报头压缩-ROHC报文/校验/编码
序言
这篇文章将会介绍ROHC单向模式U-Mode的报文类型,CRC校验和LSB、W-LSB、RTP TS以及IP-ID等编码算法。
1. ROHC的报文分组和报文格式
ROHC的报文类型包括:反馈包 + IR&IR-DYN包 + 类型0/1/2包
1.1 反馈包(Feedback)
由于U-Mode模式不支持反馈类型,所以在这里不打算详细介绍反馈包。
ROHC支持的反馈类型包括:
- ACK:确认一个报文的成功解压;
- NACK:当不能正确解压几个连续的报文时产生,表示解压器的动态上下文(context)不同步;
- STATIC-NACK:表示解压器的静态上下文无效或没有建立;
反馈可以通过以下方式发送:
- (1) 下层特定的机制;
- (2) 一个特定的只用于传输反馈的信道,下层会提供一种方式指示该包为反馈包,反馈的时间也会提供信息说明是哪个压缩包引起的反馈;
- (3) 压缩包在同一个信道中传输,且与压缩包独立传输,下层不需要指示该包为反馈包;
- (4) 反馈作为压缩包的一部分传输,这种方法可以减少每个反馈的开销;
- (5) (3)和(4)同时使用。
(3)、(4)、(5)需要使用特定格式的反馈格式,以字节对齐。
ROHC RTP有三种报文类型用来标识压缩的报头(IR + FO + SO),两种报文类型用来初始化或刷新(IR + IR-DYN)。压缩报文的格式取决于模式(U-Mode + O-Mode + R-Mode)。因此,用[模式格式]+[报文类型]+[特性]的形式来唯一地标识报文格式。
| 压缩状态 | 使用的报头类型 |
|---|---|
| IR | IR(48-131字节) |
| FO | IR-DYN(48-131字节),UOR-2(3-18字节) |
| SO | R-0(1字节),R-1(2字节),UO-0(1字节),UO-1(2字节),R-0-CRC(2字节) |
1.2 初始化和刷新IR数据包
可压缩的报头分为一个STATIC部分和一个DYNAMIC部分。这些部分分别建立在IR和IR-DYN报文的静态域和动态域中。IR报文将一个CID与一个profile相联系,初始化上下文,刷新上下文。与IR报头相比,IR-DYN报头不初始化一个未经过初始化的上下文,但它能重新定义哪个profile与一个上下文相关。
IR报文的基本结构
这个报文通信上下文的静态部分,即常数的SN函数的值。它也能可选地通信上下文的动态部分,即非常数的SN函数的参数和原始报文的净荷。

- D:用来决定是否存在动态域。D=1存在,D=0不存在;
- Profile:配置文件标识,与CID相关联的配置。常见取值:0x0000表示发送未压缩的IP包,0x0001
表示发送压缩的RTP/UDP/IP包,0x0002表示发送压缩的UDP/IP包,0x0003表示发送压缩的ESP/IP包。 - CRC:8bits的CRC校验部分呢,覆盖范围是依赖于profile的,但是它必须至少覆盖到profile域结尾的报文初始部分。
- 静态信息:一系列静态的子报头信息;
- 动态信息:一系列动态的子报头信息;
- 有效载荷:原始报文的净荷,报文长度指出是否存在净荷。
1.3 初始化和刷新动态IR-DYN数据包
这个报文更新上下文的动态部分,即非常数的SN函数的参数。IR-DYN报文格式与IR报文类似,不同之处在于:报文类型字节不同并且只有动态域,没有静态域。
IR-DYN报文的基本结构

IR-DYN报文的CRC只检测报头本身长度的一致性,这个报头的确认并不表示上下文中先前静态域的修改已经得到确认了,特别是在更新一个已存在的上下文的IR报文之后跟随了一个IR-DYN报文时。
1.4 类型0报文
- 说明:类型0报文有三种:UO-0、R-0、R-0-CRC,类型0报文只传输编码后的SN值,可以通过SN得出其它的域。
- 应用场合:解压方知道所有SN函数的参数时,使用这个最小的报文类型,依赖于这些函数来压缩报头。这样,只需要传输经过W-LSB编码的RTP SN。
- R-Mode:
- R-0:不更新上下文,只用于向解压端提供SN信息。
- R-0-CRC:会更新上下文中的SN信息,有7比特的CRC域,报头可用作随后解压的参考。
- U-Mode和O-Mode:
- UO-0:会更新上下文中SN的当前值,有3比特的CRC域。
- R-Mode:
1.5 类型1报文
- 说明:类型1报文有六种:R-1、R-1-TS、R-1-ID、UO-1、UO-1-ID、UO-1-TS。当需要传输TS或者IP-ID信息时,类型0的报文不能发送,将会选用类型1的报文。
- 应用场合:当SN需要的比特数超过报文类型0中的SN比特数,或当关于RTP TS或IP-ID的SN函数的参数改变时,使用这个报文类型。各模式也说明了不同类型包的使用场合。R-1*包不更新上下文中的信息,UO-1*包会对上下文进行更新。
- R-Mode:
- R-1:当上下文中RND(Random,指示IP-ID是否随机变化) = 1时使用这种类型,这用以区分R-1-TS和R-1-ID。
- R-1-TS、R-1-ID:当上下文中存在IPv4包或者上下文中RND = 0时使用这种类型,R-1-TS用于传输SN和TS信息,R-1-ID用于传输IP-ID信息。
- U-Mode和O-Mode
- UO-1:当上下文中RND = 1时使用这种类型,这用以区分UO-1-TS和UO-1-ID。会更新上下文中的SN和TS信息,含有3比特的CRC域。
- UO-1-TS、UO-1-ID:当上下文中存在IPv4包或者上下文中RND = 0时使用这种类型,用以传输SN、TS或IP-ID信息。UO-1-TS会更新上下文中的SN和TS信息,UO-1-ID会更新上下文中的SN和IP-ID信息。这两种类型都包含3比特的CRC域。
- R-Mode:
1.6 类型2报文
- 说明:类型2包有三种:UOR-2、UOR-2-ID、UOR-2-TS。类型2包一般会在FO状态发送,用于更新动态信息。
应用场合:这个报文类型可用来改变任何SN函数的参数,除了那些大多数是静态域的参数。报文类型2的报文报头可用作随后解压的参考。如果没有明确说明,UOR-2*报文中的所有值都更新上下文。
- U-Mode:
- UOR-2:当上下文中RND = 1时使用这种类型,这用以区分UOR-2-TS和UOR-2-ID。用于更新上下文中SN和TS信息,含有7比特的CRC域。
- UOR-2-TS、UOR-2-ID:当上下文中存在IPv4包或者上下文中RND = 0时使用这种类型,用于更新上下文中SN、TS或IP-ID信息,这两种类型都包含7比特的CRC域。UOR-2-TS用于传输TS和SN信息,UOR-2-ID用于传输IP-ID和SN信息。
- U-Mode:
R-1*包、UOR-2*包和UO-1-ID包可以携带扩展头,扩展头一共有四种类型,可以使得这些包存放更多比特的SN、TS、IP-ID等。
2. CRC校验
在压缩分组报头中加入效验和 以防止差错扩散是ROHC的特色之一CRC效验的原理如下图所示。压缩方对原分组报头进行CRC校验,并将结果填入压缩分组的CRC域中,发送给解压方。解压方收到压缩分组后查找其相应的context表项,并根据其profile进行解压缩,对解压后的报头进行CRC校验,将校验的结果与压缩分组传来的CRC域作比较。若相同,则表明解压无误,可传给上层;若不同,则表明解压错误,应根据具体情况进行不同的处理。

- CRC校验的基本思想:CRC校验的基本思想是利用线性编码理论,在发送端根据要传送的k位二进制码序列,以一定的规则产生一个校验用的监督码(即CRC码)r位,并附在信息后边,构成一个新的二进制码序列数共(k+r)位,最后发送出去。在接收端,则根据信息码和CRC码之间所遵循的规则进行检验,以确定传送中是否出错。
- 解压方计算CRC:解压端在计算CRC时,并不是每次都会将所有的域都计算,而是分为CRC-STATIC域和CRC-DYNAMIC域两个部分,CRC-STATIC域计算后会被保存起来。通常CRC-STATIC域不变,因此每次只需计算CRC-DYNAMIC域,这样可以很好地减少计算复杂度。
- 校验位数:在最理想的情况下,不同的RTP/UDP/IP数据包应该具有不同的CRC校验值,这样才能准确判定解压缩的RTP/UDP/IP数据包是否正确。由CRC校验的原理可知,CRC校验的位数越大,则可靠性越高;当CRC校验位数不足的时候,常常会出现错误校验的情况,即不同的RTP/UDP/IP数据包得到的CRC校验值是一样的,这样就会影响正确的解压缩。出于提高压缩效率的目的,ROHC也不可能将CRC位数定得太大。
- ROHC三种CRC多项式:
- 8比特CRC多项式
C(x)=1+x+x2+x8 - 7比特多项式
C(x)=1+x+x2+x3+x6+x7 - 3比特多项式
C(x)=1+x+x3
- 8比特CRC多项式
3. ROHC的编码算法
在一个预定义的RTP/UDP/IP包流中,后一个分组与前一个分组的报头部分进行对比,大多数情况下发生变化的字段只有三个:IP头中的IP-ID,RTP头中的SN和TS字段。IP-ID和SN每发送一个数据包,它们的值加1,TS字段值的增长幅度则取决与具体的信息编码格式和采样频率。针对这几个字段,ROHC中采取了不同的编码方法对其进行编码,这些编码方式在很大程度上减少了传输这些字段所需使用的比特位数。ROHC能把40字节的RTP/UDP/IP头压缩到1-3个字节来发送,在很大程度上依赖于它所采用的编码方式。
3.1 LSB编码(Least Significant Bits Encoding)
- 最低有效位:LSBs指最低的几个有效位,相对应的是最高有效位MSB。ROHC协议中,当信息头的域值 每次变化范围比较小的时候,可以使用LSB编码方法。

- LSB编码:LSB编码用于变化小的域,压缩端仅发送原始值中的k(k>0)个比特,解压端在接收到这k个比特后,根据前一个成功解压的值v_ref还原出原始值。
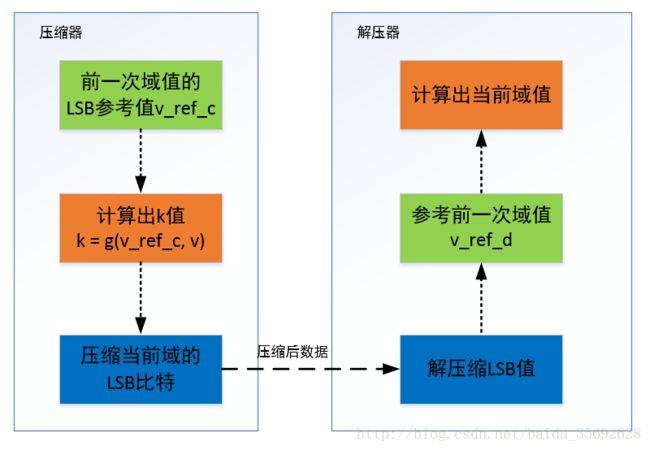
几个重要概念:
解析区间:在LSB编码方法中,压缩端和解压端都需要使用一个解析区间,原始值位于该解析区间内,并且在该解析区间中,只有原始值的k个比特与传输的k个比特相同,解压方从解析区间中解析区间内的该值作为解压值。解析区间可用函数f(v_ref,k)表示
f(vref,k)=[vref−p,vref+(2k−1)−p]

- v_ref:域的参考值
- k:最低有效比特数
- p:偏移量,其选取参考如下表
参考值:压缩端(解压端)使用上一个被压缩(解压)的值v_ref_c(v_ref_d)作为v_ref,当压缩值为v时,压缩端会寻找v的最少k个比特,使得v落在式f(v_ref,k)所表示的区间内。该过程可以用下式表示:
k=g(vrefc,v)参考值CRC校验:当下层没有检测出错误而把错误的包传递至上层时,错误接收的LSB会产生一个错误的解压值,并作为下一次解压的参考值v_ref_d,造成连续的解压失败。为避免解压失败连续发生,可以使用安全的参考值,即对发送的参考值进行CRC校验。
因此,压缩端将本次压缩的值作为下次压缩的v_ref_c,并将该值的CRC值与k个比特一起发送,解压端在还原出原始值后进行CRC校验,通过才会将该值作为下一次的v_ref_d。如果使用最后一个验证的SN的解压失败了,使用最后第二个验证的SN参考进行解压尝试,这个过程减轻了破坏传播。
| 域值变化趋势 | p | 解析区间 |
|---|---|---|
| 总是增加 | -1 | [v_ref + 1, v_ref + 2^k] |
| 保持不变或增加 | 0 | [v_ref, v_ref + 2^k - 1] |
| 稍微偏离常数 | 2^(k-1) - 1 | [v_ref - 2^(k-1) + 1, v_ref + 2^(k-1)] |
| 有小的负变化或大的正变化 | 2^(k-2) - 1 | [v_ref - 2^(k-2) + 1, v_ref + 3*2^(k-2)] |
参数选取举例,对于视频的RTP TS,p可设为2^(k-2) - 1,译码间隔/解析区间为[v_ref - 2^(k-2) + 1, v_ref + 3*2^(k-2)],即间隔的3/4用于正变化。
当压缩端和解压端之间出现丢包时,两者之间可能会失去参考值v_ref的同步,进而失去解析区间的同步,最后导致解压失败,这种情况可以通过W-LSB(Window-based LSB,基于窗口的最低有效位)编码方法解决。
3.2 W-LSB编码(Window-based LSB Encoding)
- 算法由来:在进行压缩包的传输过程中,可能会发生压缩包损坏或者丢失等情况。解压缩端无法进行最新参考值的保存工作,只能将最后一次成功解压缩时的域值作为参照值v_ref_d。压缩端和解压缩端的参考值可能出现不一致的情况,也就会导致解压缩失败。为了提高数据压缩的鲁棒性,ROHC协议引入了窗的概念,对LSB算法进行了升级。
- 压缩端维护一个可滑动的窗口,存放v_ref_d的候选值,压缩方在发送一个由CRC保护的值v(压缩或未压缩)后,将该值添加到滑动窗口中;在进行编码的时候,会按照下式来决定k值:
k=max(g(vmin,v),g(vmax,v))
其中v_min和v_max分别为滑动窗口中的最小值和最大值。当压缩端充分确定值v和先于v进入滑动窗口的值将不会被解压端使用时,窗口会向前移,移除v和先于v进入滑动窗口的值。 - W-LSB编码是一种支持TCP协议的ROHC编码方案,它利用差值来进行编码。由于使用了WLSB算法,滑动窗中所有的值都可以作为参考值。可以保证当发生压缩包丢失的时候,解压缩端同样可以进行正确的解压缩处理。
- W-LSB压缩实例
当SN域为279,280,281,282,283的压缩包已经成功发送,数值279到282作为参考值保存到滑动窗中。之后,发送p = -1(总是增加),SN = 284的压缩包。不发生丢包和发生丢包K值的取值如下表所示
| 域值 | 参考值 | 解析区间 | k值 |
|---|---|---|---|
| 284 | 283 | k = 1, 最大解析区间[284,285] | 1 |
| 284 | 279 | k = 3, 最小解析区间[280,287] | 3 |
注:解析区间长度2^k
- 采用LSB算法的时候:K=1,284(十进制) = 100011100(二进制),最后1比特即为LSB。解压缩端,参考值为283的包丢失,使用旧的参考值279(100010111),计算之后得出的解析区间[280,281],解析区间内,LSB 1比特为0的域值为280,解压缩处理失败。
- 采用W-LSB算法的时候:K=3,284(十进制) = 100011100(二进制),最后3比特即为LSB。解压缩端,参考值为283的包丢失,使用旧的参考值279(100010111),计算之后得出的解释范围/解析区间[280,287],在该解析区间内,LSB 3比特为100的域值是284,解压缩成功。
- ROHC协议对信息头中各个域进行了分析,能使用WLSB算法进行压缩的域如下
| 域 | W-LSB处理对象 | k最大值 | p值 |
|---|---|---|---|
| IP-ID | Offset IP-ID Encoding结果 | 16 | 0 |
| TS | Scaled RTP timestamp encoding结果TS_SCALED | 32 | 2^(k-2)-1 |
| SN | UDP SN | 16 | -1 |
| SN | RTP SN | 16 | 1(k<=4), 2^(k-5)-1(k>4) |
W-LSB压缩端处理流程

W-LSB解压端处理流程

W-LSB滑动窗的大小,是可以调整的参数(主要通过调整k值)。在ROHC实体初期化的时候进行设定,窗越大则ROHC的鲁棒性越高,但是压缩性能就会下降。
- 滑动窗更新处理流程
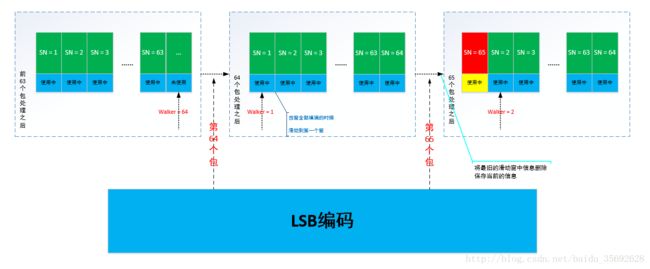
当压缩方确信某个v值和比v旧的所有值再也不会被解压方作为参考值时,压缩方就把这些值(包含v自身)从窗中移除。压缩方的这种确信可以由多种方法获得:在R-Mode(双向可靠模式),可以是来自解压方的ACK值来指示可以将已ACK过的值从滑动窗中移除;在U-Mode(单向模式)和O-Mode(双向优化模式)中,一般由CRC来保证正确解压,还使用了有宽度限制的滑动窗,该窗宽度依赖于具体实现的优化系数。
3.3 RTP TS编码(Scaled RTP TS Encoding)
RTP报头的时间戳字段指示RTP数据包中第一个八进制数的采样时刻,不同媒体流的 RTP 时间戳可能以不同的速率增长,而且会有独立的随机偏移量。
RTP报头中的时戳(TS)字段在相邻数据包之间通常不会随意的变化,TS代表了RTP包载荷部分第一个字节的采样时间,它通常是某个常数(TS_STRIDE)的整数倍再加上一定的偏移。
- 音频编码中,在采样率是8kHz,采样时长20ms,一个语音帧包含在一个RTP包中的情况下,TS的增幅通常是n×160(160 = 8000×0.02),n是正整数。
- 视频编码中,同样存在这样的一个TS_STRIDE,对于大部分的视频编码器来说,采样率是90kHz,如果视频帧的放映速率固定,比如30帧/秒,那么TS的增幅固定为n×3000 (3000 = 90000/30)。一个视频帧通常被分割成多个RTP包来承载,在这种情况下,这几个连续的RTP包中TS字段的值保持不变。
可用下面的公式来表示TS:
- 说明
- TS_STRIDE是明确的常数,反映RTP时间戳的增长速率,如音频编码中的160,视频编码中的3000
- TS_OFFSET是随机偏移量,当TS不回绕时(不超过TS字段所能表示的最大范围),对于不同的TS,TS_OFFSET的值是相同的。其计算方式如下(取模),如果发生回绕,压缩方不需要再初始化回绕的TS_OFFSET,相反,解压方必须检测未按比例的TS的回绕并更新TS_OFFSET,公式仍如下,不过用的是回绕后的TS值。
TSOFFSET=TS%TSSTRIDE - TS_SCALED是压缩比例值,初始化之后,压缩方不再压缩原始的TS值,而是压缩按比例缩减的TS_SCALED值(整除)。
TSSCALED=TS/TSSTRIDE
ROHC中该算法的各阶段:
- 初始化阶段:压缩器把TS_STRIDE和一个或少数几个TS的值发送给解压器,解压器可以根据这些值计算出TS_OFFSET。解压器把TS_OFFSET和TS_STRIDE保存在上下文context中。
- 压缩阶段:对于特定TS(如视频帧TS值连续不变的情况),压缩器不再发送完整的TS字段,而是采用W-LSB或者其他编码方式对其相应的TS_SCALED值进行压缩编码(见上面的解释),把编码后的值发送给解压器。
- 解压缩阶段:当受到TS_SCALED的压缩值,解压器首先根据W-LSB或其他相应的解码方法还原TS_SCALED的原始值,然后采取TS值计算公式计算出具体的TS值。
- TS字段越界:TS字段是32位的无符号整数,因此,当TS不断增大,超过32位无符号整数的表示范围时,TS将重新从0开始轮转。这种情况下TS_OFFSET的值会发生变化,解压器必须检测TS的回绕,压缩器需要发送新的TS_OFFSET给解压器直到完成新的TS_OFFSET和TS_STRIDE的重新初始化。
- TS字段越界:TS字段是32位的无符号整数,因此,当TS不断增大,超过32位无符号整数的表示范围时,TS将重新从0开始轮转。这种情况下TS_OFFSET的值会发生变化,解压器必须检测TS的回绕,压缩器需要发送新的TS_OFFSET给解压器直到完成新的TS_OFFSET和TS_STRIDE的重新初始化。
3.4 IP-ID Offset编码(Offset IP-lD Encoding)
- 应用场景:IP-ID用于识别IPv4包,一般每一个包都有不同的IP-ID,若两个或两个以上的包有相同的IP-ID,说明这些包是进行分片得到的。ROHC提供IPv4的IP-ID的透明压缩,RFC3095里暂不考虑对IPv6的分片报头。
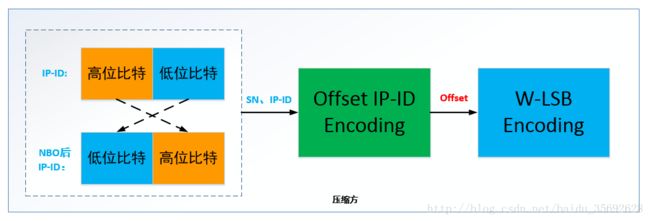
算法思想:当一个IP流的包与包之间的IP-ID值以1增长时,可以采用此处讨论的IP-ID偏移编码方法。一个IP流中包与包之间的RTP序列号SN也是以1增长,即IP-ID和SN至少以同样的数量增长。因此,只需对偏移offset,即IP-ID与SN间的差Offset,进行压缩而不是IP-ID本身。
Offseti=IDi−SNi- 其中Offset_i为第i个信息头的offset值,ID_i为第i个信息头的IP-ID值,SN_i为第i个信息头的RTP SN值。
- 使用W-LSB编码发送,解压端接收到后,根据offset_ref还原出偏移值,得出IP-ID_i。
IP-ID域的变化规律:
- Sequence
- NBO - Net Byte Order
- Random
| 规律 | 说明 | 编码方法 | RND Flag(类型1/2报文) | NBO Flag |
|---|---|---|---|---|
| Sequence | 连续增加 | Offset IP-ID | 0 | 1(No Swap) |
| NBO | 连续增加(Byte Order Swap) | Offset IP-ID | 0 | 0(Swap) |
| Random | 随机生成 | 不压缩 | 1 | 无意义 |
说明
- 当RND Flag = 0的时候,使用IP-ID OFFSET算法进行压缩处理。
- 当信息头存在2个IP头的时候,外层IP头和内层IP头都可以使用IP-ID OFFSET算法进行压缩。外层IP头对应的Flag为RND2,NB02。
- 压缩端对当前信息头的IP-ID进行解析,判断属于何种情况。如果是Sequence或者NBO则使用IP-ID OFFSET算法进行压缩处理;如果是Random,则将2字节的IP-ID全部压缩发送到解压端。
- 即:出于安全考虑,有时在产生IPv4流时,会使用随机的IP-ID,这时候不能用这里讨论d的IP-ID偏移编码方法,而是需要将IP-ID全部发送,压缩端必须检测出随机的IP-ID,并将上下文中的RND标志置1,解压端通过RND判断是否为随机的IP-ID。
IP-ID压缩解压过程
压缩端
Sequence时的处理流程

NBO时的处理流程(Encoding前先将高低位字节交换)
解压端
解压缩端Offset IP-ID Decoding算法是Encoding算法的逆运算,计算式:
IPID=SN+OffsetIP-ID解压处理流程

说明:
- (1) 参考报头是最后一个正确解压的报头(由CRC验证),当接收到一个压缩的报文m,解压器计算Offset_ref = ID_ref - SN_ref,ID_ref和SN_ref分别是参考报头中的IP-ID和RTP SN值;
- (2) 使用在报文m中接收到的Offset_m的LSB + Offset_ref用W-LSB解码方法来解压Offset_m。报文m可能包含Offset_m的0个LSB,此时,Offset_m= Offset_ref;
- (3) 最后再生报文m的IP-ID:IP-ID_m = SN_m + Offset_m
3.5 自描述的变长值编码
- 由来:在Scaled RTP TS Encoding中提到需要在初始化阶段发送TS_STRIDE的值,TS_STRIDE的值、TS的值、包类型格式中提到的large CID值等可能会变化很大。比如TS_STRIDE对语音可以是160,对1frame/s的视频可以是90000。如果不加区分的都用四个字节来传输,将造成浪费。可以使用下面的可变长度的编码方法对这些字段进行编码:
| 范围(十六进制) | 最大十进制值 | 发送的比特数 | 使用的字节数 | 首部比特标识 |
|---|---|---|---|---|
| 00-7F | 127 | 7 | 1 | 0 |
| 8000-BFFF | 16383 | 14 | 2 | 10 |
| C0 0000-DF FFFF | 2097151 | 21 | 3 | 110 |
| E000 0000-FFFF FFFF | 536870911 | 29 | 4 | 111 |
- 自描述的变长值编码方法中,最后使用的字节数由第一个字节的前几个比特决定/指示。
Acknowledgements:
[1] 孙青. 基于LTE的健壮性头压缩(ROHC)的研究和实现[D]. 东南大学, 2013.
[2] 陈阳. 无线通信 ROHC 协议技术研究与实现[D]. 大连海事大学, 2012.
[3] 周逻理. 基于 Linux 平台的 ROHC 报头压缩系统的研究与实现[D]. 北京邮电大学, 2008.
[4] 刘天钊. 鲁棒性报头压缩算法研究[D]. 西安电子科技大学, 2008.
2017.04.29