Spark 和 Python.sklearn:使用随机森林计算 feature_importance 特征重要性
前言
数据:美国某公司的共享单车数据
数据源:http://archive.ics.uci.edu/ml/machine-learning-databases/00275/
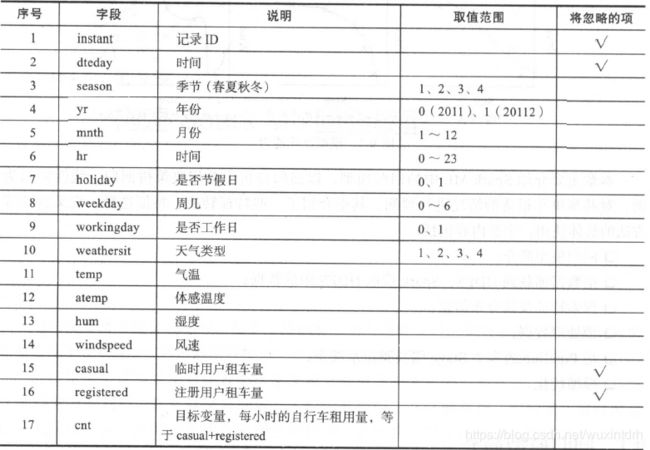 图源: https://blog.csdn.net/wuxintdrh/article/details/90729963
图源: https://blog.csdn.net/wuxintdrh/article/details/90729963
由于相关的预测变量,单个决策树的特征重要性可能具有较高的方差。考虑使用随机森林分类器来确定特征的重要性。

随机森林计算特征重要性的原理
随机森林中进行特征重要性的评估思想:判断每个特征在随机森林中的每颗树上做了多大的贡献,然后取个平均值,最后比一比特征之间的贡献大小。其中关于贡献的计算方式可以是不纯度或袋外数据错误率。
- 基于不纯度
对于每颗树,按照impurity(gini /entropy)给特征排序,然后整个森林取平均。最优条件的选择依据是不纯度,不纯度在分类中通常为gini或entropy,对于回归问题来说是方差mse。
基于不纯度对模型进行排序有几点需要注意:
(1)基于不纯度降低的特征选择将会偏向于选择那些具有较多类别的变量。
(2)当存在相关特征时,一个特征被选择后,与其相关的其他特征的重要度则会变得很低,因为他们可以减少的不纯度已经被前面的特征移除了。
- 基于袋外错误率
计算某个特征X的重要性时,具体步骤如下:
1)对每一颗决策树,选择相应的袋外数据(out of bag,OOB)计算袋外数据误差,记为errOOB1.
所谓袋外数据是指,每次建立决策树时,通过重复抽样得到一个数据用于训练决策树,这时还有大约1/3的数据没有被利用,没有参与决策树的建立。这部分数据可以用于对决策树的性能进行评估,计算模型的预测错误率,称为袋外数据误差。
这已经经过证明是无偏估计的,所以在随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计。
2)随机对袋外数据OOB所有样本的特征X加入噪声干扰(可以随机改变样本在特征X处的值),再次计算袋外数据误差,记为errOOB2。
这里的噪声干扰(指对数据进行打乱的方法)通常有两种:
一是使用uniform或者gaussian抽取随机值替换原特征;
二是通过permutation的方式将原来的所有N个样本的第 i 个特征值重新打乱分布(相当于重新洗牌)。
3)假设森林中有N棵树,则特征X的重要性=∑(errOOB2-errOOB1)/N。这个数值之所以能够说明特征的重要性是因为,如果加入随机噪声后,袋外数据准确率大幅度下降(即errOOB2上升),说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。
超参数
1、n_estimators:它表示建立的树的数量。 一般来说,树的数量越多,性能越好,预测也越稳定,但这也会减慢计算速度。一般来说在实践中选择数百棵树是比较好的选择,因此,一般默认是100。
2、n_jobs:参数表示引擎允许使用处理器的数量。 若值为1,则只能使用一个处理器。 值为-1则表示没有限制。设置n_jobs可以加快模型计算速度。
3、oob_score :它是一种随机森林交叉验证方法,即是否采用袋外样本来评估模型的好坏。默认是False。推荐设置为True,因为袋外分数反应了一个模型拟合后的泛化能力。
#特征重要性
importances = model.feature_importances_
# out of bag score
oobs = model.oob_score_
pySpark代码
from pyspark.sql import SparkSession
from pyspark.ml.regression import LinearRegression
from pyspark.ml.feature import OneHotEncoder
from pyspark.ml.feature import VectorAssembler,StandardScaler
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml import Pipeline
spark = SparkSession.builder.master('local').appName('LinearRegression').getOrCreate()
data = spark.read.format('csv').option("header",True).load(u"D:\Data\day.csv")
# ''' 特征选择并转换类型 '''
data1 = data.select(
data["season"].cast("Double"), # 季节 (类别字段)
data["yr"].cast("Double"), # 年份 (类别字段)
data["mnth"].cast("Double"), # 月份 (类别字段)
data["holiday"].cast("Double"), # 是否为假期 (类别字段)
data["weekday"].cast("Double"), # 是否为周末 (类别字段)
data["workingday"].cast("Double"), # 是否为工作日 (类别字段)
data["weathersit"].cast("Double"), # 天气 (类别字段)
data["temp"].cast("Double"), # 气温 (数值字段)
data["atemp"].cast("Double"), # 体感温度 (数值字段)
data["hum"].cast("Double"), # 湿度 (数值字段)
data["windspeed"].cast("Double"), # 风速 (数值字段)
data["cnt"].cast("Double").alias("label")) # 单车租用量 (数值字段)
#data1.show(10)
''' 特征重要性 '''
from pyspark.ml.regression import RandomForestRegressor
featureArray = ["season", "yr", "mnth", "holiday", "weekday", "workingday", "weathersit", "temp", "hum", "windspeed","atemp"]
assembler_lr = VectorAssembler().setInputCols(featureArray).setOutputCol("features")
pipeline_lr = Pipeline().setStages([assembler_lr])
data_M = pipeline_lr.fit(data1).transform(data1)
scaler = StandardScaler().setInputCol("features").setOutputCol("scaledFeatures").setWithStd(True).setWithMean(False)
data_M = scaler.fit(data_M).transform(data_M)
RF = RandomForestRegressor().setLabelCol("label").setFeaturesCol("scaledFeatures").setMaxBins(64).setMaxDepth(16)
model = RF.fit(data_M)
print(model.featureImportances)
Python.sklearn代码
class sklearn.ensemble.RandomForestRegressor(n_estimators=10, criterion=’mse’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=1, random_state=None,verbose=0, warm_start=False)
原理:基于mse
from sklearn import ensemble
import pandas as pd
data = pd.read_csv(u"D:\Data\day.csv")
featureArray = ["season", "yr", "mnth", "holiday", "weekday", "workingday", "weathersit", "temp", "hum", "windspeed","atemp"]
x = data[featureArray]
y = data["cnt"]
rf = ensemble.RandomForestRegressor(n_estimators=35)
rf.fit(x,y)
print("特征重要性:"+str(rf.feature_importances_))原理:基于袋外错误率
class sklearn.model_selection.ShuffleSplit(n_splits=10, test_size=’default’, train_size=None, random_state=None)
from sklearn.model_selection import ShuffleSplit
from sklearn.metrics import mean_absolute_error
from collections import defaultdict
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
import numpy as np
boston = load_boston()
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
rf = RandomForestRegressor()
scores = defaultdict(list)
rs = ShuffleSplit(n_splits=100, test_size=0.3,random_state=0)
for train_idx, test_idx in rs.split(X):
X_train, X_test = X[train_idx], X[test_idx]
Y_train, Y_test = Y[train_idx], Y[test_idx]
r = rf.fit(X_train, Y_train)
acc = mean_absolute_error(Y_test, rf.predict(X_test)).round(3)
for i in range(X.shape[1]):
X_t = X_test.copy()
np.random.shuffle(X_t[:, i])
shuff_acc = mean_absolute_error(Y_test, rf.predict(X_t)).round(3)
scores[names[i]].append(abs(acc-shuff_acc))
print("Features sorted by their score:")
print(sorted([(round(np.mean(score), 4), feat) for
feat, score in scores.items()], reverse=True))
结果
| season |
yr | mnth |
holiday |
weekday |
workingday |
weathersit |
temp |
hum |
windspeed |
atemp |
|
| pySpark | 0.104771 | 0.263050 | 0.043331 | 0.002871 | 0.016073 | 0.006742 | 0.027944 | 0.246312 | 0.069891 | 0.038229 | 0.1807837 |
| sklearn | 0.062571 | 0.287863 | 0.029111 | 0.003221 | 0.014817 | 0.003823 | 0.020559 | 0.369785 | 0.068229 | 0.031225 | 0.108790 |
绘图
import matplotlib as mpl
import matplotlib.pyplot as plt
FI = pd.Series(model.featureImportances, index = featureArray) # pySpark
# FI = pd.Series(rf.feature_importances_,index = featureArray) # sklearn
FI = FI.sort_values(ascending = False)
fig = plt.figure(figsize=(12,5))
plt.bar(FI.index,FI.values,color="blue")
plt.xlabel('features')
plt.ylabel('importances')
plt.show()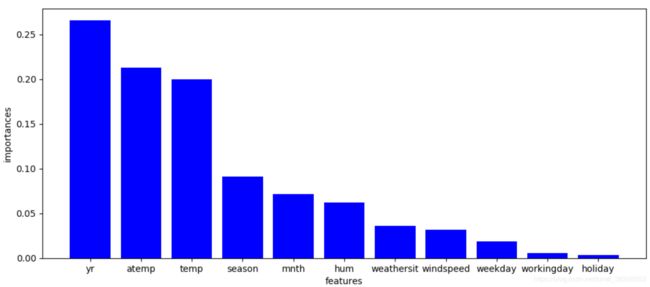 pySpark结果(图表无关,由于数据随机性,每次结果会有不同)
pySpark结果(图表无关,由于数据随机性,每次结果会有不同)
 sklearn结果(图表无关,由于数据随机性,每次结果会有不同)
sklearn结果(图表无关,由于数据随机性,每次结果会有不同)
说明
随机森林进行特征选择和特征重要性排序的时候结果不一样,因为bagging抽取子集的时候,可能具有一定的随机性。
参考
随机森林如何评估特征重要性
随机森林对特征重要性排序(有代码示例)
Scikit-learn的K-fold交叉验证类ShuffleSplit、GroupShuffleSplit用法介绍
python实现随机森林random forest的原理及方法
随机森林算法OOB_SCORE最佳特征选择
Random Forest算法参数解释及调优
回归预测的评价指标
实战:用Python实现随机森林
随机之美——机器学习中的随机森林模型
python实现RF.feature_importances的条形图
Python随机森林算法入门和性能评估