VMware CentOS6.5 Hadoop3+Zookeeper集群搭建
一、vmware Centos6.5虚拟机准备
1. 使用同一用户learn ,安装三台CentOS6.5系统虚拟机,分别为vm1, vm2, vm3。
vm1 和vm2 作为 nameNode + DataNode
vm3 只作为DataNode
2. 通过NAT或者桥接模式分别为vm1,vm2, vm3设置网络。文中采用NAT方式, ip地址分别为:
vm1: 192.168.60.128 vm1.learn.com
vm2: 192.168.60.130 vm2.learn.com
vm2: 192.168.60.131 vm3.learn.com
保证相互之间可以ping通, 且/etc/hosts文件配置各节点host。
注释掉以下两行,或者不配置vm1.learn.com和127.0.0.1/::1的映射:
127.0.0.1 vm1.learn.com localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 vm1.learn.com localhost localhost.localdomain localhost6 localhost6.localdomain6
vm1.learn.com 不能映射到127.0.0.1或者::1中, 否则无法启动hadoop集群failed on connection exception: java.net.ConnectException: 拒绝连接。
参考: https://wiki.apache.org/hadoop/ConnectionRefused
3. 为每台机器设置SSH免密登录, 参见:https://blog.csdn.net/zhujq_icode/article/details/82629745
二、Zookeeper集群搭建
参见:https://blog.csdn.net/zhujq_icode/article/details/82687037
三、Hadoop3集群搭建
1. 下载Hadoop3 安装包, 文中下载的是:hadoop-3.0.3.tar.gz
2. vm1中解压安装包至安装目录/home/learn/app/hadoop/:
tar -zxvf hadoop-3.0.3.tar.gz -C /home/learn/app/hadoop/3. 配置环境变量, 添加至 /etc/profile
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/home/zhujq/app/hadoop/hadoop-3.0.3
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${PATH}
若未安装java, 先安装java 8.
4. 配置hadoop
(1)hadoop-env.sh文件设置JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_181(2)core-site.xml
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/home/learn/data/hadoopcluster/tmp
ha.zookeeper.quorum
vm1.learn.com:2181,vm2.learn.com:2181,vm3.learn.com:2181
(3)hdfs-site.xml
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
vm1.learn.com:9820
dfs.namenode.rpc-address.mycluster.nn2
vm2.learn.com:9820
dfs.namenode.http-address.mycluster.nn1
vm1.learn.com:9870
dfs.namenode.http-address.mycluster.nn2
vm2.learn.com:9870
dfs.ha.automatic-failover.enabled
true
dfs.namenode.shared.edits.dir
qjournal://vm1.learn.com:8485;vm2.learn.com:8485;vm3.learn.com:8485/mycluster
dfs.journalnode.edits.dir
/home/learn/data/hadoopcluster/data/journaldata/jn
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/learn/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
(4)mapred-site.xml
mapreduce.framework.name
yarn
采用yarn框架
(5) yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yarn-rm-cluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
vm1.learn.com
yarn.resourcemanager.hostname.rm2
vm2.learn.com
yarn.resourcemanager.zk-address
vm1.learn.com:2181,vm2.learn.com:2181,vm3.learn.com:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
(6) workers节点配置
vm1.learn.com
vm2.learn.com
vm3.learn.com
5. 复制安装文件及配置文件至另外两台机器vm2,vm3
四、集群初始化
1. vm2节点上初始化HDFS(格式化文件系统)
hdfs namenode -format将初始化后的文件复制到同作为nameNode的vm1机器上:
[learn@ ~]# scp -r /home/learn/data/hadoopcluster/tmp/ [email protected]:/home/learn/data/hadoopcluster/
fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
fsimage_0000000000000000000 100% 350 0.3KB/s 00:00
VERSION 100% 200 0.2KB/s 00:00 2. vm2节点格式化ZK
hdfs zkfc -formatZK
五、启动hadoop集群
1. vm2启动dfs
[learn@vm2 sbin]$ ./start-dfs.sh
Starting namenodes on [vm1.learn.com vm2.learn.com]
Starting datanodes
Starting journal nodes [vm1.learn.com vm2.learn.com vm3.learn.com]
2018-09-13 15:15:54,975 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting ZK Failover Controllers on NN hosts [vm1.learn.com vm2.learn.com]
2. 通过jps观察vm1,vm2,vm3是否都正常启动
//vm1 NameNode DataNode
[learn@vm1 sbin]$ jps
9969 Jps
9618 DataNode
9867 DFSZKFailoverController
9726 JournalNode
3118 QuorumPeerMain
9534 NameNode
//vm2 NameNode DataNode
[learn@vm2 sbin]$ jps
10913 NameNode
2562 QuorumPeerMain
11268 JournalNode
11597 Jps
11037 DataNode
11486 DFSZKFailoverController
//vm3 DataNode
[learn@vm3 sbin]$ jps
6067 JournalNode
2581 QuorumPeerMain
6166 Jps
5963 DataNode
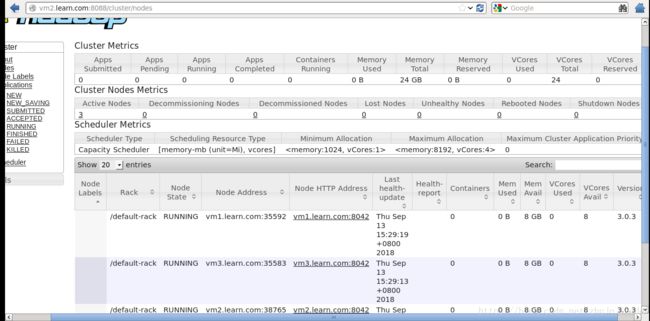
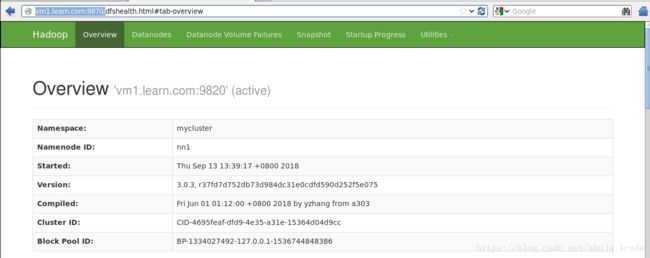
3. WEB UI http://vm1.learn.com:9870/ http://vm2.learn.com:9870/


4. vm1启动yarn
jps发现vm1 和 vm2节点新增进程:
11845 NodeManager
11767 ResourceManager