使用Pytorch训练LeNet模型
L e N e t LeNet LeNet
视频教程:B站、网易云课堂、腾讯课堂
代码地址:Gitee、Github
存储地址:
Google云
百度云:
https://pan.baidu.com/s/17s_tujme9y23FmwJssrAZQ
提取码:v0u0
- 环境安装
pip install torch===1.2.0 torchvision===0.4.0 -f https://download.pytorch.org/whl/torch_stable.html
- 介绍
1.data:存放训练、测试等数据
2.main: 主要运行文件
3.net:存放Lenet网络
4.saved_models:存放训练保存后的模型
5.tools:一些工具文件
详细:
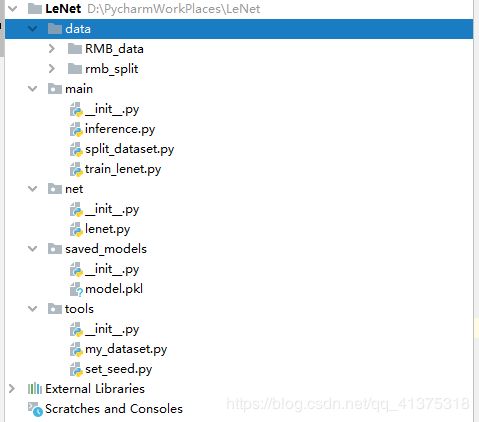
补充:__init__可以暂时忽视,和包的引入有关
程序运行步骤:
1. 运行split_dataset.py , 划分训练集、验证集、测试集(如果直接用我上传的就不用运行这个了,我已经运行划分过了,想体验,只需将data文件夹下的rmb_split文件夹删除)
2. 运行train_lenet.py , 训练和保存模型
3. 运行inference.py , 进行实际测试
1.main
1.1 inference.py
# -*- coding: utf-8 -*-
# ============================ inference ============================
import os
from tools.my_dataset import RMBDataset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch
# 导入模型
path_model="../saved_models/model.pkl"
net_loaded=torch.load(path_model)
# 均值和方差
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
# 数据预处理
test_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std), # 标准化
])
# 测试数据文件夹
split_dir = os.path.join("..", "data", "rmb_split")
test_dir = os.path.join(split_dir, "test")
# 构建MyDataset实例
test_data = RMBDataset(data_dir=test_dir, transform=test_transform)
# 构建DataLoder
test_loader = DataLoader(dataset=test_data, batch_size=1)
for i, data in enumerate(test_loader):
# forward
inputs, labels = data
outputs = net_loaded(inputs)
_, predicted = torch.max(outputs.data, 1)
rmb = 1 if predicted.numpy()[0] == 0 else 100
print("模型获得{}元".format(rmb))
1.2 split_dataset.py
# -*- coding: utf-8 -*-
import os
import random
import shutil
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == '__main__':
random.seed(1)
dataset_dir = os.path.join("..", "data", "RMB_data")
split_dir = os.path.join("..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
test_dir = os.path.join(split_dir, "test")
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
for root, dirs, files in os.walk(dataset_dir):
for sub_dir in dirs:
imgs = os.listdir(os.path.join(root, sub_dir))
imgs = list(filter(lambda x: x.endswith('.jpg'), imgs))
random.shuffle(imgs)
img_count = len(imgs)
train_point = int(img_count * train_pct)
valid_point = int(img_count * (train_pct + valid_pct))
for i in range(img_count):
if i < train_point:
out_dir = os.path.join(train_dir, sub_dir)
elif i < valid_point:
out_dir = os.path.join(valid_dir, sub_dir)
else:
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir)
target_path = os.path.join(out_dir, imgs[i])
src_path = os.path.join(dataset_dir, sub_dir, imgs[i])
shutil.copy(src_path, target_path)
print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,
img_count-valid_point))
1.3 train_lenet.py
# -*- coding: utf-8 -*-
"""
# @file name : train_lenet.py
# @author : major_s
# @date : 2020-07-07 10:08:00
# @brief : 人民币分类模型训练
"""
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from net.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.set_seed import set_seed
set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 200
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss_val/valid_loader.__len__())
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct_val / total_val))
if epoch % 10 == 0: # 每10个epoch保存一次
path_model = "../saved_models/model.pkl"
torch.save(net, path_model)
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
2. net
lenet.py
# -*- coding: utf-8 -*-
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self, classes):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 0.1)
m.bias.data.zero_()
class LeNet2(nn.Module):
def __init__(self, classes):
super(LeNet2, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
3.tools
3.1 my_dataset.py
# -*- coding: utf-8 -*-
import os
import random
from PIL import Image
from torch.utils.data import Dataset
random.seed(1)
rmb_label = {"1": 0, "100": 1}
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
3.2 set_seed.py
import torch
import random
import numpy as np
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
补充:data和savd_models的数据都是运行程序生成在里面
计算pytorch标准化(Normalize)所需要数据集的均值和方差