python-反爬虫案例(西刺代理网站的爬取)
Linux系统
python scrapy框架
本文来爬取网页:网络免费的代理ip
www.xicidaili.com 一个常用的免费ip代理网站
由于刚开始测试时候,忘记加ip代理,导致网站封了我的ip,代理ip网页就没图片
(一)创建一个scrapy项目,目标 爬取西刺代理网站
scrapy startproject ipstack
cd ipstack
scrapy genspider ips www.xicidaili.com
(二)编写items,我们需要的有ip 端口号 协议类型
import scrapy
class IpstackItem(scrapy.Item):
ip = scrapy.Field()
port = scrapy.Field()
htype =scrapy.Field()
(三)开始写我们的爬虫ips
import time
import scrapy
from ipstack.items import IpstackItem
class IpsSpider(scrapy.Spider):
name = 'ips'
allowed_domains = ['www.xicidaili.com']
start_urls = ['https://www.xicidaili.com']
def parse(self, response):
# . 获取ip的信息:
ip_list = response.xpath("//table[@id='ip_list']/tr")
for ips in ip_list[1:]:
time.sleep(0.2)
#实例化对象, IpstackItem
# 用来检测代码是否达到指定位置, 并用来调试并解析页面信息;
item = IpstackItem()
item['ip'] = ips.xpath("./td[2]/text()").extract()
item['port'] = ips.xpath("./td[3]/text()").extract()
item['htype'] = ips.xpath("./td[6]/text()").extract() # print(item['ip'])
yield item
# 获取下一页是否有链接;href
url = response.xpath(".//a[@class='next_page']/@href")[0].extract()
if url:
# 构建新的url
page = "https://www.xicidaili.com" + url
yield scrapy.Request(page, callback=self.parse)
(四)在中间件里面写一些反爬虫规则,代理ip(用西刺代理里面的代理ip爬取西次代理网站总感觉不厚道),代理的use_agent注(估计等你用的话 ip已经过期 ,得自己找两三个就行)
class UserAgentMiddleware(object):
def __init__(self):
self.user_agent = [
'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0',
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
]
def process_request(self, request, spider):
ua = random.choice(self.user_agent)
if ua:
# 此行仅为了测试, 真实场景不要打印, 会影响爬虫的效率
# print("当前使用的用户代理: %s" %(ua))
request.headers.setdefault('User-Agent', ua)
class ProxiesMiddleware(object):
def __init__(self):
self.proxies = [
"https://111.177.183.212:9999",
'http://116.209.54.221:9999'
]
def process_request(self, request, spider):
"""当发起请求"""
proxy = random.choice(self.proxies)
if proxy:
# 此行仅为了测试, 真实场景不要打印, 会影响爬虫的效率
# print("当前使用的代理IP: %s" %(proxy))
request.meta['proxy'] = proxy
(五)编写管道文件,可以存储到数据库中,我存储的是csv文件中
class csvipPipeline(object):
"""将爬取的信息保存为csv格式"""
def __init__(self):
self.f = open('ipstack.csv', 'w')
def process_item(self, item, spider):
# xxxx:xxxxx:xxxx
item = dict(item)
if item['htype'][0]== 'HTTP' or item['htype'][0]=="HTTPS":
self.f.write("{0}:{1}:{2}\n".format(item['htype'][0],item['ip'][0], item['port'][0]))
# 返回给调度为器;
return item
def open_spider(self, spider):
"""开启爬虫时执行的函数"""
pass
def close_spider(self, spider):
"""当爬虫全部爬取结束的时候执行的函数"""
self.f.close()
(六)在setting中记得打开爬虫和你写的反爬规则
ITEM_PIPELINES = {
'ipstack.pipelines.csvipPipeline': 100,
}
DOWNLOADER_MIDDLEWARES = {
'ipstack.middlewares.IpstackDownloaderMiddleware': 543,
'ipstack.middlewares.ProxiesMiddleware': 200,
'ipstack.middlewares.UserAgentMiddleware': 300,
}
(七)执行你的爬虫
scrapy crawl ips
最后检验成果
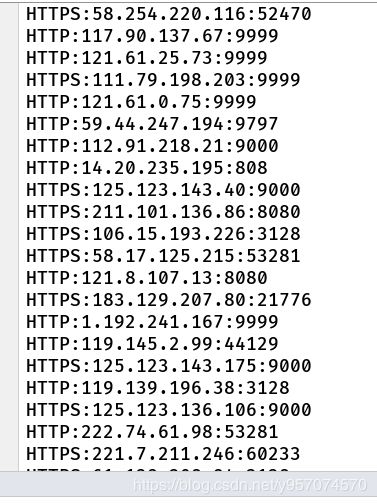
本人毕业设设做的是基于scrapy的招聘信息的爬取与数据分析决策系统,爬取ip代理网站也是为自己毕设做准备