mysql笔记十三:redo日志
关键字:redo日志、mtr、log buffer、redo日志文件、lsn、checkpoint
13.1、什么是redo日志
(1)什么是redo日志
当一个事务提交之后,为了满足持久性的要求,理论上应该将此事务修改的所有页从buffer pool中刷新到磁盘上,事务才算完成。以避免内存中的脏页还没刷新到磁盘上,数据库宕机而导致事务失败。
但是刷脏页的操作是费时且效率低下的,所以innodb没有采用上述策略,而是将修改的数据暂时记录到一个日志文件中,这个日志文件就称为redo日志文件。如果后续数据库宕机,那么下次重启数据库还是可以通过redo日志来恢复数据的。如果后续数据库没有宕机,脏页也被刷新到了磁盘上,那么这块记录的日志就没用了,可以用一个标记来标记哪个位置后面的日志是有用的,这种操作称为checkpoint。
redo日志记录的就是对页面修改的详细信息。
(2)redo日志的作用:
因为刷脏页的操作非常耗时,一般是在后台线程执行的。非万不得已,不会在用户线程中刷脏页,但是如果事务提交了,脏页没有及时刷新,在后续刷新脏页过程中,服务器宕机或者停电了,那么事务的持久性就不能保证了。redo日志就是保证服务器在宕机重启后,将丢失的事务数据从日志中恢复过来,如果服务器不宕机的话,那么redo日志也是没用的,反而是累赘。
13.2、mini-transaction
mysql规定一些操作是不可分割的最小单元,对这些操作的一次原子访问称为一个mini-transaction,简称mtr。这些操作有:
(1)更新Max Row Id属性(更新一页)
(2)向聚簇索引对应的B+树的页面插入一条记录(可能更新多个页面)
(3)向某个二级索引对应的B+树的页面插入一条记录(可能更新多个页面)
(4)其他的对页面的访问操作
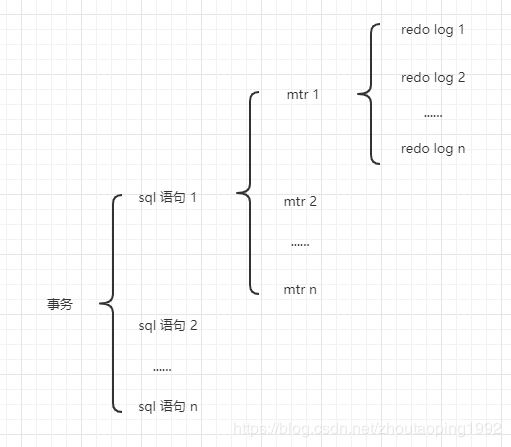
所以一个mtr可能会产生多条redo日志,这些redo日志可以归为一组,称为redo日志记录组(redo log record group)。
一条sql语句(比如insert)可能会操作多棵B+树,所以一条sql语句会包含多个mtr。
一个事务可能包含多条sql语句。
所以,事务、sql语句、mtr、redo log的关系如下:
13.3、redo log buffer
13.3.1、什么是redo log buffer
redo日志并不是立即写到磁盘上的,而是先缓存在内存中。在某些时刻,才会刷入磁盘。这块内存区域成为redo log buffer,这块区域默认16MB,可以通过系统参数innodb_log_buffer_size来设置。
13.3.2、刷盘时机
从redo log buffer刷入日志到磁盘的时机有:
(1)事务提交时
为了保证事务的持久性,在事务提交时,就必须把redo log buffer上的数据刷新到磁盘上。
(2)log buffer使用的空间不足时
当log buffer不够用了,那么会刷入一些数据到磁盘上,腾出一些空间。
(3)后台线程每秒1刷
(4)mysql数据库正常关闭时
13.3.3、redo log buffer的结构
redo log buffer默认是16M,他是由一堆redo log block组成,每个redo log block的大小是512B,所以默认情况下,redo log buffer中有32000个redo log block。
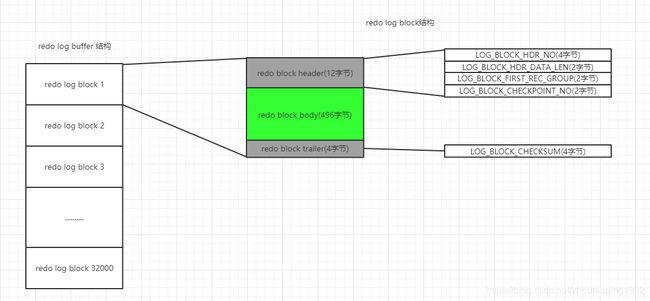
13.3.4、redo log block的结构
redo log block的大小是512B,它的结构如图:
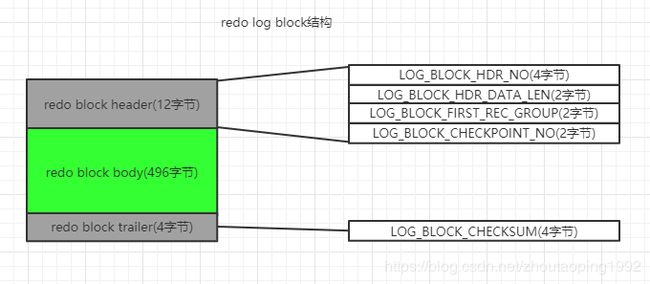
(1)redo block header
a)LOG_BLOCK_HDR_NO(4字节):redo log block的编号
b)LOG_BLOCK_HDR_DATA_LEN(2字节):该block使用的多少字节,初始值12,最大值512
c)LOG_BLOCK_FIRST_REC_GROUP(2字节):该block第一个redo日志组的偏移量。
d)LOG_BLOCK_CHECKPOINT_NO(2字节):
(2)redo block body
redo日志都存在redo block body中
(3)redo block trailer
LOG_BLOCK_CHECKSUM(4字节):校验和,和redo block header中LOG_BLOCK_HDR_NO(4字节)一样。
13.4、redo日志文件
redo日志写到redo log buffer中,最终会被刷盘到磁盘上的文件中,这个文件默认在数据目录下,共有2个文件,分别叫ib_logfile0和ib_logfile1,每个文件默认48M。这些值都可以通过系统变量来改变。
redo日志文件有多个,组成redo日志文件组。日志文件刷盘就是循环往这几个文件中写数据。
13.4.1、redo日志文件结构
其实redo日志文件的结构和redo log buffer的差不多,只是block数量更多,且前4个block另做他用。
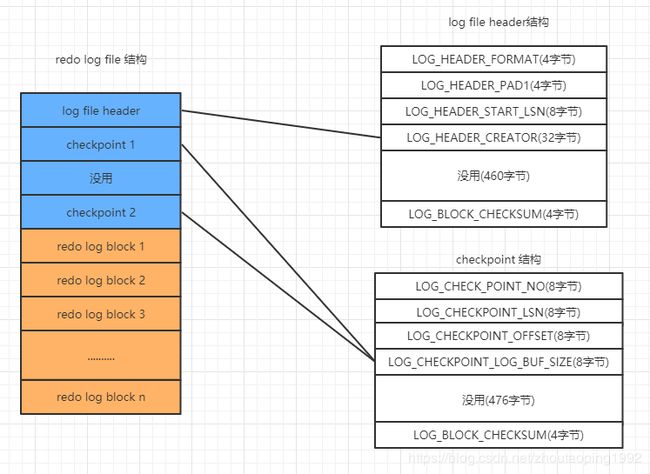
13.4.2、两个checkpoint
两个checkpoint交替写入,避免了因为介质失败导致无法找到可用的checkpoint的情况。
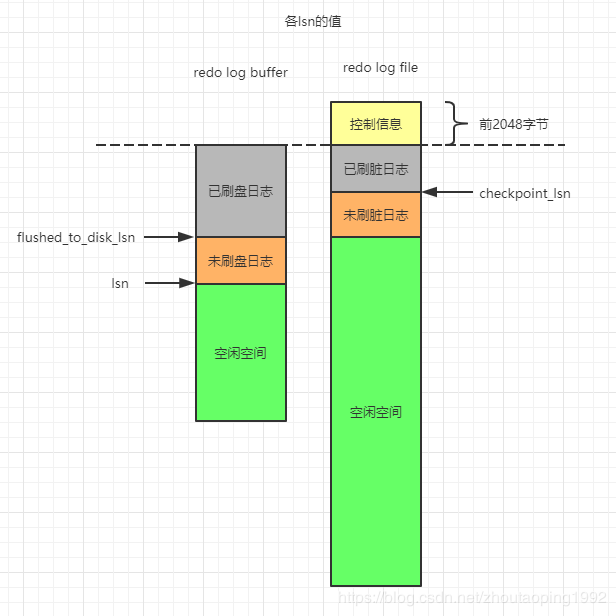
13.5、LSN
13.5.1、LSN
redo日志不是一条一条的写入到redo log buffer中的,而是以一个mtr为单位,将一个redo日志记录组一起写入到redo log buffer中的。
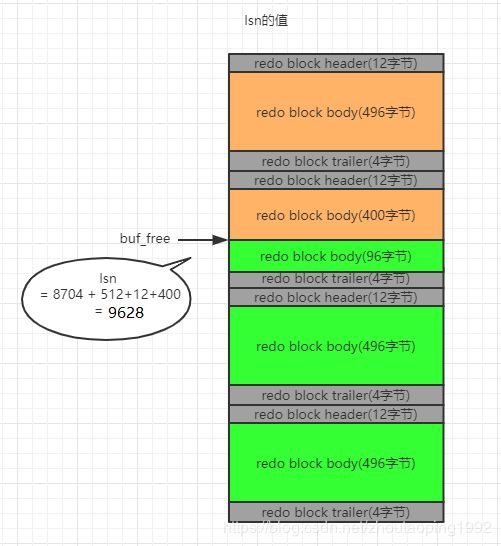
每次写入一组redo日志记录组,mysql都会维护两个值。
一个是全局变量buf_free,他代表着,当前redo日志写入redo log buffer的偏移,下次再写入日志时,就知道从哪个偏移开始写了,但是如果log buffer满了,buf_free就会从头开始。
另一个就是lsn了,他的初始值是8704,每写入一组日志,他的值都会增长写入的日志组长度+跨越的log block header和log block trailer的长度。
LSN的值只会变大,不会变小。
LSN的值就反应了写入log buffer中日志的总量
13.5.2、flush_to_disk_lsn
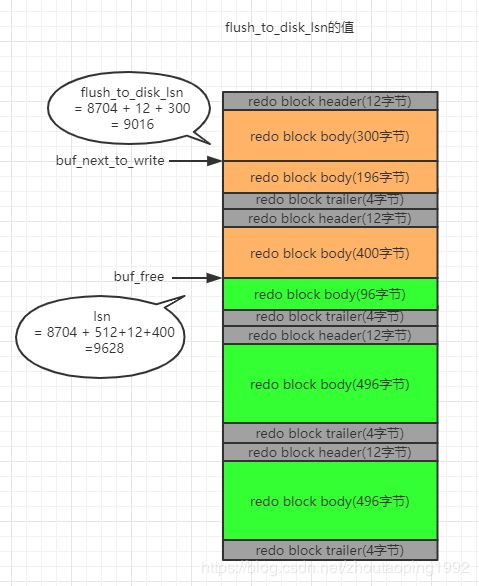
redo log buffer的数据最终都会被刷新到redo日志文件中,那么现在究竟刷新到什么位置了呢,mysql维护了两个值来记录。
一个是buf_next_to_write,他是redo log buffer的偏移量。
另一个就是flush_to_disk_lsn了,他的初始值也是8704,并且随着刷入磁盘的日志推移而不断变大。一般情况,flush_to_disk_lsn小于lsn,如果lsn的值和flush_to_disk_lsn的值一样,那么说明redo log buffer中的数据全部被刷新到磁盘上了。
13.5.3、flush链表中的LSN的值
buffer pool中的flush链表是脏页链表,这些脏页对应的控制信息块中维护了两个变量来记录这些脏页对应的redo日志的lsn值,以方便脏页刷新后,更新redo日志文件的有效位置。
两个变量分别是:
(1)oldest_modification
该页面第一次被修改时,修改页面的mtr开始的lsn的值
(2)newest_modification
该页面最后一次被修改时,修改页面的mtr结束的lsn的值
flush链表是按照oldest_modification的值从大到小排序的,所以后台线程每次从链表末端刷脏页时,刷的脏页的oldest_modification是flush链表中最小的。也就是说,在redo日志文件中,小于这个页面的oldest_modification的值的redo日志其实是没用的了,因为这些redo日志对应的脏数据已经被刷新到磁盘上了。
13.5.4、checkpoint_lsn
见13.6checkpoint
13.6、checkpoint
当一个脏页被刷新到磁盘上了,那么这个脏页之前记录的redo日志就是没用的了,可以被覆盖了。mysql定义了一个checkpoint_lsn的变量维护了哪些redo日志是可以被覆盖的,每次刷脏页时,就会去增加checkpoint_lsn的值并将相关数据写入redo日志文件的checkpoint1或checkpoint2部分,这个操作称为checkpoint操作。
checkpoint_lsn的初始值也是8704。
checkpoint_lsn的值就等于当前刷的脏页的oldest_modification的值。