StructedStreaming 流程分析
导言
Spark在2.*版本后加入StructedStreaming模块,与流处理引擎Sparkstreaming一样,用于处理流数据。但二者又有许多不同之处。
Sparkstreaming首次引入在0.*版本,其核心思想是利用spark批处理框架,以microbatch(以一段时间的流作为一个batch)的方式,完成对流数据的处理。
StructedStreaming诞生于2.*版本,主要用于处理结构化流数据,与Sparkstreaming不同的是StructedStrreaming不再是microbatch的处理方式,而是可以"不停的"循环从数据源获取数据。从而实现真正的流处理。以dataset为代表的带有结构化(schema信息)的数据处理由于钨丝计划的完成,表现出更优越的性能。同时Structedstreaming可以从数据中获取时间(eventTime),从而可以针对流数据的生产时间而非收到数据的时间进行处理。
StructedStreaming的相关介绍可参考(http://spark.apache.org/docs/2.3.0/structured-streaming-programming-guide.html)。本文对StructedStreaming的流程/机制进行分析
开发structedStreaming应用
StructedStreaming应用开发流程
从官网/源码中可以看到structedstreaming应用的开发
除了spark的初始化工作,通常有三步与业务相关的操作:
-
获取输入数据源(可以理解为source)
val lines = spark .readStream .format("kafka") .option("kafka.bootstrap.servers", bootstrapServers) .option(subscribeType, topics) .load() .selectExpr("CAST(value AS STRING)") .as[String] 根据业务逻辑对数据进行转换处理 (业务处理)
wordCounts = lines.flatMap(_.split(" ")).groupBy("value").count()
- 将处理结果写入第三方数据源,整个流应用通过query.start启动(可以理解为sink)
query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.option("checkpointLocation", checkpointLocation)
.start()
query.awaitTermination()
流数据的读取
通过DataStreamReader类完成应用层与不同的流source源的reader隔离。load方法会为应用获取数据的逻辑
在处理数据源时框架使用serviceload机制,将所有集成DataSourceRegister的类加载如内存,判断对应source的shortName是否与设置的一致,如果一致,则实例化此类。并根据此类属性生成对应的dataframe。
当前支持的source源有如下:
| Source名 | Source源 |
|---|---|
| MemorySource | 测试用 |
| TextSocketSource | 用于展示使用 |
| FileStreamSource | 从固定目下下读文件 |
| KafkaSource | kafka作为数据源 |
| RateStreamSource | 固定速率的消息生成器,自增长的long型和时间戳 |
流数据的写出
数据的写出需要选择写出模式以及写出的sink源
写出模式:append,update,complete。 Structed streaming对写出模式的支持与数据处理时使用到的算子有关。需要根据需求,处理逻辑选合适的写出模式。可参考(http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#output-modes). Structed streaming对一些输出模式和算子的支持情况的校验可参考org.apache.spark.sql.catalyst.analysis.UnsupportedOperationChecker
sink源的写出:
在处理sink源时框架依然使用serviceload机制,将所有集成DataSourceRegister的类加载如内存,判断对应source的shortName是否与设置的一致,如果一致,则实例化此类
当前实现的sink
| Sink名 | sink目的地 |
|---|---|
| memorysink | 测试用 |
| foreachSink | 需要实现foreachwriter,用于定制化sink |
| kafkaSink | 写出数据到kafka |
| fileformatSink | 写出数据到hdfs。支持ORC,parquet等 |
StructedStreaming深入理解
对于structed streaming有如上理解即可开发相关应用。但structedstreaming的实现机制依然值得深究,尤其是structedstreaming是job是如何触发机制,watermark是如何实现的,状态数据是如何保存并用户应用恢复的。如下对这三个“问题”进行分析
About Trigger
与sparkstreaming基于定时器产生job然后调度的机制不同,structedstreaming实现了一套新的job触发机制(trigger)。类似于flink这就是trigger机制。
trigger的设置
通过DataStreamWriter.trigger()完成对trigger设置。默认的trigger为ProcessingTime(interval),interval默认为0
trigger的分类
trigger有三种,OneTimeTrigger只会触发一次计算。在流应用中一般使用ProcessingTime和ContinuousTrigger两种,下面对着两种trigger进行对比
| Trigger类 | ProcessingTime | Continuous |
|---|---|---|
| 对应execution | MicroBatchExecution | ContinuousExecution |
| 工作模式 | 以一定间隔(interval)调度计算逻辑,间隔为0时,上批次调用完成后,立即进入下一批次调用一直调用,退化为类似sparkstreaming的micro batch的流处理 | 以一定间隔(interval)查看流计算状态 |
| 支持API | 支持API丰富,如汇聚,关联等操作 | 仅简单的projection类(map,select等) |
| 备注 | total-cores个数大于partition数,task长时运行 |
ProcessingTime
在使用ProcessingTime Trigger时,对应的执行引擎为MicrobatchExecution。
Trigger调度机制如下:
override def execute(triggerHandler: () => Boolean): Unit = {
while (true) {
val triggerTimeMs = clock.getTimeMillis
val nextTriggerTimeMs = nextBatchTime(triggerTimeMs)
val terminated = !triggerHandler()
if (intervalMs > 0) {
val batchElapsedTimeMs = clock.getTimeMillis - triggerTimeMs
if (batchElapsedTimeMs > intervalMs) {
notifyBatchFallingBehind(batchElapsedTimeMs)
}
if (terminated) {
return
}
clock.waitTillTime(nextTriggerTimeMs)
} else {
if (terminated) {
return
}
}
}
}
ProcessingTime Trigger循环调度每执行逻辑:
triggerExecutor.execute(() => {
startTrigger()
if (isActive) {
reportTimeTaken("triggerExecution") {
if (currentBatchId < 0) {
// We'll do this initialization only once
populateStartOffsets(sparkSessionForStream)
...
} else {
constructNextBatch()
}
if (dataAvailable) {
currentStatus = currentStatus.copy(isDataAvailable = true)
updateStatusMessage("Processing new data")
runBatch(sparkSessionForStream)
}
}
// Report trigger as finished and construct progress object.
finishTrigger(dataAvailable)
if (dataAvailable) {
// Update committed offsets.
commitLog.add(currentBatchId)
committedOffsets ++= availableOffsets
currentBatchId += 1
sparkSession.sparkContext.setJobDescription(getBatchDescriptionString)
} else {
currentStatus = currentStatus.copy(isDataAvailable = false)
updateStatusMessage("Waiting for data to arrive")
Thread.sleep(pollingDelayMs)
}
}
updateStatusMessage("Waiting for next trigger")
isActive
})
ContinuousTrigger
在使用ContinuousTrigger时,对应的执行逻辑为continuousExecution。在调度时,Trigger退化为ProcessingTime Trigger。仅仅对执行状态查询,记录
Continuous执行逻辑
triggerExecutor.execute(() => {
startTrigger()
if (reader.needsReconfiguration() && state.compareAndSet(ACTIVE, RECONFIGURING)) {
stopSources()
if (queryExecutionThread.isAlive) {
sparkSession.sparkContext.cancelJobGroup(runId.toString)
queryExecutionThread.interrupt()
}
false
} else if (isActive) {
currentBatchId = epochEndpoint.askSync[Long](IncrementAndGetEpoch)
logInfo(s"New epoch $currentBatchId is starting.")
true
} else {
false
}
})
在ContinuousDataSourceRDD的compute方法中可以看出,其计算逻辑如下:
* 通过一个名为**continuous-reader--${context.partitionId()}--" +
s"${context.getLocalProperty(ContinuousExecution.EPOCH_COORDINATOR_ID_KEY)}** 的线程实时获取数据,放入名为queue的队列中。
* worker线程则长时间运行,在计算时则是从queue中实时获取消息处理。
About waternark
StructedStreaming的与sparkstreaming相比一大特性就是支持基于数据中的时间戳的数据处理。也就是在处理数据时,可以对记录中的字段的时间进行考虑。eventTime更好的代表数据本身的信息。
可以获取消息本身的时间戳之后,就可以根据该时间戳来判断消息的到达是否延迟(乱序)以及延迟的时间是否在容忍的范围内。该判断方法是根据watermark机制来设置和判断消息的有效性(延迟是否在可容忍范围内)
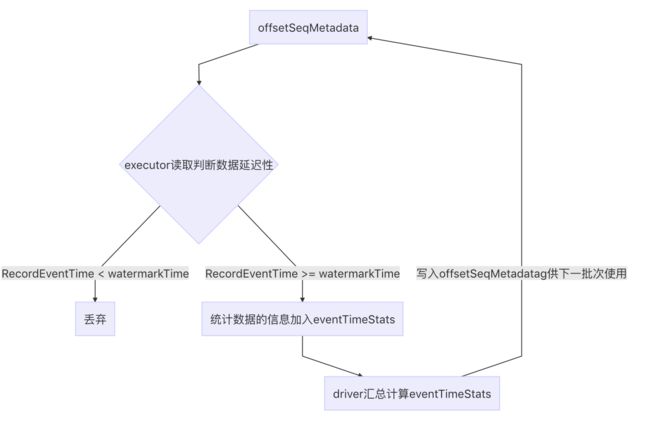
watermark的设置
通过dataset.withWatermark()完成对watermark的设置
watermark的生成/更新
在driver内注册一个累加器eventTimeStats;
-
在一个批次计算内,executor的各task根据各自分区内的消息的时间戳,来更新累加器
executor中各task获取分区的eventtime信息方式如下: 在EventTimeWatermarkExec中的doExecute方法中 iter.map { row => eventTimeStats.add(getEventTime(row).getLong(0) / 1000) row } def add(eventTime: Long): Unit = { this.max = math.max(this.max, eventTime) this.min = math.min(this.min, eventTime) this.count += 1 this.avg += (eventTime - avg) / count } -
在driver端生成batch时,获取各个操作/plan的watermark,找出操作的最小的watermark时间点,写入offsetSeqMetadata,同时写入offsetlog
// 计算各plan的watermark lastExecution.executedPlan.collect { case e: EventTimeWatermarkExec => e }.zipWithIndex.foreach { case (e, index) if e.eventTimeStats.value.count > 0 => logDebug(s"Observed event time stats $index: ${e.eventTimeStats.value}") val newWatermarkMs = e.eventTimeStats.value.max - e.delayMs val prevWatermarkMs = watermarkMsMap.get(index) if (prevWatermarkMs.isEmpty || newWatermarkMs > prevWatermarkMs.get) { watermarkMsMap.put(index, newWatermarkMs) } //找出watermark中最小值 if(!watermarkMsMap.isEmpty) { val newWatermarkMs = watermarkMsMap.minBy(_._2)._2 if (newWatermarkMs > batchWatermarkMs) { logInfo(s"Updating eventTime watermark to: $newWatermarkMs ms") batchWatermarkMs = newWatermarkMs } //写入offsetSeqMetadata offsetSeqMetadata = offsetSeqMetadata.copy( batchWatermarkMs = batchWatermarkMs, batchTimestampMs = triggerClock.getTimeMillis()) //写入offsetlog offsetLog.add( currentBatchId, availableOffsets.toOffsetSeq(sources, offsetSeqMetadata) -
根据watermark在读消息时过滤数据
StreamingSymmetricHashJoinExec -> doExecutor -> processPartitions -> StoreAndJoinWithOtherSide中有如下操作: val nonLateRows = WatermarkSupport.watermarkExpression(watermarkAttribute, eventTimeWatermark) match { case Some(watermarkExpr) => val predicate = newPredicate(watermarkExpr, inputAttributes) inputIter.filter { row => !predicate.eval(row) } case None => inputIter }
About state:
流应用中,如果有状态相关的如汇聚,关联等操作,需要再应用中将部分数据进行缓存,structedstreaming中通过statestore来对数据缓存以备后续计算及异常恢复使用
当前的statestore的实现仅HDFSBackedStateStore,由HDFSBackedStateStoreProvider生成和管理; 每个HDFSBackedStateStoreProvider对应一个目录。该目录为{storeName}.
其中checkpointLocation是query中设置的路径,storeName是store分类,在关联中有如如下storeType(如left-keyToNumValues)
每个statestore对应一个versionId.delta文件 {storeName}/versionId.delta。
状态数据的写入:
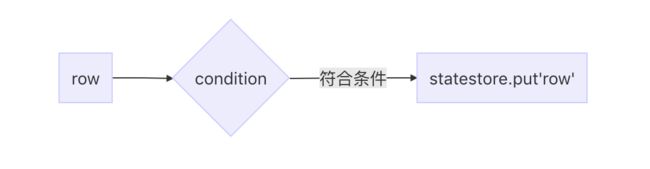
在在一些有状态的操作如关联汇聚等,部分数据需要保存以备后续计算使用,
store的put操作:
只有需要存储部分状态的操作/算子需要对状态数据进行缓存。从源码中查看,有如下算子:
StateStoreSaveExec
FlatMapGroupsWithStateExec
SymmetricHashJoinStateManager
以流关联操作为例,介绍SymmetricHashJoinStateManager中的state写流程如下:
1) 将数据写入state文件:在StreamingSymmetricHashJoinExec的doExecute方法中,调用到processPartitions,会调用到OneSideHashJoiner的storeAndJoinWithOtherSide方法,会根据条件判断该记录是否写入临时文件的输出流中。判断条件condition ( !stateKeyWatermarkPredicateFunc(key) && !stateValueWatermarkPredicateFunc(thisRow))
2) 在计算节结束后,将statestore数据写入磁盘
StreamingSymmetricHashJoinExec -> onOutputCompletion -> leftSideJoiner.commitStateAndGetMetrics -> joinStateManager.commit -> keyToNumValues.commit -> StateStoreHandler.commit -> HDFSBackedStateStore.commit
状态数据的读取:
在一些有状态的操作如关联汇聚等,需要对“历史/之前批次”数据进行“缓存”,以备下次计算时,读取使用。
有两处读取store的逻辑
1) statestoreRdd的compute方法
2)StreamingSymmetricHashJoinExec -> doExecutor -> processPartitions -> OneSideHashJoiner.init -> SymmetricHashJoinStateManager.init -> KeyToNumValuesStore.init -> getStateStore -> stateStore.get ->storeProvider.getStore
状态数据的管理/maintain
在executor内部,对于每一个分片启动一个线程定期“compact”中间数据,周期由spark.sql.streaming.stateStore.maintenanceInterval参数控制,默认为60s,线程名 : state-store-maintenance-task 主要工作是扫描delta文件,生成snapshot文件,清理陈旧文件。
生成snapshot文件具体逻辑:
1) 扫描目录下的文件,找出delta文件当前最大的版本号Max(d)(delta文件的命名方式Int.delta,版本号为Int值,如10.delta,则版本号为10)
2) 找出当前最大的snapshot文件的版本号Max(s)(delta文件的命名方式Int.snapshot,版本号为Int值,如10.snapshot,则版本号为10)
3) 当Max(d) - Max(s) 大于spark.sql.streaming.stateStore.minDeltasForSnapshot(默认为10)时,进行打快照操作。否则,跳过。
陈旧文件清理:
1) 找出当前文件的最大版本号Max(v)
2) MaxversionToRetain = Max(v) - spark.sql.streaming.minBatchesToRetain(默认100)时,当MaxversionToRetain > 0 时清理所有版本号小于MaxversionToRetain的文件。否则,跳过