Hadoop HDFS读写数据过程原理分析
Hadoop HDFS读写数据过程原理分析
摘要: 在学习hadoop hdfs的过程中,有很多人在编程实践这块不知道该其实现的原理是什么,为什么通过几十行小小的代码就可以实现对hdfs的数据的读写。
下面介绍其实现的原理过程。
一.读数据的原理分析

1.打开文件
用Java导入FileSystem类,通过FileSystem.get(conf)声明一个实例对象fs,从而分布式系统底层的配置文件会被项目所调用,如core-site.xml、hdfs-site.xml;进而生成一个子类DistributedFileSystem,这时候实例对象fs与分布式系统也就紧紧相关了。
由于我们要读数据,当然就需要使用到输入流,这时候输入流的类型是FsDataInputStream,其中封装着DFSInputStream。
在这里为什么我们看不见或者无法调用DFSInputStream呢,因为这是Hadoop后台自动给其封装的好的,真正与Hadoop当中的名称节点进行交流的,其实是DFSInputStream,而不是FsDataInputStream。
FsDataInputStream在项目中是干嘛呢,其实是与客户端进行交流的。
2.获取数据库信息
由于FsDataInputStream内部封装了DFSInputStream,要获取项目所需要的数据被存放到哪些数据节点,因此DFSInputStream会通过conf中的配置文件信息远程与名称节点进行交流。
通过当中的ClientProtocal.getBlockLocations()方法来向名称节点查找项目所需的数据被存放到哪些数据节点,而名称节点会把文件的开始一部分数据位置信息返回去。
3.读取请求
客户端获得输入流FsDataInputStream返回的数据位置信息,就可以使用read函数读取数据。
这时候肯定不少就近客户端的存在,事实上,名称节点在返回时还包括将数据节点距离客户端的远近进行排序,而客户端会自动选择距离最近的一个数据节点进行连接,接着读取数据。
4.读取数据
当客户端读取完数据后,FsDataInputStream需要关闭和数据节点的连接。
5.获取数据块信息
对应刚才的第二步,我们可能只读取了文件数据的部分数据块位置信息,因此需要再次通过ClientProtocal.getBlockLocations()方法来向名称节点查找项目所需的下一个数据被存放到哪些数据节点。
同样的,名称节点会返回下一个数据的数据节点位置信息节点列表给客户端。
6.读取数据
客户端获取信息后,继续通过read函数与这些数据节点进行连接,不断循环,直到完成所有数据库的读取。
7.关闭文件
客户端调用FsDataInputStream输入流的关闭操作close,关闭整个文件读取数据的过程。
二.写数据原理分析
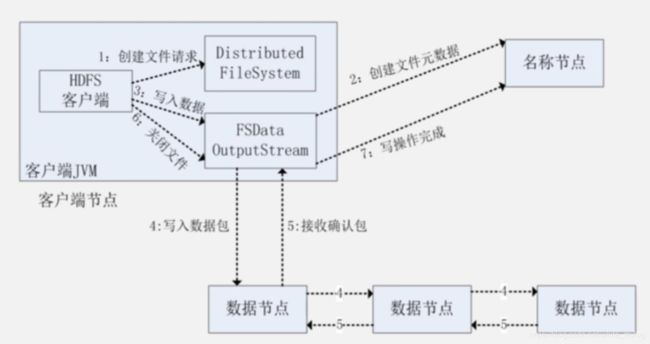
1.创建文件请求
与读数据一样,通过FileSystem.get(conf)声明一个实例对象fs,从而分布式系统底层的配置文件会被项目所调用,如core-site.xml、hdfs-site.xml;进而生成一个子类DistributedFileSystem,这时候实例对象fs与分布式系统也就紧紧相关了。
由于我们要写数据,当然就需要使用到输出流,这时候输出流的类型是FsDataOutputStream,其中封装着DFSOutputStream。
在这里为什么我们看不见或者无法调用DFSOutputStream呢,因为这是Hadoop后台自动给其封装的好的,真正与Hadoop当中的名称节点进行交流的,其实是DFSOutputStream,而不是FsDataOutputStream。
FsDataOutputStream在项目中是干嘛呢,其实是与客户端进行交流的。
2.创建文件元数据
DFSOutputStream执行RPC远程调用,让名称节点在文件系统的命名空间中新建一个文件。
名称节点不会直接创建文件,首先会进行检查,检查该文件是否已存在,接着会检查客户端是否有权限去创建该文件。如果检查通过,名称节点则会创建该文件,通过数组返回。
3.写入数据
由于写数据要写入数据节点,而数据副本也会被相应写入进去,有点类似于流水线。在HDFS中有一种非常高效的写数据方式,叫做流水线的复制方式。
将客户端要写的数据,分成一个个小的数据包,这些数据包会被放在DFSOutputStream对象的内部队列,之后DFSOutputStream向名称节点申请保存这些数据块的数据节点。
4.写入数据包
名称节点返回信息后,客户端可以知道写入到哪些数据节点,一个数据节点列表有很多个数据节点,这些数据节点会被排成一个队列, 并且把一个数据保存到多个数据节点上,形成数据流的管道。
而放在队列的数据包会被再次打包成数据包,将其发送到整个数据流管道当中的第一个数据节点,接着第一个数据节点发送给第二个数据节点以此类推。因为这些数据包要重复写到这些数据块上,一模一样的数据块也叫数据副本。这些数据节点就形成一个流水线。
5.接收确认包
当最后一个数据节点写好数据块后,就会返回一个确认包。最后一个数据节点发送给最后第二个数据节点以此类推,传回到第一个数据节点,再传回到客户端。
6.关闭文件
客户端接收到时则说明数据的整个写操作完成。完成后就可以关闭文件。