NG机器学习总结-(二)损失函数和梯度下降算法
在学习具体的机器学习算法之前,有几个知识需要弄清楚,算法的模型表示、什么是损失函数以及梯度下降算法,了解这些会帮助我们更好的理解和学习具体的机器学习算法。我们学习第一个算法是线下回归,接下来会通过线性回归来具体介绍什么样的模型更重要以及监督学习的过程,顺便复习前一章的内容。
一、模型表示
首先我们举一个例子,利用前一章中的预测房价(这是一个监督学习任务并且是一个回归问题)。现在我们拥有某一个城市的住房价格数据。基于这些数据,绘制如下的图形,在已有的房价数据中,部分房子已经售出并且知道这些房子的大小和价格,现在你有一个房子其大小是1250平方英尺,那么如何基于房价数据来预测其可能的售价?
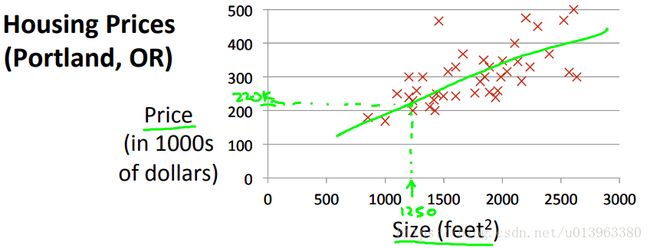
如果用一条直线去拟合数据,那么你的房子可能的售价是$220,000。为了更好的描述模型,我们根据其数据集的格式定义一些符号。

 表示训练集中实例的数量
表示训练集中实例的数量 表示输入变量(或者说是特征),这里是房间的大小
表示输入变量(或者说是特征),这里是房间的大小 表示输出变量(或者说目标值),这里是房价
表示输出变量(或者说目标值),这里是房价 表示一条训练样例,
表示一条训练样例,
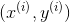 表示第i个样本例,如(2104, 460)是第一条记录
表示第i个样本例,如(2104, 460)是第一条记录
监督学习的过程如下图:
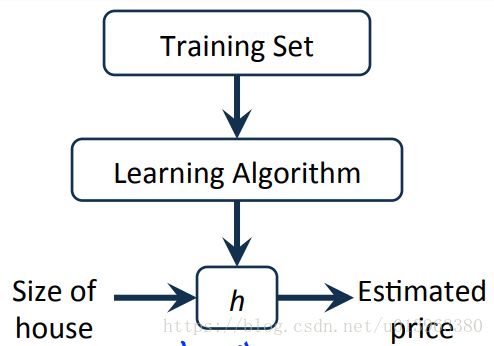
我们将训练的数据集丢给(feed)学习算法,学习算法输出一个函数h(这里的h其实就是hypothesis假设),h的任务就是给定一个输入x,然手输出房子的估价y。所以,h是一个从x映射到y的函数,有的人会问为什么函数h会被成为假设,ng表示说这只是机器学习的标准术语,不必要纠结。但是我们如何来表示函数h呢?根据房价预测问题,我们可以用一种直线去拟合数据(如第一张图),因此在这里,h函数的一种可能方式就是:![]()

所以这里的函数h其实就是我们的模型表达方式,![]() ,这里只含有一个输入变量(特征),因此这样的问题也叫做单变量线性回归问题。
,这里只含有一个输入变量(特征),因此这样的问题也叫做单变量线性回归问题。
二、损失函数
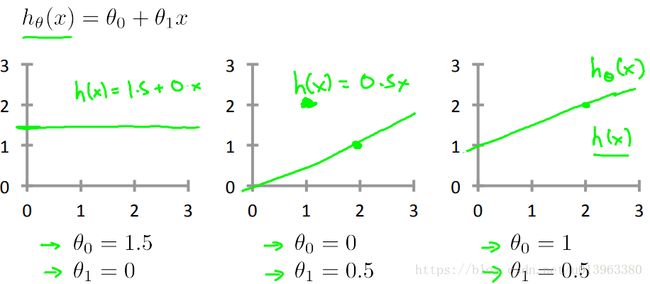
在上一节中,用来预测房价的函数是![]() ,
,![]() 是模型参数,那么如何选择模型参数呢?例如,我们可以选择
是模型参数,那么如何选择模型参数呢?例如,我们可以选择![]() ,我们也可以选择
,我们也可以选择![]() ,我们还可以选择
,我们还可以选择![]() ,对应的h函数如下:
,对应的h函数如下:
在线性回归中,我们有一个训练数据集,然后我们可以用一条直线去拟合这些数据集(如上图表示),因此我们要做的就是通过训练集数据来学习出模型参数![]() 。那么我们如何得出模型参数
。那么我们如何得出模型参数![]() 的值使得函数h更好的拟合数据集呢?所以这里我们的思想是:选择适合的模型参数
的值使得函数h更好的拟合数据集呢?所以这里我们的思想是:选择适合的模型参数![]() 使得
使得 接近或等于训练样例中的真实值y。
接近或等于训练样例中的真实值y。
这样线性回归问题就转化成了,如何解决一个最小化问题。我们选择的模型参数![]() 决定了我们的直线(模型)相对于数据集的准确程度,模型所预测的值与真实值之间的差距。例如,当我们选择模型参数
决定了我们的直线(模型)相对于数据集的准确程度,模型所预测的值与真实值之间的差距。例如,当我们选择模型参数![]() 的时候,真实值和模型预测值之间的差距如下图所示:
的时候,真实值和模型预测值之间的差距如下图所示:
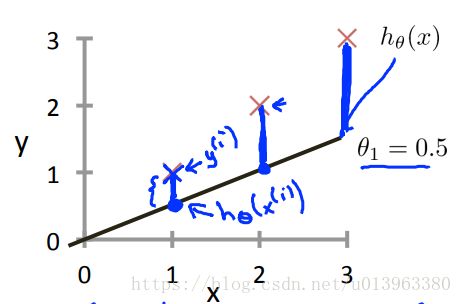
上图中,黑色直线是我们选择模型参数![]() 的时候模型拟合的直线,淡红色的叉表示真实值,蓝色的部分表示是预测值与真实值之间的差距。我们的目标就是选择出使得模型的误差最小的模型参数,一般我们使用误差的平方和来表示,所以其计算公式如下:
的时候模型拟合的直线,淡红色的叉表示真实值,蓝色的部分表示是预测值与真实值之间的差距。我们的目标就是选择出使得模型的误差最小的模型参数,一般我们使用误差的平方和来表示,所以其计算公式如下:
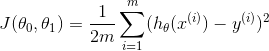
(tips:这里的符号已经在上面定义了)这里的 也就是损失函数(代价函数)。简单点来理解,损失函数就是给定的模型参数其模型预测的值与真实值出现误差的代价。这个时候如果我们根据刚刚提到的房价数据来绘制一个等高线图,三个坐标分别是参数
也就是损失函数(代价函数)。简单点来理解,损失函数就是给定的模型参数其模型预测的值与真实值出现误差的代价。这个时候如果我们根据刚刚提到的房价数据来绘制一个等高线图,三个坐标分别是参数![]() 和损失函数,如下图:
和损失函数,如下图:

如果我们把这个等高线图只投影到坐标![]() 上去,可以得出下面的图:
上去,可以得出下面的图:
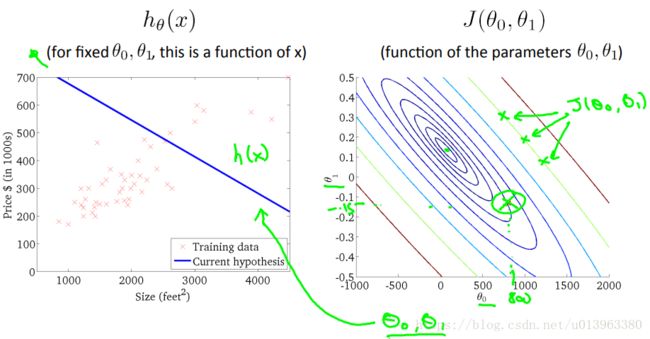
根据上面的几张图,我们可以看出,存在一个可以使得损失函数最小的参数点![]() 。
。
三、梯度下降算法
上一节中我们定义了损失函数,而我们的目标就是最小化损失函数。梯度下降算法可以用来求解损失函数最小化,在机器学习中它是一个很常用算法,不仅可以用于线性回归,还可以用于机器学习其他算法。方便理解,这里我们依旧用上面提到的单变量线性回归问题来介绍梯度下降算法(可以用于多变量的线性回归问题)。

现在我们有损失函数,我们想要最小化该目标函数。而梯度下降算法的一般步骤是:首先初始化模型参数![]() ,我们可以将它们全部设置为0(也可以初始化为其他的数值),然后在接下来的步骤中要做的就是一点点的改变参数
,我们可以将它们全部设置为0(也可以初始化为其他的数值),然后在接下来的步骤中要做的就是一点点的改变参数![]() 的数值,试图让损失函数变小,直到我们找到损失函数的最小值。下面我们通过一些三维图来观测梯度下降算法的过程。
的数值,试图让损失函数变小,直到我们找到损失函数的最小值。下面我们通过一些三维图来观测梯度下降算法的过程。
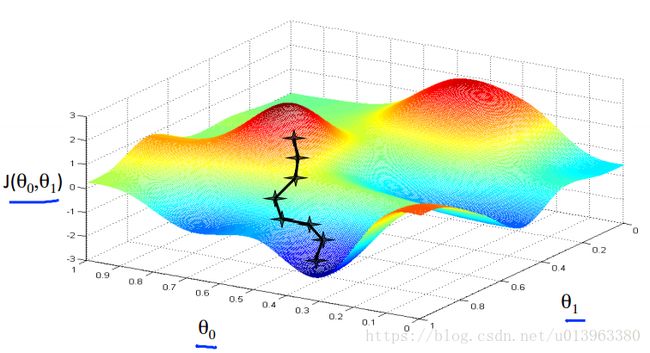

上图中,图形的表面高度是损失函数的值,当然我们希望使得损失函数的值最小,这个时候我们从某一个参数![]() 点出发(出发点就是刚开始我们初始化参数的数值)。NG在这里将上面的图形想象为一座山,并假设你当前站在出发点的位置,为了尽快的下山,我们应该朝着上面方向怎么走?如果我们站在山坡上的某一点,你看一下周围 ,你会发现最佳的下山方向大约是那个方向。好的,现在你在山上的新起点上,你再看看周围,然后再一次想想我应该从什么方向迈着小碎步下山? 然后你按照自己的判断又迈出一步,往那个方向走了一步。然后重复上面的步骤,从这个新的点,你环顾四周并决定从什么方向将会最快下山,然后又迈进了一小步,又是一小步…并依此类推,直到你接近局部最低点的位置。(数学中,梯度其实是微积分的一个概念,在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率;在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的下降(上升)最快的方向,不明白的可以看看微积分相关知识)。但是我们发现,如上面两个图,当我们身处不同的起点的时候,通过梯度下降算法会得到不同的解,这是梯度下降算法的一个特点。
点出发(出发点就是刚开始我们初始化参数的数值)。NG在这里将上面的图形想象为一座山,并假设你当前站在出发点的位置,为了尽快的下山,我们应该朝着上面方向怎么走?如果我们站在山坡上的某一点,你看一下周围 ,你会发现最佳的下山方向大约是那个方向。好的,现在你在山上的新起点上,你再看看周围,然后再一次想想我应该从什么方向迈着小碎步下山? 然后你按照自己的判断又迈出一步,往那个方向走了一步。然后重复上面的步骤,从这个新的点,你环顾四周并决定从什么方向将会最快下山,然后又迈进了一小步,又是一小步…并依此类推,直到你接近局部最低点的位置。(数学中,梯度其实是微积分的一个概念,在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率;在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的下降(上升)最快的方向,不明白的可以看看微积分相关知识)。但是我们发现,如上面两个图,当我们身处不同的起点的时候,通过梯度下降算法会得到不同的解,这是梯度下降算法的一个特点。
下图我们给出梯度下降算法的求解过程:

这里的 是学习速率,对比NG的想象下山中你下山走的步伐(是小碎步还是大跨步),
是学习速率,对比NG的想象下山中你下山走的步伐(是小碎步还是大跨步),![]() 就是参数的梯度方向,对比NG的想象下山中你在当前位置选择下山的方向。另外,在梯度下降算法中,我们需要同时更新参数
就是参数的梯度方向,对比NG的想象下山中你在当前位置选择下山的方向。另外,在梯度下降算法中,我们需要同时更新参数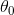 和
和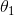 ,而不是交替更新。根据下图解释梯度下降为能够在梯度方向最小化损失函数和学习速率的取值的影响。
,而不是交替更新。根据下图解释梯度下降为能够在梯度方向最小化损失函数和学习速率的取值的影响。

根据损失函数(其实就是一个二次方程),能够画出上图随着参数的变化,损失函数的变化。梯度的方向其实就是曲线的切线方向。而这个时候学习速率过小,达到最小值点需要很多步;而学习速率过大,那么有可能会越过最小值点,甚至会远离最小值点,这样无法收敛。
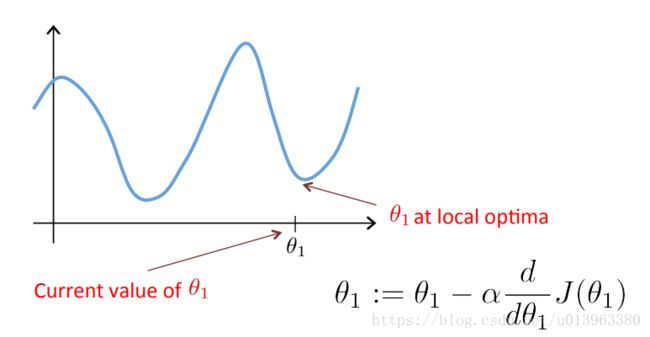
而如果你的参数已经处于局部最低点,那么梯度下降法更新其实什么都没做(求导为0,切线斜率为0),它不会改变参数的值,这也正是你想要的,因为它使你的解始终保持在局部最优点,这也解释了为什么即使学习速率 α 保持不变时,梯度下降也可以收敛到局部最低点。
接下来我们将梯度下降算法用于上文中提到的预测房价的单变量线性回归问题中。其模型表示是![]() ,损失函数是
,损失函数是
单变量线性回归模型:
梯度下降算法:
repeat until convergence {
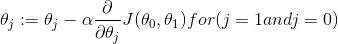
}
根据上式求解:
update


实际上,上面用于线性回归的损失函数是一个弓形的样子,如下图(房价那里也画过这样的图),这个函数的专业术语是凸函数。该函数没有局部最优解,只有一个全局最优解,也就是碗的最底部。
上文中梯度下降算法其实指的是批量梯度下降算法,在梯度下降的每一步中我们都用到了所有的训练样本。在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以在每一个单独的梯度下降中,我们最终都要计算这样一项,这项需要对所有m个训练样本求和。而事实上,也有其他类型的梯度下降法不是这种"批量"型的,不考虑整个的训练集,而是每次只关注训练集中的一些小的子集。如随机梯度下降算法(SGD)以及其他的变种,有兴趣的可以去学习一下。
tips:本文中没有用代码实现单变量线性回归算法和梯度下降算法,这里只是为了深刻理解损失函数和梯度下降算法。下一篇会介绍多变量线性回归以及用python实现,并附带简单的实践。