ElasticSearch 极简入门 CRUD
如今大数据横行天下,如何快速存储和查看应用数据变得必不可少,搜索便引擎顺势而生。ElasticSearch 底层依赖 Lucene 在其上进行大量简化封装,并具备高可用,分布式等特点,最主要是周边产品丰富 Logstash Kibana Beats 套件的完善,让ElasticSearch 得到长足和快速的发展,也是如今各个公司必不可少的基础架构组件。
在本场 Chat 中,会讲到如下内容:
ElasticSearch 的安装 (6.8 版本)Kibana DevTool 的是使用创建索引,删除索引数据写入,更新,删除数据修改乐观锁数据路由及其原理日期类型处理 - Mapping 定义QueryString 查询语法聚合查询SQL 查询
0. 环境总览
| 项目 | 版本 |
|---|---|
| 系统 | Aliyun CentOS Linux release 7.5.1804 (Core) |
| jdk | 1.8 |
| ElasticSearch | 6.8.2 |
| Kibana | 6.8.2 |
Jdk 的安装咱们就略过吧,假设读者会自己安装 Jdk 下方统一使用 ES 来代替 ElasticSearch
1. ElasticSearch 安装和简要配置
## 1.1 下载安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.2.tar.gz 下载有些慢,大家可以事先下载到本地然后上传到服务器中
1.2解压
tar -zxvf elasticsearch-6.8.2.tar.gz
1.3 ES 用户
ES 启动不允许使用 root 用户如果 root 启动会报如下错误![]()
创建用户
[root@39 soft]# groupadd es 用户组[root@39 soft]# useradd es -g es 用户并指定用户组[root@39 soft]# chown -R es:es /usr/local/soft/elasticsearch-6.8.2 修改目录权限[root@39 soft]# mkdir -p /data/es 创建数据存储目录[root@39 soft]# chown -R es:es /data/es 修改权限1.4 配置修改
修改配置文件:
vim /usr/local/soft/elasticsearch-6.8.2/config/elasticsearch.yml
基本配置:
- cluster.name: my-es 集群名称集群中要配置一样的名字
- node.name: node-1 节点名称,每个节点不能重复
- path.data: /data/es/data 索引数据存储
- path.logs: /data/es/logs es 的 log 输出位置
- bootstrap.systemcallfilter: true
- network.host: ip 注意这个 ip 写你内网的 ip 或者 0.0.0.0 ,我的阿里云就不能写外网 ip 会报错Exception BindTransportException[Failed to bind to [9300-9400]]
- http.port: 9200 http 对外的端口
当然如果做集群的话还有集群相关的配置,这里不再赘述
系统配置:
vim /etc/sysctl.conf 文件末尾加入 vm.maxmapcount=262144 不然会报错: max virtual memory areas vm.maxmapcount [65530] likely too low, increase to at least [262144]
vim /etc/security/limits.conf 添加如下内容: root soft nofile 65536 root hard nofile 65536 es soft memlock unlimited es hard memlock unlimited * soft nofile 65536 * hard nofile 65536
vim /etc/security/limits.d/90-nproc.conf 添加如下内容: * soft nproc 4096 root soft nproc unlimited
以上两个配置入够不添加 可能会报如下错误:
max file descriptors [10240] for elasticsearch process likely too low, increase to at least [65536] max number of threads [1024] for user [es] likely too low, increase to at least [2048]
1.5 启动
如上配置好之后 我们执行如下脚本:
./bin/elasticsearch -d 后台启动 tail -100f /data/es/logs/my-es.log 查看日志 ,没什么异常就算启动成功了
1.6 验证
浏览器访问 ip:9200 会返回如下 json 会有我们配置的集群名称,节点名称,es 版本,lucene 版本 等信息
{ "name" : "node-1", "cluster_name" : "my-es", "cluster_uuid" : "Q2G52GG1QuiULzOhHoeiAw", "version" : { "number" : "6.8.2", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "b506955", "build_date" : "2019-07-24T15:24:41.545295Z", "build_snapshot" : false, "lucene_version" : "7.7.0", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search"}如上我们的 es 就算能够使用了!
Kibana 认识
Kibana 我们只用它的 DevTools 模块 ,因为这个功能简化了 http 的访问操作,并且有语法提示,比较好入门,极力安利给大家。
 版本 6 相对于 5 来说,有了不少改变呢,笔者也第一次使用 6 , 之前一直使用 5.6 进行生产开发。
版本 6 相对于 5 来说,有了不少改变呢,笔者也第一次使用 6 , 之前一直使用 5.6 进行生产开发。
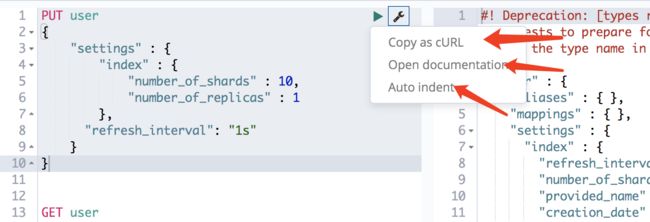
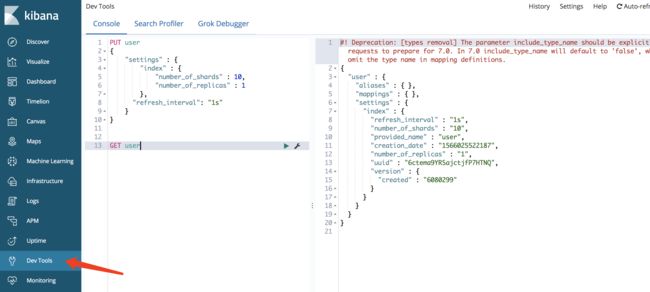
- 拷贝成 crul 语法格式
curl -XPUT "http://localhost:9200/user" -H 'Content-Type: application/json' -d' { "settings" : { "index" : { "numberofshards" : 10, "numberofreplicas" : 1 }, "refresh_interval": "1s" } }'
- 直接打开这个操作的文档说明
- 格式化,相当于 json 的自动格式化操作
索引创建和删除
基本概念:
- index 索引
- type 索引中的类型,一个索引可以有多个 type
- document 文档也就是索引中的一条数据
索引 (index) , 可以理解成数据库中的一个表,很多文章中描述 index 理解成数据中的一个库,type 理解成一个表, 个人不敢苟同,本身 type 的使用要求是:大部分字段相同,少部分字段不相同可以放入一个 index 的不同 type 中,这理解成数据中的表就不大合适了,而且,在7.0 的版本中对 type 的操作已经完全弱化了,渐渐的就会去掉这个东西了,因此 index 我一直就是理解成一张表,求同存异哈。
创建索引
PUT user{ "settings" : { "index" : { "number_of_shards" : 10, "number_of_replicas" : 1 }, "refresh_interval": "1s" }}- numberofshards 分片数量 每个索引产生多少个分片在集群中,最好平均分布,不宜过多也不能少,如果单机的就没有必要设置很多了 1 个就可以了,这个后期是不能改的
- numberofreplicas 副本数量 为了高可用
- refresh_interval 数据能够刷新时间 默认是 1s
查询索引信息:
GET user查询返回结果:
{ "user" : { "aliases" : { }, "mappings" : { }, "settings" : { "index" : { "refresh_interval" : "1s", "number_of_shards" : "10", "provided_name" : "user", "creation_date" : "1566025522187", "number_of_replicas" : "1", "uuid" : "6ctema9YRSajctjfP7HTNQ", "version" : { "created" : "6080299" } } } }}删除索引:
DELETE user
数据写入
我们知道数据库创建表需要指定字段名称,类型,ES 能够自动识别类型,但是有的类型也并不是那么智能。比如日期,比如 geo 等格式。因此我们还是需要提前定义一些字段类型的,这就是 ES 中的 mapping 定义,你可以理解成就是用来定义数据类型的
mapping 创建
POST user/type1/_mappings{ "type1": { "properties": { "birthday" : { "type": "date" }, "id" : { "type" : "long" }, "name" : { "type" : "keyword" }, "cat" : { "type" : "keyword" }, "cat1" : { "type" : "keyword" }, "remark" : { "type" : "text" } } }}返回#! Deprecation: [types removal] Specifying types in put mapping requests is deprecated. To be compatible with 7.0, the mapping definition should not be nested under the type name, and the parameter include_type_name must be provided and set to false.{ "acknowledged" : true}这里我们可以看到 type 将在 7.0 之后被移除了!data : 日期long : 数字keyword : 不分词, 按原样存储text : 会被分词
keyword 还有一个用处,就是在聚合的时候,你分组的条件字段如果是 text 的, 那么需要使用 field.keyword 来聚合预定义 mapping 还有一个好处,就是能够优化存储,比如 name , 如果使用的时候是全量匹配查询那么就不需要对其进行分词直接设定 keyword 类型就可以了
定义好 mapping 之后 我们开始写入数据
POST user/type1{ "id":2, "name":"huizi", "birthday": 1566027812714, "cat" : "c1", "cat1" : "b1", "remark" : "我爱中华人民共和共"} 返回报文{ "_index" : "user", "_type" : "type1", "_id" : "HfWJnmwBhSIaVWCoiahh", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1}再多写入一条数据POST user/type1{ "id":3, "name":"huizi3", "birthday": 1566027813714, "cat" : "c1", "cat1" : "b2", "remark" : "我爱中华人民共和国"}数据更新
id更新
局部更新POST user/type1/HfWJnmwBhSIaVWCoiahh/_update{ "doc" : { "name":"huizi2" }}全量更新PUT user/type1/HfWJnmwBhSIaVWCoiahh{ "id":2, "name":"huizi2", "birthday": 1566027812714, "cat" : "c1", "cat1" : "b1", "remark" : "我爱中华人民共和共"}乐观锁更新我们看第一条数据 _version : 版本号 _seq_no : 序列号,冲突检测 _primary_term : 主重新选举会递增,主要处理当 seq 一样时候的文档冲突
_version : 版本号 _seq_no : 序列号,冲突检测 _primary_term : 主重新选举会递增,主要处理当 seq 一样时候的文档冲突
在早起版本中 冲突使用时 version 来控制的,在后期的 6.x 版本中引入了两个字段来解决冲突问题乐观锁控制官方链接
我们执行一个这样的语句:
PUT user/type1/HfWJnmwBhSIaVWCoiahh?if_seq_no=3&if_primary_term=1{ "id":2, "name":"huizi2", "birthday": 1566027812714, "cat" : "c1", "cat1" : "b1", "remark" : "我爱中华人民共和共"}返回:{ "error": { "root_cause": [ { "type": "version_conflict_engine_exception", "reason": "[type1][HfWJnmwBhSIaVWCoiahh]: version conflict, required seqNo [3], primary term [1]. current document has seqNo [4] and primary term [1]", "index_uuid": "hteuG0t0TEWgw3r4nXxT7Q", "shard": "6", "index": "user" } ], "type": "version_conflict_engine_exception", "reason": "[type1][HfWJnmwBhSIaVWCoiahh]: version conflict, required seqNo [3], primary term [1]. current document has seqNo [4] and primary term [1]", "index_uuid": "hteuG0t0TEWgw3r4nXxT7Q", "shard": "6", "index": "user" }, "status": 409}从异常堆栈中我们能看到 版本冲突的字样, 并且告诉你 seqNo=3 小于当前的 seqNo=4数据删除
id 删除
DELETE /user/type1/HfWJnmwBhSIaVWCoiahh条件删除:
POST user/type1/_delete_by_query{ "query": { "term": { "name": "huizi2" } }}乐观锁删除
同更新一样,这里不做演示了
路由
ES 中的数据时如何确定要写入那个分片(shard)中的?
shard = hash(routing) % numberofprimary_shards 路由字段进行 hash 然后 对分片数量取余操作 这又回答了另一个问题 - 索引中分片数量确认好之后就不能更改了!
试想如果这个路由值我们自己制定,那么我们就知道我们这条数据存储在哪个分片中了, 相应的我们在查找的时候就能直接定位分片,不需要搜索每一个分片了。
这就是路由的好处,能够直接确定你路由的数据在哪个分片中,不需要在所有分片中查找数据了
我们来看一个实例:
写入一条数据 带有路由值是 10 POST user/type1?routing=10{ "id":10, "name":"huizi3", "birthday": 1566027813714, "cat" : "c1", "cat1" : "b2", "remark" : "我爱中华人民共和国"}查询一条数据 根据路由值GET /user/type1/_search?q=id:10&routing=10查询不根据路由值GET /user/type1/_search?q=id:10没路由值的返回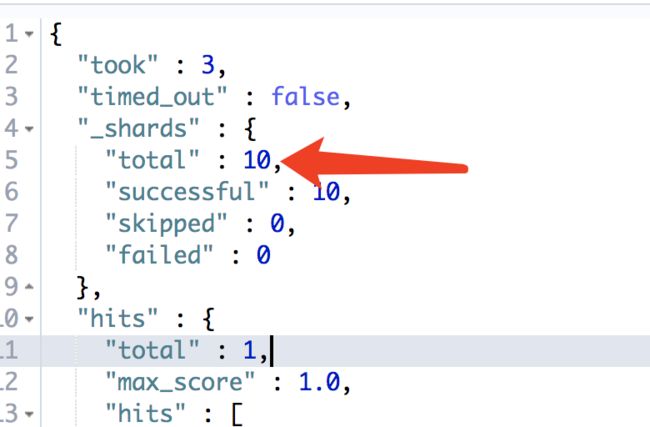 有路由值的返回
有路由值的返回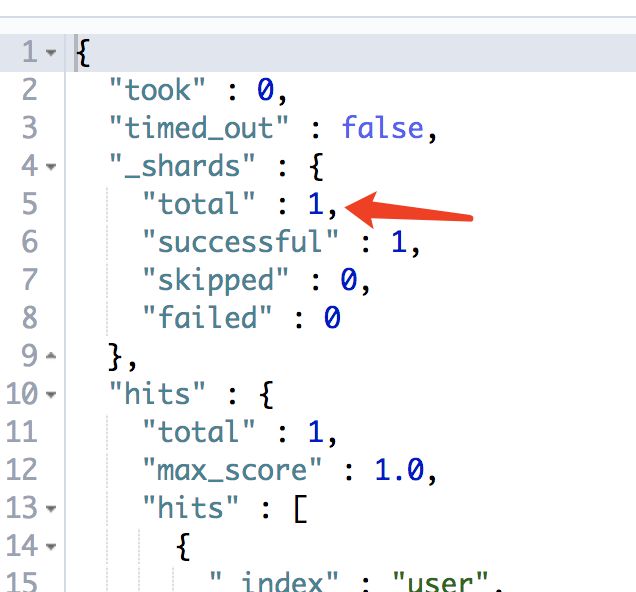 从这两种图我们可以验证上方的想法:有路由值会直接定位到某一个分片中箭头处 total=1 ,没有路由的返回 total=10
从这两种图我们可以验证上方的想法:有路由值会直接定位到某一个分片中箭头处 total=1 ,没有路由的返回 total=10
那有朋友会问性能能提高多少?我测试的千万级数据,4 台物理机 10 个分片, 有路由和无路由大约相差 3-4 背的差距,当然这个跟你的服务器你的数据都有很大关系,制作参考。
还有朋友要问如果我需要多个路由字段怎么办,那没办法,你只能想办法映射成一个。同样 Redis Cluster 的 hash 槽也有这个问题,如果想把一些相同特征的数据路由到同一个槽中怎么办?它给出了 hashtag 这样一个概念 比如: 0000{11}9999 这种写法就只使用 11 去做 hash。哎,你说这操作骚不骚,这样就能把有相同特征的数据映射到同一个 hash 槽了。
那么我们怎么做? 举个栗子用户和订单的场景,我们一般查询会按照用户查询或者按照订单查询,我们按照谁去路由呢?可以这样做,我们生成的订单号中固定位置包含用户 id 的一部分信息。比如用户 id = 12345678 , 我们生成的订单号 可以这样 xxxxxx78xx , 把用户号的后两位放到订单的某个固定位置,这样我们存储的时候,从订单号中拿到那固定的 2 位来做路由值。这样我们根据用户和订单都能拿到路由值了。
那么又会有朋友问了, 这样你一个用户的数据都路由到一个分片上,是不是会产生不均匀呢?那!是!肯!定!的! 哪有绝对公平的事情呢?
QueryString 查询语法
基本语法: this AND that AND thus OR (a AND b AND c)
直接使用 ?查询 GET /user/type1/_search?q=id:10&routing=10
直接使用 ?查询 GET /user/type1/_search?q=id:10&routing=10使用 json 查询GET /user/type1/_search{ "query": { "query_string": { "default_field": "*", "query": "中国" } }}常用查询:
| 说明 | 样例 |
|---|---|
| 字段包含查询 | status:active |
| 组合查询 | title:(quick OR brown) |
| 短语精确查询 | author:"John Smith" |
| 字段是否存在 | exists:title |
| 通配符查询 | bro* |
| 正则查询(慎用极慢) | name:/joh?n(ath[oa]n)/ |
| 日期范围 | date:[2012-01-01 TO 2012-12-31] |
| 数字范围 | count:[1 TO 5] |
| 数字范围 >=10 | count:[10 TO *] |
| 日期范围<2012 | date:{* TO 2012-01-01} |
| 年龄大于10 | age:>10 |
范围中 [] 标识闭区间即包含, {} 标识开区间即不包含
基本上认识这些常用的查询基本的查询工作都能胜任了。
聚合
GET /user/type1/_search{ "from": 0, //分页起始位置 "size": 0, //分页大小 一般聚合分组不取原始数据 "query": { "query_string": { "default_field": "*", "query": "*" // 查询条件 就是sql 中的 where } }, "aggs": { // 聚合开始 "t1": { //第一层聚合 这是一个标识, 再返回的时候有用 "terms": { "field": "cat1", /// 使用term 分组, 如果字段是text类型的 需要加 .keyword 分组 "size": 10, ///分组后取多少数据 "order": { "_count": "asc" //按什么排序,这个计数的有_count , 如果 MAX 则有 _max 值排序,其他相似 } }, "aggs": { /// 第二层聚合 "t2": { "terms": { "field": "cat", "size": 10 } } } } }}这个聚合就类似但不完全是 select * from user where 1=1 group by cat, cat1 order by xxx
常用的还有 datehistogram, rang 分组,时序中使用最多的就是 datehistogram 日期直方图分组
鉴于 ES 的 API 实在太多了,无法一一列举,只说明一些常用的查询。
我们来看一个超级大查询:
GET xxxxx*/_search{ "size":500, 取500条数据 "sort":[ { "@timestamp":{ "order":"desc" //按时间倒叙 } } ], "query":{ "bool":{ "must":[ { "query_string":{ "query":"SocketInputStream.java", // 查询条件 "analyze_wildcard":true } }, { "range":{ ///时间范围查询 "@timestamp":{ "gte":1550446616805, "lte":1550489816805, "format":"epoch_millis" } } } ] } }, "aggs":{ "2":{ "date_histogram":{ 日期直方图 "field":"@timestamp", 按时间字段分组 "interval":"10m", 每10分钟进行分组 "time_zone":"Asia/Shanghai", //时区- 一定要加 "min_doc_count":1, "format": "yyyy-MM-dd HH:mm:ss.SSS" 时间格式化 } } }, "stored_fields":[ "*" ], "docvalue_fields":[ "@timestamp", "ctime" ], "highlight":{ 高亮设置 "pre_tags":[ "@kibana-highlighted-field@" 高亮前后标签 ], "post_tags":[ "@/kibana-highlighted-field@" ], "fields":{ "*":{ "highlight_query":{ 高亮查询 "bool":{ "must":[ { "query_string":{ "query":"SocketInputStream.java", "analyze_wildcard":true, "all_fields":true } }, { "range":{ "@timestamp":{ "gte":1550446616805, "lte":1550489816805, "format":"epoch_millis" } } } ] } } } } }}其实上边这个查询就是 Kibana DIscover 的首页查询 包括了,原始数据 500 条,日期直方图分组每十分钟,高亮查询。
从上边我们看到 ES 的查询基于 json 的格式,相当的繁琐又不好记忆,基本都需要去官网查询 API 才能会写,那么 ES 有没有类 SQL 的引擎呢?
SQL 查询演示
ES 也一直在尝试引入 SQL , 估计由于过于繁琐的原因从版本 5 开始就引入的试验性功能,一直到 6.7 才算毕业成为正式功能,可以应用于生产。 https://www.elastic.co/guide/en/elasticsearch/reference/6.8/sql-syntax-select.html
基本查询
会 SQL 的欧能看懂哈SELECT select_expr [, ...][ FROM table_name ][ WHERE condition ][ GROUP BY grouping_element [, ...] ][ HAVING condition][ ORDER BY expression [ ASC | DESC ] [, ...] ][ LIMIT [ count ] ]基本查询POST /_xpack/sql?format=txt{ "query": "select * from user"}
where 条件查询POST /_xpack/sql?format=txt{ "query": "select * from user t where t.cat1='b2'"}来一个官网的超级例子SELECT MIN(salary) AS min, MAX(salary) AS max, MAX(salary) - MIN(salary) AS diff FROM emp GROUP BY languages HAVING diff - max % min > 0 AND AVG(salary) > 30000;SQL 引擎执行其实是将 SQL 语句转换成 ES 可识别的 JSON 然后进行查询,因此官方也提供了翻译 API
POST /_xpack/sql/translate{ "query" : "select cat1 from user t where birthday > 'now-1y' group by cat1 "}下面的返回是自动给我们翻译的,很吊有没有{ "size" : 0, "query" : { "range" : { "birthday" : { "from" : "now-1y", "to" : null, "include_lower" : false, "include_upper" : false, "boost" : 1.0 } } }, "_source" : false, "stored_fields" : "_none_", "aggregations" : { "groupby" : { "composite" : { "size" : 1000, "sources" : [ { "221" : { "terms" : { "field" : "cat1", "missing_bucket" : true, "order" : "asc" } } } ] } } }}使用限制 英文水平有限 就不翻译了 https://www.elastic.co/guide/en/elasticsearch/reference/6.8/sql-limitations.html
使用建议: 6.7 版本出来大概也就半年多时间, SQL 这种查询在稳定性和效率上并无多少实例验证,因此如果
结尾
ES 如今的火爆程度不言而喻,任何培训中心也好,新启项目也好都会有 ES 的身影 发布版本频繁,推陈出新速度 准实时 API 详尽,功能强大 周边配套完善 beat, logstash, kibana 套件 还不赶快学习起来,本文如果仅仅能带你入门也是好的 后期会分享一些查询优化方面的东西
同时欢迎大家订阅我的其他 Chart 使用 Grafana 让 ElasticSearch 中的数据飞起来
有任何问题可以加我微信 gavinage ,解决不了大问题,小问题还是可以帮助您的。
感谢您的观看,如果觉着对您有帮助 请给个?
本文首发于 GitChat,未经授权不得转载,转载需与 GitChat 联系。
阅读全文: http://gitbook.cn/gitchat/activity/5d556d8598d8865ab80cab16
您还可以下载 CSDN 旗下精品原创内容社区 GitChat App ,阅读更多 GitChat 专享技术内容哦。
