4、修改主库的pfile参数文件 (主库)
查看spfile的路径:
SYS@pri>show parameter spfile;
| NAME TYPE VALUE
----------- ----------- -----------------------------------------------------------------
spfile string /u01/app/oracle/product/11.2.0/db_1/dbs/spfilepri.ora
|
用spfile创建一个pfile,用于修改:
SYS@pri>create pfile from spfile;
修改主库的pfile:/u01/app/oracle/product/11.2.0/db_1/dbs/ initpri.ora
[oracle@pri~]$ cd $ORACLE_HOME/dbs
[oracle@pri~]$ vim initpri.ora
| pri.__db_cache_size=318767104
pri.__java_pool_size=4194304
pri.__large_pool_size=4194304
pri.__oracle_base='/u01/app/oracle'#ORACLE_BASE set from environment
pri.__pga_aggregate_target=335544320
pri.__sga_target=503316480
pri.__shared_io_pool_size=0
pri.__shared_pool_size=163577856
pri.__streams_pool_size=0
*.audit_file_dest='/u01/app/oracle/admin/pri/adump'
*.audit_trail='db'
*.compatible=' 11.2.0.4.0 '
*.control_files='/u01/app/oracle/oradata/pri/control01.ctl','/u01/app/oracle/flash_recovery_area/pri/control02.ctl'
*.db_block_size=8192
*.db_domain=''
*.db_name='pri'
*.db_recovery_file_dest='/u01/app/oracle/flash_recovery_area'
*.db_recovery_file_dest_size=4070572032
*.diagnostic_dest='/u01/app/oracle'
*.dispatchers='(PROTOCOL=TCP) (SERVICE=priXDB)'
*.log_archive_format='%t_%s_%r.dbf'
*.memory_target=836763648
*.open_cursors=300
*.processes=150
*.remote_login_passwordfile='EXCLUSIVE'
*.undo_tablespace='UNDOTBS1'
|
以下内容是需要新增加的:
| *.db_unique_name='pri' DG主库和备库的db_name必须一致,db_unique_name不一致
*.log_archive_config='dg_config=(pri,std)' pri主数据库SID,std备份数据库SID
*.log_archive_dest_1='location=/u01/app/oracle/arch valid_for=(all_logfiles,all_roles) db_unique_name=pri' 主数据库的归档日志路径和SID
*.log_archive_dest_2='service=std valid_for=(online_logfiles,primary_role) db_unique_name=std' 备份数据库的SID
*.log_archive_dest_state_1=enable
*.log_archive_dest_state_2=enable
*.log_archive_max_processes=4
*.fal_server='std' 备份数据库的SID
*.fal_client='pri' 主数据库的SID
*.db_file_name_convert='/u01/app/oracle/oradata/std','/u01/app/oracle/oradata/pri' 第一个目录是备份数据库数据文件路径(备份服务器上有此目录),第二个是主数据库数据文件路径
*.log_file_name_convert='/u01/app/oracle/oradata/std','/u01/app/oracle/oradata/pri' 第一个目录是备份数据库数据文件路径(备份服务器上有此目录),第二个是主数据库数据文件路径
*.standby_file_management='auto'
|
修改完毕,保存退出
手工创建/u01/app/oracle/arch:
[oracle@pridbs]$ mkdir –p /u01/app/oracle/arch
c.5、用修改过的pfile重新创建一个spfile用于重启数据库(主库)
关闭数据库:
SYS@pri>shutdown immediate;
| Database closed.
Database dismounted.
ORACLE instance shut down.
|
用修改过的pfile重新创建一个spfile:
SYS@pri>create spfile from pfile;
此时把数据库改为归档模式:如果当初建库时选择了启用归档,则此步骤忽略
由于当前数据库已关闭,首先需要把数据库启动到mount状态
SYS@pri> startup mount;
| ORACLE instance started.
Database mounted.
|
SYS@pri> alter database archivelog; 启用归档模式
| Database altered.
|
SYS@pri>alter database open; OPEN数据库
| Database altered.
|
SYS@pri>archive loglist; 查看是否启用归档模式
SQL>archive log list;
| Database log mode Archive Mode
Automatic archival Enabled
Archive destination /u01/app/oracle/arch
Oldest online log sequence 22
Next log sequence to archive 24
Current log sequence 24
|
如上,归档路径已经改为/u01/app/oracle/arch,证明对pfile的修改已生效
查看当前数据库是否使用spfile启动:
SYS@pri>show parameter spfile;
| NAME TYPE VALUE
----------- ----------- -----------------------------------------------------------------
spfile string /u01/app/oracle/product/11.2.0/db_1/dbs/spfilepri.ora
|
如上,若能看到spfile的路径,则证明数据库是使用spfile启动的,若没有值,则说明是用 pfile启动的。
确认数据库已经启用归档模式和强制日志模式:
SYS@pri>select name,log_mode,force_logging from v$database;
| NAME LOG_MODE FOR
--------- ------------------- -------
PRI ARCHIVELOG YES
|
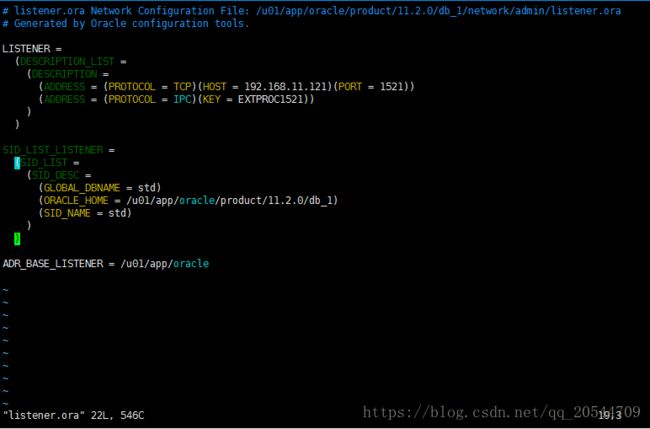
c.6、修改监听文件,添加静态监听 (主库、备库都要做)
主库:
[oracle@pri~]$ cd $ORACLE_HOME/network/admin
[oracle@priadmin]$ vim listener.ora
| # listener.ora Network Configuration File: /u01/app/oracle/product/11.2.0/db_1/network/admin/listener.ora
# Generated by Oracle configuration tools.
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.11.120)(PORT = 1521))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521))
)
)
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = pri)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0/db_1)
(SID_NAME = pri)
)
)
ADR_BASE_LISTENER = /u01/app/oracle
|
主库修改后最终效果如下图:
|
|

备库:
[oracle@pri~]$ cd $ORACLE_HOME/network/admin
[oracle@priadmin]$ vim listener.ora
| # listener.ora Network Configuration File: /u01/app/oracle/product/11.2.0/db_1/network/admin/listener.ora
# Generated by Oracle configuration tools.
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.11.121)(PORT = 1521))
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521))
)
)
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = std)
(ORACLE_HOME = /u01/app/oracle/product/11.2.0/db_1)
(SID_NAME = std)
)
)
ADR_BASE_LISTENER = /u01/app/oracle
|
备库修改后最终效果如下图:
|
|
使新增加的监听生效: (主库和备库端都要做)
[oracle@priadmin]$ lsnrctl stop
[oracle@priadmin]$ lsnrctl start
确认新增加的静态监听有效:
主库:
[oracle@pri~]$ lsnrctl status
| ..........................................(N行省略)
Services Summary...
Service "pri" has 2 instance(s).
Instance "pri", status UNKNOWN, has 1 handler(s) for this service...
Instance "pri", status READY, has 1 handler(s) for this service...
Service "priXDB" has 1 instance(s).
Instance "pri", status READY, has 1 handler(s) for this service...
The command completed successfully
|
备库:
[oracle@std~]$ lsnrctl status
| ..........................................(N行省略)
Services Summary...
Service "std" has 2 instance(s).
Instance "std", status UNKNOWN, has 1 handler(s) for this service...
The command completed successfully
|
如上,静态监听添加成功
c.7、编辑网络服务名配置文件tnsnames.ora (主库和备库端都要做)
[oracle@priadmin]$ cd /u01/app/oracle/product/11.2.0/db_1/network/admin
[oracle@priadmin]$ ls
| listener.ora samples tnsnames.ora
listener.ora_bak shrept.lst tnsnames.ora_bak
|
vimtnsnames.ora
| # tnsnames.ora Network Configuration File: /u01/app/oracle/product/11.2.0/db_1/network/admin/tnsnames.ora
# Generated by Oracle configuration tools.
pri =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.11.120)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = pri)
)
)
std =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.11.121)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = std)
)
)
|
编辑结果如下图:
|
|
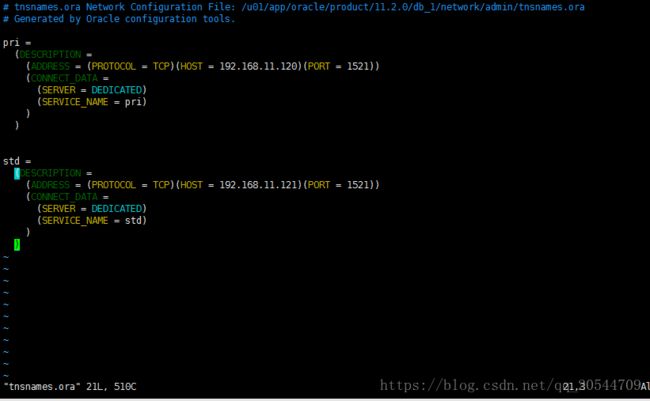
保证主库和备库的tnsnames.ora文件中的内容完全相同,可以把修改后的文件直接传给备库。
[oracle@priadmin]$ scp tnsnames.ora 192.168.11.121:$ORACLE_HOME/network/admin
| tnsnames.ora 100% 925 0.9KB/s 00:00
|
c.8、在备库端,修改pfile参数文件 (备库)
首先,在主库端把pfile拷贝给备库端的$ORACLE_HOME/dbs目录下,并重命名:
[oracle@std ~]$ cd $ORACLE_HOME/dbs
[oracle@ std dbs]$ ls
| hc_std.dat init.ora initstd.ora lkSTD orapwstd spfilestd.ora
|
从主库拷贝,主库执行命令
[oracle@pridbs]$ scp initpri.ora 192.168.2.253:$ORACLE_HOME/dbs/initstd.ora
然后在备库端进行修改:
[oracle@std~]$ cd $ORACLE_HOME/dbs
[oracle@stddbs]$ vim initstd.ora
| pri.__db_cache_size=318767104
pri.__java_pool_size=4194304
pri.__large_pool_size=4194304
pri.__oracle_base='/u01/app/oracle'#ORACLE_BASE set from environment
pri.__pga_aggregate_target=335544320
pri.__sga_target=503316480
pri.__shared_io_pool_size=0
pri.__shared_pool_size=163577856
pri.__streams_pool_size=0
*.audit_file_dest='/u01/app/oracle/admin/std/adump'
*.audit_trail='db'
*.compatible='11.2.0.0.0'
*.control_files='/u01/app/oracle/oradata/std/control01.ctl','/u01/app/oracle/oradata/std/control02.ctl'
*.db_block_size=8192
*.db_domain=''
*.db_name='pri' DG主库和备库的db_name必须一致,db_unique_name不一致
*.db_recovery_file_dest='/u01/app/oracle/flash_recovery_area'
*.db_recovery_file_dest_size=4070572032
*.diagnostic_dest='/u01/app/oracle'
*.dispatchers='(PROTOCOL=TCP) (SERVICE=stdXDB)'
*.log_archive_format='%t_%s_%r.dbf'
*.memory_target=836763648
*.open_cursors=300
*.processes=150
*.remote_login_passwordfile='EXCLUSIVE'
*.undo_tablespace='UNDOTBS1'
|
以下需要手工添加:
| *.db_unique_name='std'
*.log_archive_config='dg_config=(pri,std)'
*.log_archive_dest_1='location=/u01/app/oracle/arch valid_for=(all_logfiles,all_
roles) db_unique_name=std'
*.log_archive_dest_2='service=pri valid_for=(online_logfiles,primary_role) db
_unique_name=pri'
*.log_archive_dest_state_1=enable
*.log_archive_dest_state_2=enable
*.log_archive_max_processes=4
*.fal_server='pri'
*.fal_client='std'
*.db_file_name_convert='/u01/app/oracle/oradata/pri','/u01/app/oracle/oradata
/std'
*.log_file_name_convert='/u01/app/oracle/oradata/pri','/u01/app/oracle/oradat
a/std'
*.standby_file_management='auto'
|
修改完毕,保存退出
注意:整个搭建过程最需要留意的就是主库和备库的PFILE配置,建议修改完后仔细对照主备库PFILE的区别
c.9、在备库端手工创建所需的目录 (备库,不提前创建的话恢复时会报错!)
mkdir -pv /u01/app/oracle/admin/std/adump
mkdir -pv /u01/app/oracle/diag/rdbms/std/std/trace
mkdir -pv /u01/app/oracle/arch
mkdir -pv /u01/app/oracle/oradata/std
mkdir -pv /u01/app/oracle/oradata/standbylog
mkdir -pv /u01/app/oracle/flash_recovery_area
c.10、用修改后的pfile创建一个spfile,用于启动数据库 (备库)
[oracle@std~]$ sqlplus / as sysdba
SYS@std>create spfile from pfile;
将数据库启动到nomount状态:
SYS@std>startup nomount;
| ORACLE instance started.
Total System Global Area 839282688 bytes
Fixed Size 2233000 bytes
Variable Size 482348376 bytes
Database Buffers 352321536 bytes
Redo Buffers 2379776 bytes
|
c.11、利用RMAN在备库上恢复主库 (备库)
[oracle@std~]$ rman target sys/oracle@pri auxiliary sys/oracle@std
| Recovery Manager: Release 11.2.0.3.0 - Production on Tue Apr 15 16:39:28 2014
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
connected to target database: PRI (DBID=775616459)
connected to auxiliary database: PRI (not mounted)
|
RMAN>duplicate target database for standby from active database nofilenamecheck;
这条命令可以直接恢复数据文件,standby控制文件,standby日志组,非常霸道
| Starting Duplicate Db at 16-MAR-16
using target database control file instead of recovery catalog
allocated channel: ORA_AUX_DISK_1
channel ORA_AUX_DISK_1: SID=134 device type=DISK
contents of Memory Script:
{
backup as copy reuse
targetfile '/u01/app/oracle/product/11.2.0/db_1/dbs/orapwpri' auxiliary format
'/u01/app/oracle/product/11.2.0/db_1/dbs/orapwstd' ;
}
executing Memory Script
Starting backup at 16-MAR-16
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=140 device type=DISK
Finished backup at 16-MAR-16
contents of Memory Script:
{
backup as copy current controlfile for standby auxiliary format '/u01/app/oracle/oradata/std/control01.ctl';
}
executing Memory Script
Starting backup at 16-MAR-16
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile copy
copying standby control file
output file name=/u01/app/oracle/product/11.2.0/db_1/dbs/snapcf_pri.f tag=TAG20160316T110737 RECID=2 STAMP=906635257
channel ORA_DISK_1: datafile copy complete, elapsed time: 00:00:01
Finished backup at 16-MAR-16
contents of Memory Script:
{
sql clone 'alter database mount standby database';
}
executing Memory Script
sql statement: alter database mount standby database
contents of Memory Script:
{
set newname for tempfile 1 to
"/u01/app/oracle/oradata/std/temp01.dbf";
switch clone tempfile all;
set newname for datafile 1 to
"/u01/app/oracle/oradata/std/system01.dbf";
set newname for datafile 2 to
"/u01/app/oracle/oradata/std/sysaux01.dbf";
set newname for datafile 3 to
"/u01/app/oracle/oradata/std/undotbs01.dbf";
set newname for datafile 4 to
"/u01/app/oracle/oradata/std/users01.dbf";
backup as copy reuse
datafile 1 auxiliary format
"/u01/app/oracle/oradata/std/system01.dbf" datafile
2 auxiliary format
"/u01/app/oracle/oradata/std/sysaux01.dbf" datafile
3 auxiliary format
"/u01/app/oracle/oradata/std/undotbs01.dbf" datafile
4 auxiliary format
"/u01/app/oracle/oradata/std/users01.dbf" ;
sql 'alter system archive log current';
}
executing Memory Script
executing command: SET NEWNAME
renamed tempfile 1 to /u01/app/oracle/oradata/std/temp01.dbf in control file
executing command: SET NEWNAME
executing command: SET NEWNAME
executing command: SET NEWNAME
executing command: SET NEWNAME
Starting backup at 16-MAR-16
using channel ORA_DISK_1
channel ORA_DISK_1: starting datafile copy
input datafile file number=00001 name=/u01/app/oracle/oradata/pri/system01.dbf
output file name=/u01/app/oracle/oradata/std/system01.dbf tag=TAG20160316T110744
channel ORA_DISK_1: datafile copy complete, elapsed time: 00:01:38
channel ORA_DISK_1: starting datafile copy
input datafile file number=00002 name=/u01/app/oracle/oradata/pri/sysaux01.dbf
output file name=/u01/app/oracle/oradata/std/sysaux01.dbf tag=TAG20160316T110744
channel ORA_DISK_1: datafile copy complete, elapsed time: 00:01:09
channel ORA_DISK_1: starting datafile copy
input datafile file number=00003 name=/u01/app/oracle/oradata/pri/undotbs01.dbf
output file name=/u01/app/oracle/oradata/std/undotbs01.dbf tag=TAG20160316T110744
channel ORA_DISK_1: datafile copy complete, elapsed time: 00:00:15
channel ORA_DISK_1: starting datafile copy
input datafile file number=00004 name=/u01/app/oracle/oradata/pri/users01.dbf
output file name=/u01/app/oracle/oradata/std/users01.dbf tag=TAG20160316T110744
channel ORA_DISK_1: datafile copy complete, elapsed time: 00:00:01
Finished backup at 16-MAR-16
sql statement: alter system archive log current
contents of Memory Script:
{
switch clone datafile all;
}
executing Memory Script
datafile 1 switched to datafile copy
input datafile copy RECID=2 STAMP=906635463 file name=/u01/app/oracle/oradata/std/system01.dbf
datafile 2 switched to datafile copy
input datafile copy RECID=3 STAMP=906635463 file name=/u01/app/oracle/oradata/std/sysaux01.dbf
datafile 3 switched to datafile copy
input datafile copy RECID=4 STAMP=906635463 file name=/u01/app/oracle/oradata/std/undotbs01.dbf
datafile 4 switched to datafile copy
input datafile copy RECID=5 STAMP=906635463 file name=/u01/app/oracle/oradata/std/users01.dbf
Finished Duplicate Db at 16-MAR-16
|
恢复数据库结束
c.12、尝试开启备库
登陆并查看数据库当前状态:
[oracle@std ~]$ sqlplus / as sysdba
SYS@std>startup
SYS@std>select status from v$instance;
| STATUS
------------
MOUNTED (RMAN恢复完直接就是mount状态)
|
c.13、备库启动日志应用(启用备库前确认归档日志是否都已拷贝)
SYS@std>alter database recover managed standby database disconnect from session;
| Database altered.
(停止日志应用的命令是:alter database recover managed standby database cancel;)
|
查看日志应用情况:
SYS@std>set pagesize 100
SYS@std>select sequence#,applied from v$archived_log order by 1;
| SEQUENCE# APPLIED
---------- ---------
8 YES
9 YES
10 YES
|
如上,如果发现有个NO的,也是正常的,说明该日志在主库上还没有归档,可以在主库上运行alter system switch logfile;命令来进行日志切换,再到备库查看日志应用情况
c.14、分别查看主库和备库的归档序列号是否一致:
先在主库手动切换一下日志:
SYS@pri> alter system switch logfile;
然后查看主库:
SYS@pri>archive log list;
SQL>archive log list;
| Database log mode Archive Mode
Automatic archival Enabled
Archive destination /u01/app/oracle/arch
Oldest online log sequence 22
Next log sequence to archive 24
Current log sequence 24
|
备库:
SQL>archive log list;
| Database log mode Archive Mode
Automatic archival Enabled
Archive destination /u01/app/oracle/arch
Oldest online log sequence 22
Next log sequence to archive 0
Current log sequence 24
|
结果完全一致,至此,DataGuard的搭建成功!
d、完成后检测
d.1、查看standby启动的DG进程
SQL> selectprocess,client_process,sequence#,status from v$managed_standby;
| PROCESS CLIENT_P SEQUENCE# STATUS
--------- -------- ---------- ------------
ARCH ARCH 23 CLOSING
ARCH ARCH 0 CONNECTED //归档进程
ARCH ARCH 21 CLOSING
ARCH ARCH 0 CONNECTED
RFS ARCH 0 IDLE
RFS UNKNOWN 0 IDLE
RFS LGWR 24 IDLE //归档传输进程
RFS UNKNOWN 0 IDLE
MRP0 N/A 24 APPLYING_LOG //日志应用进程
d rows selected.
|
d.2、查看数据库的保护模式:
SQL> selectdatabase_role,protection_mode,protection_level,open_mode from v$database;
| DATABASE_ROLE PROTECTION_MODE PROTECTION_LEVEL OPEN_MODE
---------------- -------------------- -------------------- --------------------
PRIMARY MAXIMUM PERFORMANCE MAXIMUM PERFORMANCE READ WRITE
|
#standby 端查看,也是一样的。
SQL> selectdatabase_role,protection_mode,protection_level,open_mode from v$database;
| DATABASE_ROLE PROTECTION_MODE PROTECTION_LEVEL OPEN_MODE
---------------- -------------------- -------------------- --------------------
PHYSICAL STANDBY MAXIMUM PERFORMANCE MAXIMUM PERFORMANCE MOUNTED
|
查看DG的日志信息
SQL> select *from v$dataguard_status;
d.3、Open Read Onlystandby数据库并且开启实时日志应用
SQL>shutdown immediate
| ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
|
SQL>startup
| ORACLE instance started.
Total System Global Area 1188511744 bytes
Fixed Size 1364228 bytes
Variable Size 754978556 bytes
Database Buffers 419430400 bytes
Redo Buffers 12738560 bytes
Database mounted.
Database opened.
|
SQL>select database_role,protection_mode,protection_level,open_mode from v$database;
| DATABASE_ROLE PROTECTION_MODE PROTECTION_LEVEL OPEN_MODE
---------------- -------------------- -------------------- --------------------
PHYSICAL STANDBY MAXIMUM PERFORMANCE MAXIMUM PERFORMANCE READ ONLY
|
SQL>select process,client_process,sequence#,status from v$managed_standby;
| PROCESS CLIENT_P SEQUENCE# STATUS
--------- -------- ---------- ------------
ARCH ARCH 0 CONNECTED
ARCH ARCH 0 CONNECTED
ARCH ARCH 0 CONNECTED
ARCH ARCH 26 CLOSING
RFS ARCH 0 IDLE
RFS UNKNOWN 0 IDLE
RFS LGWR 27 IDLE
7 rows selected.
|
SQL>recover managed standby database using current logfile disconnect from session;
| Media recovery complete.
|
SQL>select process,client_process,sequence#,status from v$managed_standby;
| PROCESS CLIENT_P SEQUENCE# STATUS
--------- -------- ---------- ------------
ARCH ARCH 0 CONNECTED
ARCH ARCH 0 CONNECTED
ARCH ARCH 0 CONNECTED
ARCH ARCH 26 CLOSING
RFS ARCH 0 IDLE
RFS UNKNOWN 0 IDLE
RFS LGWR 27 IDLE
MRP0 N/A 27 APPLYING_LOG
8 rows selected.
|
SQL>select process,client_process,sequence#,status from v$managed_standby;
| PROCESS CLIENT_P SEQUENCE# STATUS
--------- -------- ---------- ------------
ARCH ARCH 19 CLOSING
ARCH ARCH 20 CLOSING
ARCH ARCH 0 CONNECTED
ARCH ARCH 21 CLOSING
MRP0 N/A 22 WAIT_FOR_LOG
RFS ARCH 0 IDLE
RFS UNKNOWN 0 IDLE
RFS UNKNOWN 0 IDLE
RFS LGWR 22 IDLE
9 rows selected.
|
注解:
② S锁和X锁:基本的封锁类型有两种:排它锁(X锁)和共享锁(S锁)。所谓X锁,是事务T对数据A加上X锁时,只允许事务T读取和修改数据A,...所谓S锁,是事务T对数据A加上S锁时,其他事务只能再对数据A加S锁,而不能加X锁,直到T释放A上的S锁,若事务T对数据对象A加了S锁,则T就可以对A进行读取,但不能进行更新(S锁因此又称为读锁),在T释放A上的S锁以前,其他事务可以再对A加S锁,但不能加X锁,从而可以读取A,但不能更新A。
③ balance="0",不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1 ->S1 , M2->S2,并且 M1 与M2 互为主备),正常情况下, M2,S1,S2 都参与 select 语句的负载均衡。balance="2",所有读操作都随机的在 writeHost、readhost 上分发。balance="3", 所有读请求随机的分发到wiriterHost 对应的 readhost 执行,writerHost不负担读压力,注意 balance=3 只在 1.4 及其以后版本有, 1.3 没有。writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .writeType="1",所有写操作都随机的发送到配置的 writeHost。writeType="2",没实现。不写入switchType 属性,主mysql挂了,从mysql是否提升为主,-1 表示不自动切换,1 默认值,自动切换,2 基于MySQL主从同步的状态决定是否切换
https://blog.csdn.net/qq_20544709/article/details/80883571