猫眼字体反爬
一.背景
字体反爬是什么鬼?我才听说的时候一脸懵逼.最后发现是字体编码方式.简单解释就是一种映射关系,网页的特定编码方式.说再多也不如来一图.
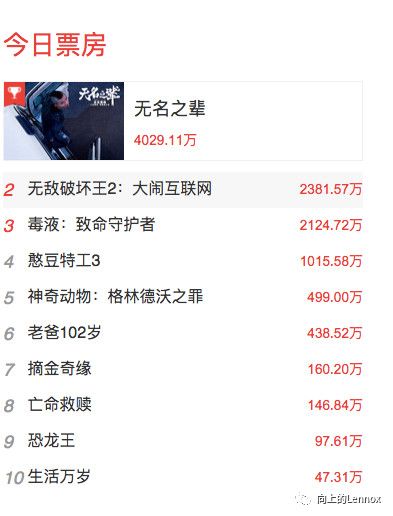
看图,无名之辈的票房是不是大家都能看懂,4029.11万.接下来showtime到了.

4029.11是不是很爽快的变成一堆堆框框了.老实交代有木有打开猫眼观察了.是不是惊悚的发现数字基本都变了.这是什么鬼,其实就是一种自定义字体.不对不对,也不一定是一种,因为亲爱的猫眼就是很多种自定义字体.所以你还会绝望的发现你每次打开网页看到的票房显示的是一样的,但是当你打开开发者工具却发现自定对应的映射每次都变了.待会再介绍详情.接下来我们在网页代码里面搜索font.对,就是很多个框框前面那个stonefont.为什么不搜stonefont呢,因为你会搜出40个结果来.然后你搜一下font就能得到字体映射对应的网址.

url()里面的就是字体映射所在的网页.其实这也解释了为什么只有数字才反爬.不对应该说少量的字体.因为汽车之家里面有一些中文也是这样的.理论上来说如果你对自己服务器的性能非常自信,你也可以把所有的字体都映射一遍.那基本就不用爬了.
我们把url括号里的网址提取出来.然后打开这网页.下载得到字体.然后用百度的工具http://fontstore.baidu.com/static/editor/index.html打开看看这个字体映射里面到底包括了多少字符.

里面一个有12个字符.第一个是空格,有用的是后面的.是不是看到每个数字下面都有一个uni开头的字符?这个就是对应的关键.(这里我不太完全理解.我感觉应该是unicode表的字符,而不是utf-8编码所以在开发者工具里并不能显示出来)那么我们再来详细看看这个字符里面的构成.
这一步需要一些辅助,先安装这个库.
pip install fonttools
然后利用python将字体文件转化成能观察的,如下
from fontTools.ttLib import TTFont
font=TTFont('base.otf')
font.saveXML('base.xml')
这样用sublime打开base.xml就可以看到完整的字体文档了,也就跟网页结构差不多.
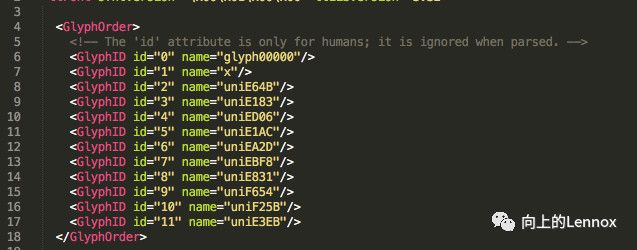
各位可爱的帅哥美女有没有发现这个跟刚刚百度工具打开的uni字符很像啊,准确的说不是像而是直接就下.但是我们不可能每次都打开看啊,他们到底怎么对应的,不急请看下图是不是发现有个name="uniE183".是个这个结构里面就是uniE183的字符形状.

这就解释了为什么是半自动了.我们首先下载一套字体,然后查看一套字体对应的数字关系,然后爬虫运行的时候把字体下载下来,通过每一个字符对应的图形对比,如果字体图形一样,那么就代表了是指同一个数字,这也是为什么我一直称它为映射的原因.
二.编程实现
接下来就撸起袖子开始干啦.
1.需要的库
import requests
from fake_useragent import UserAgent
from pyquery import PyQuery as pq
import re
from lxml import html
import woff2otf
from fontTools.ttLib import TTFont
这些库都可以通过pip安装.唯一需要注意的是woff2otf这个是github上大神写的,必须将附带的两个文档也下了.然后把这两个文档放在和你程序同目录下才能导入这个woff2otf库.
2.返回网页源码
def get_page():
url = 'http://maoyan.com/'
ua = UserAgent()
headers = {'User-Agent': ua.random}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
except requests.ConnectionError as e:
print(e.args)
这一步是有两用处,一是得到字体编码的网址.就是url后面括号里面的网址,用来下载字体文件,二是得到你要爬的信息.
3.下载字体
def down_ziti(html):
ua = UserAgent()
headers = {'User-Agent': ua.random}
cmp = re.compile(",\n.*?url\('(.*?.woff)'\)")
url = cmp.findall(html)
url = 'http:' + url[0]
response = requests.get(url, headers=headers, stream=True)
with open('maoyan.woff', 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
woff2otf.convert('maoyan.woff', 'maoyan.otf')
这里是下载字体文件,requests里的stream是用来分段下载,默认是False,改成True之后几乎是分段下载.
4.解析字体
def parse_ziti():
baseFont = TTFont('base.otf')
maoyanFont = TTFont('maoyan.otf')
baseNumberList = ['.', '3', '5', '1', '2', '7', '0', '6', '9', '8', '4']
baseUnicode = ['x', 'uniE64B', 'uniE183', 'uniED06', 'uniE1AC', 'uniEA2D', 'uniEBF8',
'uniE831', 'uniF654', 'uniF25B', 'uniE3EB']
maoyanNumberList = []
maoyanUnicode = maoyanFont.getGlyphOrder()
for i in range(1, 12):
maoyanGlyph = maoyanFont['glyf'][maoyanUnicode[i]]
for j in range(11):
baseGlyph = baseFont['glyf'][baseUnicode[j]]
if maoyanGlyph == baseGlyph:
maoyanNumberList.append(baseNumberList[j])
break
maoyanUnicode[1] = 'uni0078'
utf8List = [eval("u'\\u" + uni[3:] + "'").encode('utf-8') for uni in maoyanUnicode[1:]]
return (utf8List, maoyanUnicode, maoyanNumberList)
如上所说,解析字体对比字体符号图形得出对应的数字
5.解析要爬的数据
def parse_page(html):
doc = pq(html)
data = {}
if doc:
items = doc('.content .aside .ranking-box-wrapper .panel .ranking-wrapper li')
for k,item in enumerate(items.items()):
if k == 0:
data['name'] = item.find('.ranking-top-moive-name').text()
else:
data['name'] = item.find('.ranking-movie-name').text()
data['score'] = item.find('.stonefont').text()
yield data
得到今日票房信息.我这里使用今日票房信息做实例.
6.schedule
html = get_page()
down_ziti(html)
utf8List, maoyanUnicode, maoyanNumberList = parse_ziti()
maoyanUnicode = [item.encode('utf-8') for item in maoyanUnicode]
maoyanNumberList = [item.encode('utf-8') for item in maoyanNumberList]
items = parse_page(html)
for item in items:
item['score'] = item['score'].encode('utf-8')
for k in range(len(utf8List)):
item['score'] = item['score'].replace(utf8List[k], maoyanNumberList[k])
print(item['name'], item['score'].decode() + '万')
7.结果
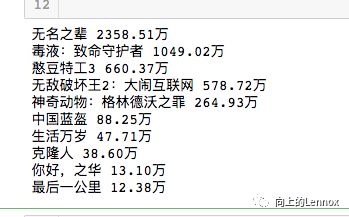
三.总结
在程序里面我是将字体转化为utf-8编码然后在用replace()得到对应数字的.其实之间也有操作过不转化为utf-8,直接用unicode编码.然后有个问题是unicode在python里面显示的是一堆堆框框,转化失败.发现根本没法.然后就只能老老实实的按大神的思路照着转化成utf-8.
在这里提一下,字体编码方式一定要统一,毕竟计算机不知道一和1是不是一样的.所以得编码统一,等以后研究透了为什么要转换成utf-8.我再来补充.