在看具体源码前,我们先回顾一下之前我们所实现的内容,从而找一个合适的切入口去分析。首先,服务注册中心、服务提供者、服务消费者这三个主要元素来说,后两者(也就是Eureka客户端)在整个运行机制中是大部分通信行为的主动发起者,而注册中心主要是处理请求的接收者。所以,我们可以从Eureka的客户端作为入口看看它是如何完成这些主动通信行为的。
我们在将一个普通的Spring Boot应用注册到Eureka Server中,或是从Eureka Server中获取服务列表时,主要就做了两件事:
在应用主类中配置了@EnableDiscoveryClient注解
在application.properties中用eureka.client.serviceUrl.defaultZone参数指定了服务注册中心的位置
顺着上面的线索,我们先查看@EnableDiscoveryClient的源码如下:
/**
* Annotation to enable a DiscoveryClient implementation.
*@authorSpencer Gibb
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import(EnableDiscoveryClientImportSelector.class)
public@interfaceEnableDiscoveryClient {
}
从该注解的注释我们可以知道:该注解用来开启DiscoveryClient的实例。通过搜索DiscoveryClient,我们可以发现有一个类和一个接口。通过梳理可以得到如下图的关系:
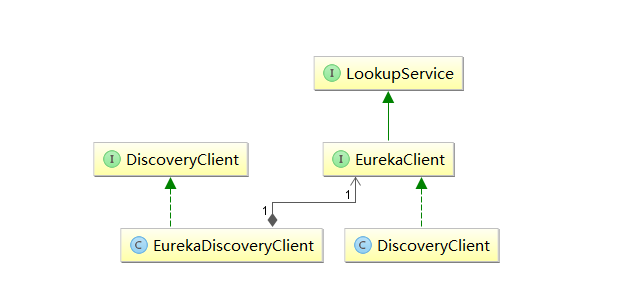
其中,左边的org.springframework.cloud.client.discovery.DiscoveryClient是Spring Cloud的接口,它定义了用来发现服务的常用抽象方法,而org.springframework.cloud.netflix.eureka.EurekaDiscoveryClient是对该接口的实现,从命名来就可以判断,它实现的是对Eureka发现服务的封装。所以EurekaDiscoveryClient依赖了Eureka的com.netflix.discovery.EurekaClient接口,EurekaClient继承了LookupService接口,他们都是Netflix开源包中的内容,它主要定义了针对Eureka的发现服务的抽象方法,而真正实现发现服务的则是Netflix包中的com.netflix.discovery.DiscoveryClient类。
那么,我们就看看来详细看看DiscoveryClient类。先解读一下该类头部的注释有个总体的了解,注释的大致内容如下:
这个类用于帮助与Eureka Server互相协作。
Eureka Client负责了下面的任务:
- 向Eureka Server注册服务实例
- 向Eureka Server为租约续期
- 当服务关闭期间,向Eureka Server取消租约
- 查询Eureka Server中的服务实例列表
Eureka Client还需要配置一个Eureka Server的URL列表。
在具体研究Eureka Client具体负责的任务之前,我们先看看对Eureka Server的URL列表配置在哪里。根据我们配置的属性名:eureka.client.serviceUrl.defaultZone,通过serviceUrl我们找到该属性相关的加载属性,但是在SR5版本中它们都被@Deprecated标注了,并在注视中可以看到@link到了替代类com.netflix.discovery.endpoint.EndpointUtils,我们可以在该类中找到下面这个函数:
publicstaticMap> getServiceUrlsMapFromConfig(
EurekaClientConfig clientConfig, String instanceZone,booleanpreferSameZone) {
Map> orderedUrls =newLinkedHashMap<>();
String region = getRegion(clientConfig);
String[] availZones = clientConfig.getAvailabilityZones(clientConfig.getRegion());
if(availZones ==null|| availZones.length ==0) {
availZones =newString[1];
availZones[0] = DEFAULT_ZONE;
}
……
intmyZoneOffset = getZoneOffset(instanceZone, preferSameZone, availZones);
String zone = availZones[myZoneOffset];
List serviceUrls = clientConfig.getEurekaServerServiceUrls(zone);
if(serviceUrls !=null) {
orderedUrls.put(zone, serviceUrls);
}
……
returnorderedUrls;
}
Region、Zone
在上面的函数中,我们可以发现客户端依次加载了两个内容,第一个是Region,第二个是Zone,从其加载逻上我们可以判断他们之间的关系:
通过getRegion函数,我们可以看到它从配置中读取了一个Region返回,所以一个微服务应用只可以属于一个Region,如果不特别配置,就默认为default。若我们要自己设置,可以通过eureka.client.region属性来定义。
publicstaticStringgetRegion(EurekaClientConfig clientConfig){
String region = clientConfig.getRegion();
if(region ==null) {
region = DEFAULT_REGION;
}
region = region.trim().toLowerCase();
returnregion;
}
通过getAvailabilityZones函数,我们可以知道当我们没有特别为Region配置Zone的时候,将默认采用defaultZone,这也是我们之前配置参数eureka.client.serviceUrl.defaultZone的由来。若要为应用指定Zone,我们可以通过eureka.client.availability-zones属性来进行设置。从该函数的return内容,我们可以Zone是可以有多个的,并且通过逗号分隔来配置。由此,我们可以判断Region与Zone是一对多的关系。
publicString[] getAvailabilityZones(String region) {
String value =this.availabilityZones.get(region);
if(value ==null) {
value = DEFAULT_ZONE;
}
returnvalue.split(",");
}
ServiceUrls
在获取了Region和Zone信息之后,才开始真正加载Eureka Server的具体地址。它根据传入的参数按一定算法确定加载位于哪一个Zone配置的serviceUrls。
intmyZoneOffset = getZoneOffset(instanceZone, preferSameZone, availZones);
String zone = availZones[myZoneOffset];
List serviceUrls = clientConfig.getEurekaServerServiceUrls(zone);
具体获取serviceUrls的实现,我们可以详细查看getEurekaServerServiceUrls函数的具体实现类EurekaClientConfigBean,该类是EurekaClientConfig和EurekaConstants接口的实现,用来加载配置文件中的内容,这里有非常多有用的信息,这里我们先说一下此处我们关心的,关于defaultZone的信息。通过搜索defaultZone,我们可以很容易的找到下面这个函数,它具体实现了,如何解析该参数的过程,通过此内容,我们就可以知道,eureka.client.serviceUrl.defaultZone属性可以配置多个,并且需要通过逗号分隔。
publicListgetEurekaServerServiceUrls(String myZone){
String serviceUrls =this.serviceUrl.get(myZone);
if(serviceUrls ==null|| serviceUrls.isEmpty()) {
serviceUrls =this.serviceUrl.get(DEFAULT_ZONE);
}
if(!StringUtils.isEmpty(serviceUrls)) {
finalString[] serviceUrlsSplit = StringUtils.commaDelimitedListToStringArray(serviceUrls);
List eurekaServiceUrls =newArrayList<>(serviceUrlsSplit.length);
for(String eurekaServiceUrl : serviceUrlsSplit) {
if(!endsWithSlash(eurekaServiceUrl)) {
eurekaServiceUrl +="/";
}
eurekaServiceUrls.add(eurekaServiceUrl);
}
returneurekaServiceUrls;
}
returnnewArrayList<>();
}
当客户端在服务列表中选择实例进行访问时,对于Zone和Region遵循这样的规则:优先访问同自己一个Zone中的实例,其次才访问其他Zone中的实例。通过Region和Zone的两层级别定义,配合实际部署的物理结构,我们就可以有效的设计出区域性故障的容错集群。
从现在开始,我这边会将近期研发的springcloud微服务云架构的搭建过程和精髓记录下来,帮助更多有兴趣研发spring cloud框架的朋友,希望可以帮助更多的好学者。大家来一起探讨spring cloud架构的搭建过程及如何运用于企业项目。源码来源